हाल के वर्षों में, सर्वर रहित आर्किटेक्चर और एज कंप्यूटिंग अनुप्रयोग परिनियोजन के लिए बहुत लोकप्रिय हो रहे हैं। लेकिन एप्लिकेशन स्टेट और सर्वर रहित और/या एज फ़ंक्शन के अंदर डेटा संग्रहीत करना एक अलग कहानी है। कई कठिनाइयाँ हैं जैसे; डेटाबेस से कनेक्शन का प्रबंधन, कई स्थानों से डेटा को तेज़ एक्सेस के लिए उपलब्ध कराना आदि। सर्वर रहित एक्सेस का समर्थन करने वाली केवल कुछ डेटाबेस सेवाएँ हैं और उनमें से बहुत कम एज फ़ंक्शंस के लिए भी उपयुक्त हैं। (आप एक विस्तृत विश्लेषण यहाँ पढ़ सकते हैं। )
अपस्टैश में, पहले दिन से, हम कम विलंबता के लिए और प्रति-अनुरोध मूल्य निर्धारण मॉडल के साथ एक सर्वर रहित रेडिस संगत डेटाबेस प्रदान कर रहे हैं। इसके अतिरिक्त हम सीधे डेटाबेस पर निर्मित प्रथम श्रेणी के आरईएसटी एपीआई का पर्दाफाश करते हैं। आरईएसटी एपीआई कनेक्शन प्रबंधन की परेशानी को दूर करता है, खासकर जब सर्वर रहित कार्यों में उपयोग किया जाता है, लेकिन किनारे के स्थानों या वेब ब्राउज़र जैसे प्रतिबंधित वातावरण से भी पहुंच योग्य होता है।
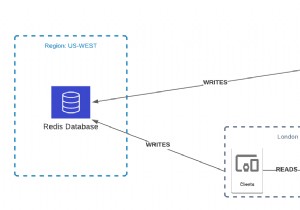
आज हमें ग्लोबल डेटाबेस की घोषणा करते हुए खुशी हो रही है, जो डेटाबेस को वैश्विक स्तर पर उपलब्ध कराने की दिशा में एक कदम आगे है, कम लेटेंसी रीडिंग के लिए क्लाइंट्स और एज लोकेशन के करीब है। वैश्विक डेटाबेस निःशुल्क स्तर पर उपलब्ध है, आप इसे बिना किसी लागत के आज़मा सकते हैं ।
कब का उपयोग करें?
एक वैश्विक डेटाबेस विभिन्न महाद्वीपों पर कई क्षेत्रों में तैनात किया गया है और क्लाइंट अनुरोधों को निकटतम क्षेत्र में भेज दिया जाता है ताकि दुनिया भर में उपयोगकर्ताओं को वितरित किए जाने पर विलंबता को कम किया जा सके। Upstash Global डेटाबेस का उपयोग इसके लिए किया जा सकता है;
-
एज फंक्शन्स (क्लाउडफ्लेयर वर्कर्स, फास्टली कंप्यूट):बिल्ट-इन रेस्ट एपीआई और सभी किनारे के स्थानों से कम लेटेंसी एक्सेस इसे एक सही समाधान बनाता है।
-
बहु-क्षेत्र सर्वर रहित परिनियोजन:AWS लैम्ब्डा, वर्सेल और नेटलिफाई फ़ंक्शन को कई क्षेत्रों में तैनात किया जा सकता है। आपके सर्वर रहित कार्य कहीं भी हों, एक वैश्विक डेटाबेस कम विलंबता डेटा प्रदान करता है।
-
वेब/मोबाइल प्लेटफॉर्म:केवल पढ़ने के लिए आरईएसटी एपीआई का उपयोग करके, आप रेडिस डेटाबेस को सीधे वेब/मोबाइल एप्लिकेशन तक पहुंच सकते हैं। एक वैश्विक डेटाबेस बेहतर विलंबता प्रदान करेगा जैसा कि आप कहीं से भी उपयोगकर्ताओं से अपेक्षा कर सकते हैं।
वैश्विक डेटाबेस के पीछे एक अन्य लक्ष्य डेटाबेस को क्षेत्र की व्यापक विफलताओं के लिए लचीला बनाना है। जब कोई क्षेत्र उपलब्ध नहीं होता है, तो आपके अनुरोध निकटतम उपलब्ध क्षेत्र में भेज दिए जाते हैं; ताकि आपका डेटाबेस उपलब्ध रहे।
यह कैसे काम करता है?
