इस लेख में, मैं एक सामान्य वेब उपयोग के मामले के लिए तीन सर्वर रहित डेटाबेस DynamoDB, FaunaDB, Upstash (Redis) की विलंबता की तुलना करूँगा।
मैंने एक नमूना समाचार वेबसाइट बनाई है और मैं वेबसाइट से प्रत्येक अनुरोध के साथ डेटाबेस से संबंधित विलंबता रिकॉर्ड कर रहा हूं। वेबसाइट और स्रोत कोड की जाँच करें।
मैंने प्रत्येक डेटाबेस में 7001 NY टाइम्स लेख सम्मिलित किए हैं। लेख न्यूयॉर्क टाइम्स आर्काइव एपीआई (जनवरी 2021 के सभी लेख) से एकत्र किए गए हैं। मैंने प्रत्येक लेख को बेतरतीब ढंग से स्कोर किया। प्रत्येक पृष्ठ अनुरोध पर, मैं World . के अंतर्गत शीर्ष 10 लेखों की क्वेरी करता हूं प्रत्येक डेटाबेस से अनुभाग।
मैं प्रत्येक डेटाबेस से लेख लोड करने के लिए सर्वर रहित फ़ंक्शन (एडब्ल्यूएस लैम्ब्डा) का उपयोग करता हूं। लैम्ब्डा फ़ंक्शन के अंदर 10 लेख लाने का प्रतिक्रिया समय विलंबता के रूप में दर्ज किया जा रहा है। ध्यान दें कि रिकॉर्ड की गई विलंबता केवल लैम्ब्डा फ़ंक्शन और डेटाबेस के बीच है। यह आपके ब्राउज़र और सर्वर के बीच विलंबता नहीं है।
प्रत्येक पढ़ने के अनुरोध के बाद, मैं गतिशील डेटा को अनुकरण करने के लिए स्कोर को यादृच्छिक रूप से अपडेट करता हूं। लेकिन मैं इस भाग को विलंबता गणना से बाहर करता हूं।
पहले हम आवेदन की जांच करेंगे, फिर हम परिणाम देखेंगे:
AWS लैम्ब्डा सेटअप
क्षेत्र:यूएस-वेस्ट-1
मेमोरी:1024एमबी
रनटाइम:nodejs14.x
DynamoDB सेटअप
मैंने पढ़ने और लिखने की क्षमता 50 (डिफ़ॉल्ट मान 5 था) के साथ US-West-1 में एक DynamoDB तालिका बनाई।
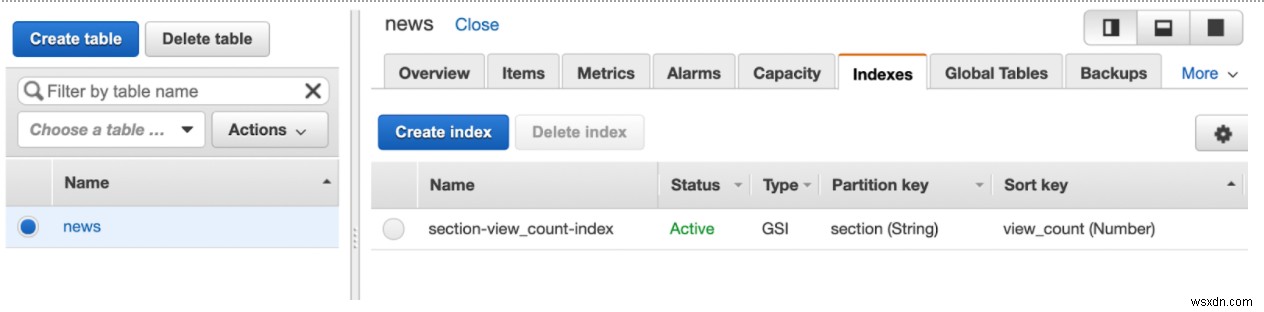
मेरी अनुक्रमणिका GSI है जिसमें विभाजन कुंजी section (String) . है और कुंजी को सॉर्ट करें view_count (Number) ।
FaunaDB सेटअप
FaunaDB एक विश्व स्तर पर दोहराया गया डेटाबेस है, afaik किसी क्षेत्र का चयन करने का कोई तरीका नहीं है। मैंने एफक्यूएल का इस्तेमाल किया, यह मानते हुए कि ग्राफक्यूएल एपीआई में कुछ ओवरहेड हो सकता है।
मैंने शर्तों के साथ एक अनुक्रमणिका बनाई है और मान नीचे दिए गए हैं। मैंने प्रदर्शन में सुधार की उम्मीद में इसे गैर-धारावाहिक बनाया है।
CreateIndex({
name: "section_by_view_count",
unique: false,
serialized: false,
source: Collection("news"),
terms: [
{ field: ["data", "section"] }
],
values: [
{ field: ["data", "view_count"], reverse: true },
{ field: ["ref"] }
]
})
Redis सेटअप
