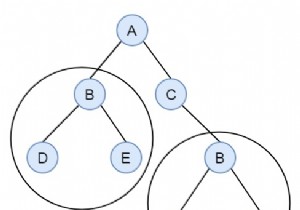
विचार करें कि हमारे पास एक बाइनरी ट्री है। हमें यह पता लगाना है कि पेड़ में कुछ डुप्लिकेट सबट्री हैं या नहीं। मान लीजिए हमारे पास नीचे जैसा एक बाइनरी ट्री है -
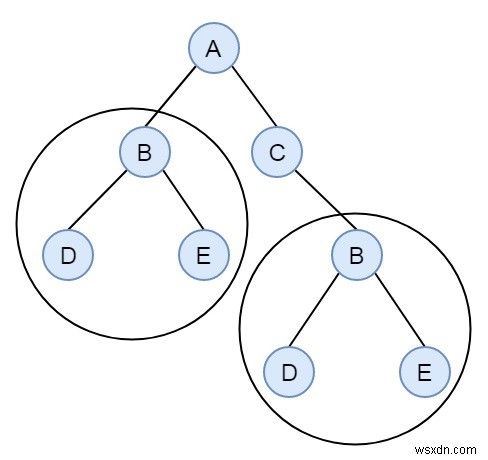
आकार 2 के दो समान सबट्री हैं। प्रत्येक सबट्री में डी, बीडी और बीई दोनों भी डुप्लीकेट सबट्री हैं। हम ट्री सीरियलाइजेशन और हैशिंग प्रक्रिया का उपयोग करके इस समस्या को हल कर सकते हैं। हम हैश टेबल में सबट्री के इनऑर्डर ट्रैवर्सल को स्टोर करेंगे। हम खाली नोड्स के लिए ओपनिंग और क्लोजिंग कोष्ठक सम्मिलित करेंगे।
उदाहरण
#include <iostream>
#include <unordered_set>
#include <unordered_map>
#include <algorithm>
using namespace std;
const char MARKER = '$';
struct Node {
public:
char data;
Node *left, *right;
};
Node* getNode(char key) {
Node* newNode = new Node;
newNode->data = key;
newNode->left = newNode->right = NULL;
return newNode;
}
unordered_set<string> subtrees;
string inorder(Node* node, unordered_map<string, int>& map) {
if (!node)
return "";
string str = "(";
str += inorder(node->left, map);
str += to_string(node->data);
str += inorder(node->right, map);
str += ")";
if (map[str] == 1)
cout << node->data << " ";
map[str]++;
return str;
}
void duplicateSubtreeFind(Node *root) {
unordered_map<string, int> map;
inorder(root, map);
}
int main() {
Node *root = getNode('A');
root->left = getNode('B');
root->right = getNode('C');
root->left->left = getNode('D');
root->left->right = getNode('E');
root->right->right = getNode('B');
root->right->right->right = getNode('E');
root->right->right->left= getNode('D');
duplicateSubtreeFind(root);
} आउटपुट
D E B