बीके ट्री या बर्कहार्ड ट्री एक डेटा संरचना का एक रूप है जो आमतौर पर लेवेनशेटिन दूरी के आधार पर वर्तनी जांच करने के लिए उपयोग किया जाता है। इसका उपयोग स्ट्रिंग मिलान के लिए भी किया जाता है स्वत:सुधार सुविधा का उपयोग इस डेटा संरचना को बनाने के लिए किया जा सकता है। मान लीजिए कि हमारे पास एक शब्दकोश में कुछ शब्द हैं और हमें वर्तनी की त्रुटियों के लिए कुछ अन्य शब्दों की जांच करने की आवश्यकता है। हमारे पास ऐसे शब्दों का संग्रह होना चाहिए जो दिए गए शब्द के करीब हों जिनकी वर्तनी की जाँच की जानी है। उदाहरण के लिए, यदि हमारे पास "uck" शब्द है, तो सही शब्द हो सकता है (ट्रक, बतख, बतख, चूसना)। इसलिए वर्तनी की गलतियों को किसी शब्द को हटाकर या एक उपयुक्त अक्षर के स्थान पर एक नया शब्द जोड़कर सुधारा जा सकता है। एक पैरामीटर के रूप में संपादन दूरी का उपयोग करना और शब्दकोश के साथ वर्तनी की जांच करना।
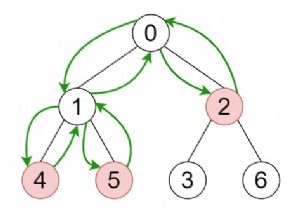
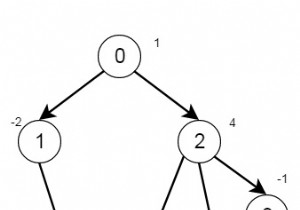
अन्य सभी पेड़ों की तरह, बीके ट्री में भी नोड्स और किनारे होते हैं नोड्स एक शब्दकोश में शब्दों का प्रतिनिधित्व करते हैं किनारे में कुछ पूर्णांक भार होते हैं जो हमें एक नोड से दूसरे नोड में संपादन दूरी के बारे में जानकारी देते हैं।
शब्दों के साथ एक शब्दकोश पर विचार करें {पुस्तक, किताबें, बू, केक, केप} -
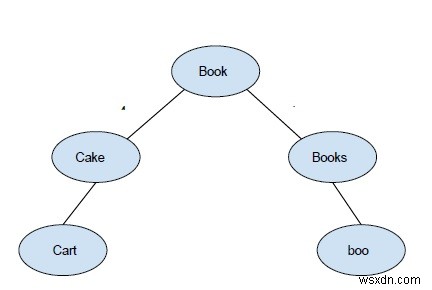
बीके ट्री
बीके ट्री में प्रत्येक नोट में समान संपादन दूरी के साथ ठीक एक चाइल्ड नोड है। यदि हम नोड्स डालने के दौरान संपादन दूरी में कुछ टकराव का सामना करते हैं, तो हम सही बच्चा प्राप्त होने तक सम्मिलन प्रक्रिया का प्रचार करेंगे। प्रत्येक सम्मिलन रूट नोड से शुरू होता है रूट नोड कोई भी शब्द हो सकता है। अब तक हमने सीखा कि बीके ट्री क्या है। अब देखते हैं कि सही निकटतम शब्द कैसे खोजा जाए। सबसे पहले, हमें सहिष्णुता मूल्य निर्धारित करने की आवश्यकता है यह सहिष्णुता मूल्य मेरे गलत वर्तनी वाले शब्द और सही शब्द के बीच अधिकतम संपादन दूरी के अलावा और कुछ नहीं है।
सहिष्णुता सीमा के भीतर योग्य सही शब्द खोजने के लिए हम पुनरावृत्ति की प्रक्रिया का उपयोग करते हैं। लेकिन इसकी एक उच्च जटिलता है इसलिए अब बीके ट्री काम में आता है क्योंकि हम जानते हैं कि बाइनरी ट्री में प्रत्येक नोड का निर्माण माता-पिता से इसकी संपादन दूरी के आधार पर किया जाता है। तो हम सीधे रूट नोड से उस विशिष्ट नोड तक जा सकते हैं जो सहिष्णुता सीमा के भीतर है। यदि टीओएल सहिष्णुता सीमा है और गलत वर्तनी वाले नोड से वर्तमान नोड की दूरी संपादित करें दूर है। तो अब, हम केवल उन्हीं बच्चों को पुनरावृति करेंगे जिनकी सीमा में संपादन दूरी है।
[dist - TOL, dist+TOL], इससे जटिलता काफी हद तक कम हो जाती है।
उदाहरण
कार्य को स्पष्ट करने के लिए कार्यक्रम -
#include "bits/stdc++.h"
using namespace std;
#define MAXN 100
#define TOL 2
#define LEN 10
struct Node {
string word;
int next[2*LEN];
Node(string x):word(x){
for(int i=0; i<2*LEN; i++)
next[i] = 0;
}
Node() {}
};
Node RT;
Node tree[MAXN];
int ptr;
int min(int a, int b, int c) {
return min(a, min(b, c));
}
int editDistance(string& a,string& b) {
int m = a.length(), n = b.length();
int dp[m+1][n+1];
for (int i=0; i<=m; i++)
dp[i][0] = i;
for (int j=0; j<=n; j++)
dp[0][j] = j;
for (int i=1; i<=m; i++) {
for (int j=1; j<=n; j++) {
if (a[i-1] != b[j-1])
dp[i][j] = min( 1 + dp[i-1][j], 1 + dp[i][j-1], 1 + dp[i-1][j-1] );
else
dp[i][j] = dp[i-1][j-1];
}
}
return dp[m][n];
}
void insertValue(Node& root,Node& curr) {
if (root.word == "" ){
root = curr;
return;
}
int dist = editDistance(curr.word,root.word);
if (tree[root.next[dist]].word == ""){
ptr++;
tree[ptr] = curr;
root.next[dist] = ptr;
}
else{
insertValue(tree[root.next[dist]],curr);
}
}
vector <string> findCorrectSuggestions(Node& root,string& s){
vector <string> corrections;
if (root.word == "")
return corrections;
int dist = editDistance(root.word,s);
if (dist <= TOL) corrections.push_back(root.word);
int start = dist - TOL;
if (start < 0)
start = 1;
while (start < dist + TOL){
vector <string> temp = findCorrectSuggestions(tree[root.next[start]],s);
for (auto i : temp)
corrections.push_back(i);
start++;
}
return corrections;
}
int main(){
string dictionary[] = {"book","cake","cart","books", "boo" };
ptr = 0;
int size = sizeof(dictionary)/sizeof(string);
for(int i=0; i<size; i++){
Node tmp = Node(dictionary[i]);
insertValue(RT,tmp);
}
string word1 = "ok";
string word2 = "ke";
vector <string> match = findCorrectSuggestions(RT,word1);
cout<<"Correct words suggestions from dictionary for : "<<word1<<endl;
for (auto correctWords : match)
cout<<correctWords<<endl;
match = findCorrectSuggestions(RT,word2);
cout<<"Correct words suggestions from dictionary for : "<<word2<<endl;
for (auto correctWords : match)
cout<<correctWords<<endl;
return 0;
} आउटपुट
Correct words suggestions from dictionary for : ok book boo Correct words suggestions from dictionary for : ke cake