मैंने Upstash में US-West-1 क्षेत्र में एक मानक प्रकार का डेटाबेस बनाया। मैंने प्रत्येक समाचार श्रेणी के लिए एक क्रमबद्ध सेट का उपयोग किया। तो सभी World समाचार लेख कुंजी World . के साथ सॉर्ट किए गए सेट में होंगे ।
डेटाबेस प्रारंभ करें
मैंने NYTimes API साइट से JSON फ़ाइल के रूप में 7001 समाचार लेख डाउनलोड किए, फिर प्रत्येक डेटाबेस के लिए एक NodeJS स्क्रिप्ट बनाई जो JSON को पढ़ती है और डेटाबेस में समाचार रिकॉर्ड सम्मिलित करती है। फ़ाइलें देखें:initDynamo.js, initFauna.js, initRedis.js
क्वेरी DynamoDB
मैंने डायनेमोडीबी से कनेक्ट करने के लिए एडब्ल्यूएस एसडीके का इस्तेमाल किया। विलंबता को कम करने के लिए, मैं DynamoDB कनेक्शन को जीवित रख रहा हूं। मैंने perf_hooks . का उपयोग किया है प्रतिक्रिया समय मापने के लिए पुस्तकालय। मैं शीर्ष 10 लेखों के लिए DynamoDB को क्वेरी करने से ठीक पहले वर्तमान समय रिकॉर्ड करता हूं। डायनेमोडीबी से प्रतिक्रिया मिलते ही मैंने विलंबता की गणना की। फिर मैं बेतरतीब ढंग से लेखों को स्कोर करता हूं और विलंबता संख्या को रेडिस सॉर्ट किए गए सेट में सम्मिलित करता हूं लेकिन ये भाग विलंबता गणना भाग के बाहर हैं। नीचे दिया गया कोड देखें:
var AWS = require("aws-sdk");
AWS.config.update({
region: "us-west-1",
});
const https = require("https");
const agent = new https.Agent({
keepAlive: true,
maxSockets: Infinity,
});
AWS.config.update({
httpOptions: {
agent,
},
});
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const tableName = "news";
var params = {
TableName: tableName,
IndexName: "section-view_count-index",
KeyConditionExpression: "#sect = :section",
ExpressionAttributeNames: {
"#sect": "section",
},
ExpressionAttributeValues: {
":section": process.env.SECTION,
},
Limit: 10,
ScanIndexForward: false,
};
const docClient = new AWS.DynamoDB.DocumentClient();
module.exports.load = (event, context, callback) => {
let start = performance.now();
docClient.query(params, (err, result) => {
if (err) {
console.error(
"Unable to scan the table. Error JSON:",
JSON.stringify(err, null, 2)
);
} else {
// response is ready so we can set the latency
let latency = performance.now() - start;
let response = {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: result,
}),
};
// we are setting random score to top-10 items to simulate real time dynamic data
result.Items.forEach((item) => {
let view_count = Math.floor(Math.random() * 1000);
var params2 = {
TableName: tableName,
Key: {
id: item.id,
},
UpdateExpression: "set view_count = :r",
ExpressionAttributeValues: {
":r": view_count,
},
};
docClient.update(params2, function (err, data) {
if (err) {
console.error(
"Unable to update item. Error JSON:",
JSON.stringify(err, null, 2)
);
}
});
});
// pushing the latency to the histogram
const client = new Redis(process.env.LATENCY_REDIS_URL);
client.lpush("histogram-dynamo", latency, (resp) => {
client.quit();
callback(null, response);
});
}
});
};
क्वेरी FaunaDB
मैंने faunadb . का उपयोग किया है FaunaDB को जोड़ने और क्वेरी करने के लिए पुस्तकालय। शेष भाग DynamoDB कोड के समान है। विलंबता को कम करने के लिए, मैं कनेक्शन को जीवित रख रहा हूं। मैंने perf_hooks . का उपयोग किया है प्रतिक्रिया समय मापने के लिए पुस्तकालय। मैं शीर्ष 10 लेखों के लिए FaunaDB को क्वेरी करने से ठीक पहले वर्तमान समय रिकॉर्ड करता हूं। जैसे ही मुझे FaunaDB से प्रतिक्रिया मिली, मैंने विलंबता की गणना की। फिर मैं बेतरतीब ढंग से लेखों को स्कोर करता हूं और विलंबता संख्या को रेडिस सॉर्ट किए गए सेट पर भेजता हूं लेकिन ये भाग विलंबता गणना भाग के बाहर हैं। नीचे दिया गया कोड देखें:
const faunadb = require("faunadb");
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const q = faunadb.query;
const client = new faunadb.Client({
secret: process.env.FAUNA_SECRET,
keepAlive: true,
});
const section = process.env.SECTION;
module.exports.load = async (event) => {
let start = performance.now();
let ret = await client
.query(
// the below is Fauna API for "select from news where section = 'world' order by view_count limit 10"
q.Map(
q.Paginate(q.Match(q.Index("section_by_view_count"), section), {
size: 10,
}),
q.Lambda(["view_count", "X"], q.Get(q.Var("X")))
)
)
.catch((err) => console.error("Error: %s", err));
console.log(ret);
// response is ready so we can set the latency
let latency = performance.now() - start;
const rclient = new Redis(process.env.LATENCY_REDIS_URL);
await rclient.lpush("histogram-fauna", latency);
await rclient.quit();
let result = [];
for (let i = 0; i < ret.data.length; i++) {
result.push(ret.data[i].data);
}
// we are setting random scores to top-10 items asynchronously to simulate real time dynamic data
ret.data.forEach((item) => {
let view_count = Math.floor(Math.random() * 1000);
client
.query(
q.Update(q.Ref(q.Collection("news"), item["ref"].id), {
data: { view_count },
})
)
.catch((err) => console.error("Error: %s", err));
});
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: {
Items: result,
},
}),
};
};
क्वेरी रेडिस
मैंने ioredis . का इस्तेमाल किया Upstash में Redis से कनेक्ट करने और पढ़ने के लिए लाइब्रेरी। मैंने सॉर्ट किए गए सेट से डेटा लोड करने के लिए ZREVRANGE कमांड का उपयोग किया। विलंबता को कम करने के लिए, मैंने फ़ंक्शन के बाहर Redis क्लाइंट बनाने वाले कनेक्शन का पुन:उपयोग किया। डायनेमोडीबी और फॉनाडीबी के समान, मैं स्कोर अपडेट कर रहा हूं और हिस्टोग्राम गणना के लिए किसी अन्य रेडिस डीबी को लेटेंसी नंबर भेज रहा हूं। कोड देखें:
const Redis = require("ioredis");
const { performance } = require("perf_hooks");
const client = new Redis(process.env.REDIS_URL);
module.exports.load = async (event) => {
let section = process.env.SECTION;
let start = performance.now();
let data = await client.zrevrange(section, 0, 9);
let items = [];
for (let i = 0; i < data.length; i++) {
items.push(JSON.parse(data[i]));
}
// response is ready so we can set the latency
let latency = performance.now() - start;
// we are setting random scores to top-10 items to simulate real time dynamic data
for (let i = 0; i < data.length; i++) {
let view_count = Math.floor(Math.random() * 1000);
await client.zadd(section, view_count, data[i]);
}
// await client.quit();
// pushing the latency to the histogram
const client2 = new Redis(process.env.LATENCY_REDIS_URL);
await client2.lpush("histogram-redis", latency);
await client2.quit();
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify({
latency: latency,
data: {
Items: items,
},
}),
};
};
हिस्टोग्राम गणना
मैंने hdr-histogram-js का उपयोग किया है हिस्टोग्राम की गणना के लिए पुस्तकालय। यह गिल टेने की एचडीआर-हिस्टोग्राम लाइब्रेरी का जेएस कार्यान्वयन है। लैम्ब्डा फ़ंक्शन का कोड देखें जो विलंबता संख्या प्राप्त करता है और हिस्टोग्राम की गणना करता है।
const Redis = require("ioredis");
const hdr = require("hdr-histogram-js");
module.exports.load = async (event) => {
const client = new Redis(process.env.LATENCY_REDIS_URL);
let dataRedis = await client.lrange("histogram-redis", 0, 10000);
let dataDynamo = await client.lrange("histogram-dynamo", 0, 10000);
let dataFauna = await client.lrange("histogram-fauna", 0, 10000);
const hredis = hdr.build();
const hdynamo = hdr.build();
const hfauna = hdr.build();
dataRedis.forEach((item) => {
hredis.recordValue(item);
});
dataDynamo.forEach((item) => {
hdynamo.recordValue(item);
});
dataFauna.forEach((item) => {
hfauna.recordValue(item);
});
await client.quit();
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Credentials": true,
},
body: JSON.stringify(
{
redis_min: hredis.minNonZeroValue,
dynamo_min: hdynamo.minNonZeroValue,
fauna_min: hfauna.minNonZeroValue,
redis_mean: hredis.mean,
dynamo_mean: hdynamo.mean,
fauna_mean: hfauna.mean,
redis_histogram: hredis,
dynamo_histogram: hdynamo,
fauna_histogram: hfauna,
},
null,
2
),
};
};
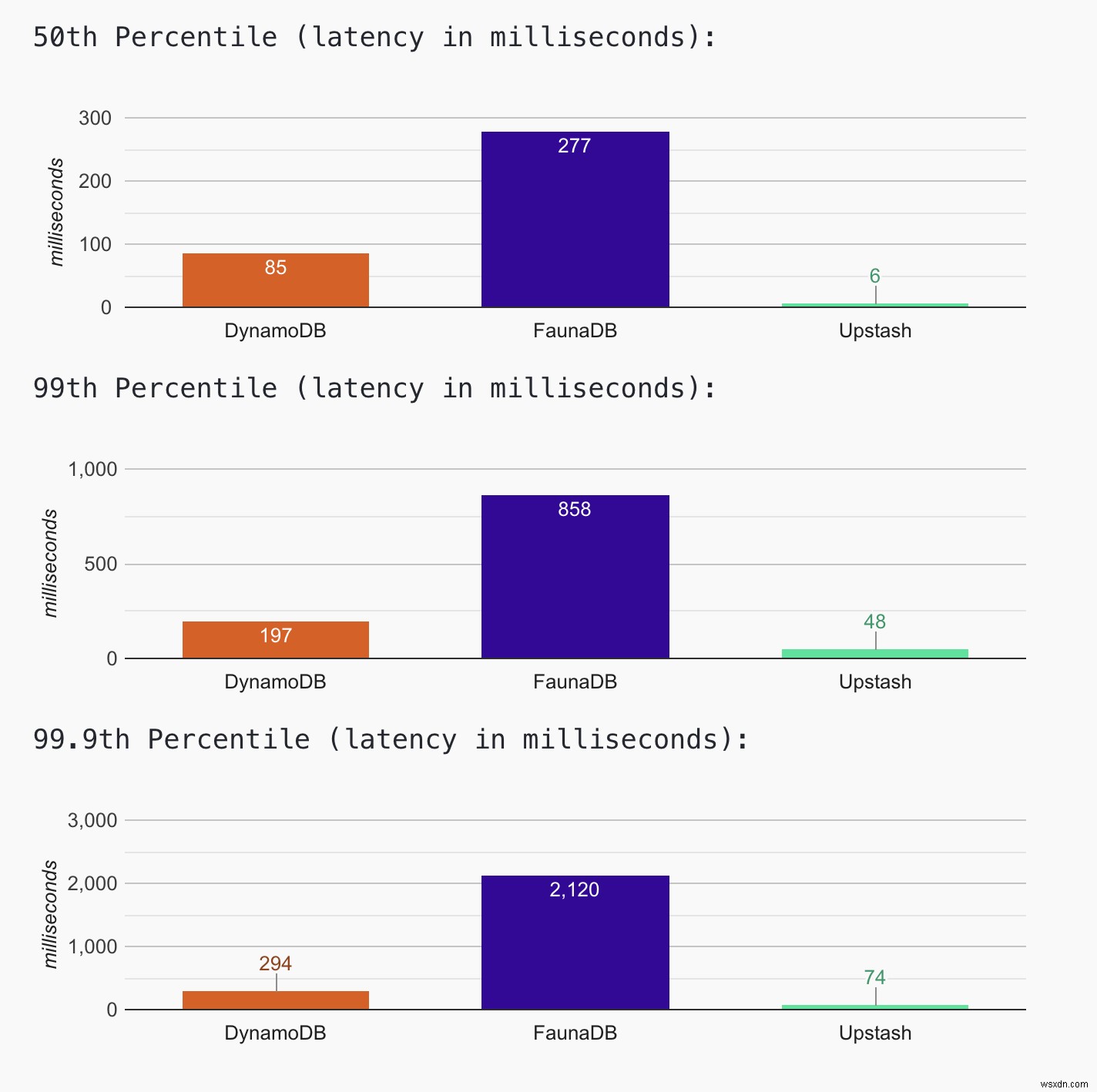
परिणाम
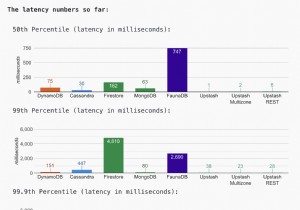
नवीनतम परिणामों के लिए वेबसाइट देखें। आप नवीनतम हिस्टोग्राम डेटा तक भी पहुंच सकते हैं। जब तक वेबसाइट चालू है और चल रही है, हम डेटा एकत्र करना और हिस्टोग्राम को अपडेट करना जारी रखेंगे। आज के परिणाम (अप्रैल, 12, 2021) से पता चलता है कि Upstash में सबसे कम विलंबता (~ 50ms पर 99वें प्रतिशत) है, जहां FaunaDB में उच्चतम विलंबता (~900वें प्रतिशत पर 900ms) है। DynamoDB में (~200ms 99वें पर्सेंटाइल पर)
कोल्ड स्टार्ट इफेक्ट
हालाँकि हम केवल क्वेरी भाग के लिए विलंबता को मापते हैं, फिर भी कोल्ड स्टार्ट का प्रभाव पड़ता है। हम क्लाइंट कनेक्शन का पुन:उपयोग करके अपना कोड अनुकूलित करते हैं। जब तक लैम्ब्डा कंटेनर गर्म और चल रहा है, तब तक हमें इसका फायदा होता है। जब एडब्ल्यूएस कंटेनर (कोल्ड स्टार्ट) को मारता है, तो कोड क्लाइंट को फिर से बनाता है, यह एक ओवरहेड है। एप्लिकेशन वेबसाइट में, यदि आप पेज को रीफ्रेश करते हैं; आप देखेंगे कि Upstash के लिए विलंबता संख्या घटकर ~1ms हो गई है; और डायनेमोडीबी के लिए ~7ms।
FaunaDB धीमा क्यों है (इस बेंचमार्क में)?
FaunaDB के स्टेटस पेज में, आप सैकड़ों में लेटेंसी नंबर देखेंगे। तो मुझे लगता है कि मेरे विन्यास में बड़ी खामियां नहीं हैं। इस विलंबता अंतर के पीछे दो कारण हो सकते हैं:
मजबूत स्थिरता: डिफ़ॉल्ट रूप से, DynamoDB और Upstash दोनों ही पढ़ने के लिए अंतिम स्थिरता प्रदान करते हैं। FaunaDB केल्विन आधारित मजबूत स्थिरता और अलगाव प्रदान करता है। प्रदर्शन ओवरहेड के साथ मजबूत स्थिरता आती है।
वैश्विक प्रतिकृति: Upstash और DynamoDB दोनों के लिए, हम डेटाबेस और लैम्ब्डा फ़ंक्शन को एक ही AWS क्षेत्र में कॉन्फ़िगर करने में सक्षम हैं। FaunaDB में, आपका डेटा दुनिया भर में दोहराया जाता है; इसलिए आपके पास अपना क्षेत्र चुनने का विकल्प नहीं है। यदि आपके डेटाबेस क्लाइंट दुनिया भर में स्थित हैं तो यह एक फायदा हो सकता है। लेकिन अगर आप अपने बैकएंड को किसी विशिष्ट क्षेत्र में तैनात करते हैं, तो यह अतिरिक्त विलंबता का कारण बनता है।
Redis सब मिलीसेकंड लेटेंसी देता है। यहाँ ऐसा क्यों नहीं है?
एडब्ल्यूएस लैम्ब्डा फ़ंक्शन में एक नया रेडिस कनेक्शन बनाना एक उल्लेखनीय ओवरहेड का कारण बनता है। चूंकि एप्लिकेशन को स्थिर ट्रैफ़िक नहीं मिलता है, इसलिए AWS लैम्ब्डा ज्यादातर समय कनेक्शन (कोल्ड स्टार्ट) को फिर से बनाता है। तो हिस्टोग्राम में अधिकांश विलंबता संख्या में कनेक्शन निर्माण समय शामिल है। हम एक नौकरी चलाते हैं जो हर 15 सेकंड में वेबसाइट लाती है; हमने देखा कि Upstash के लिए लेटेंसी घटकर ~1ms हो गई है। यदि आप पृष्ठ को रीफ्रेश करते हैं, तो आपको एक समान प्रभाव दिखाई देगा। कम विलंबता के लिए अपने सर्वर रहित अनुप्रयोगों को अनुकूलित करने के तरीके के लिए हमारी ब्लॉग पोस्ट देखें।
जल्द आ रहा है
Upstash जल्द ही प्रीमियम उत्पाद जारी करेगा जहां डेटा को कई उपलब्धता क्षेत्रों में दोहराया जाता है। मैं इसे क्षेत्र प्रतिकृति के प्रभाव को देखने के लिए जोड़ूंगा।
हमें Twitter या Discord पर अपनी प्रतिक्रिया दें।
अपडेट करें
HackerNews पर मेरे बेंचमार्क और फॉना के प्रदर्शन के बारे में सक्रिय चर्चा हुई। मैंने सुझावों को लागू किया और FaunaDB एप्लिकेशन को पुनः आरंभ किया। इसलिए, हिस्टोग्राम में FaunaDB रिकॉर्ड की संख्या दूसरों की तुलना में कम है।