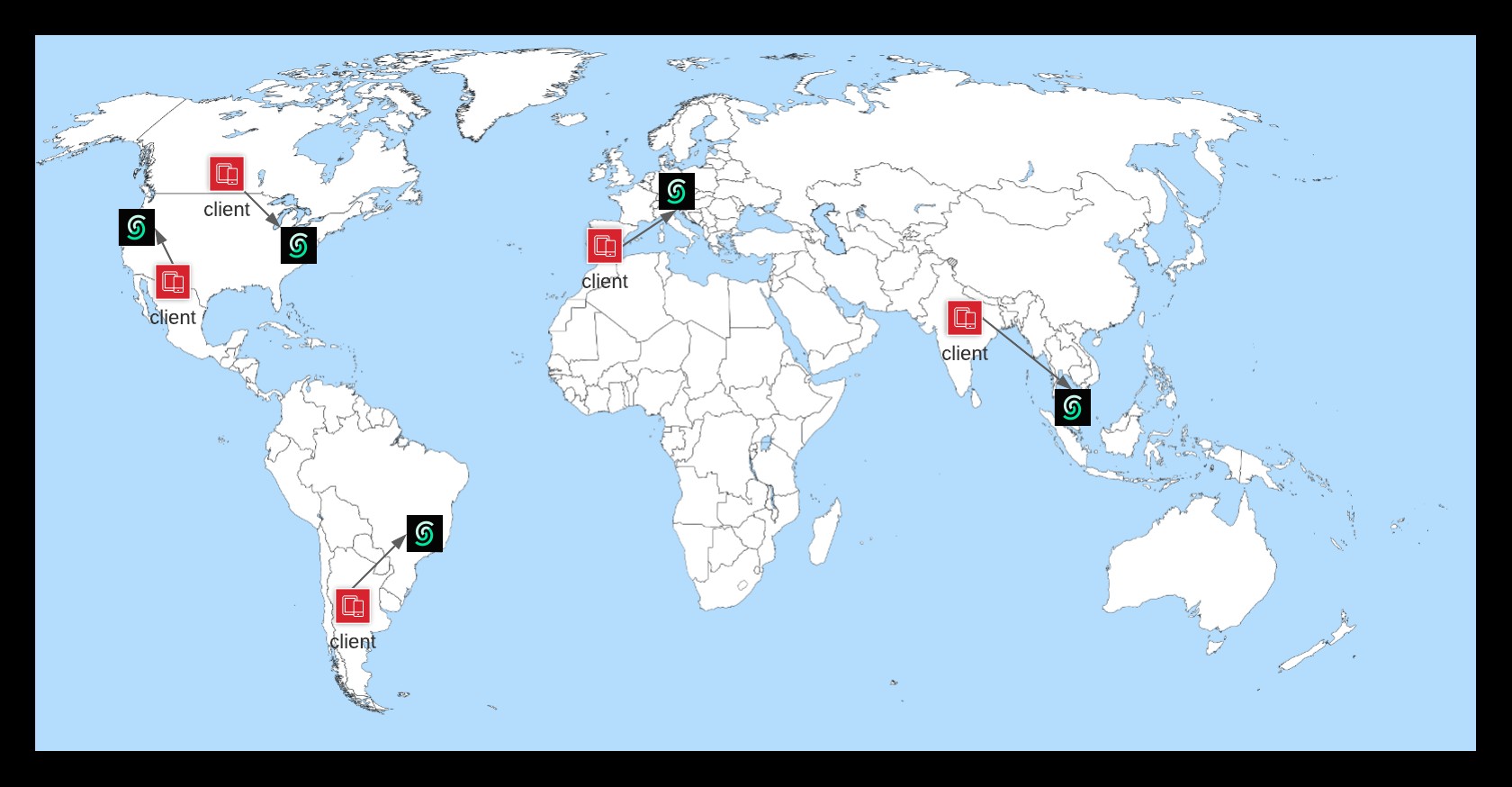
वैश्विक डेटाबेस मॉडल में, एक ही डेटाबेस के कई प्रतिरूप होते हैं और वे एक साथ एक क्लस्टर बनाते हैं। प्रत्येक प्रतिकृति अन्य क्लस्टर सदस्यों से जुड़ी होती है और विफलता डिटेक्टर का उपयोग करके उनमें से प्रत्येक की जीवंतता को ट्रैक करती है। क्लस्टर सदस्यता और विफलता का पता लगाने दोनों को गपशप आधारित संचार प्रोटोकॉल का उपयोग करके प्रबंधित किया जाता है। (स्विम देखें:स्केलेबल कमजोर-संगत संक्रमण-शैली प्रक्रिया समूह सदस्यता प्रोटोकॉल।)
डेटा को दोहराने के लिए (अधिक विशेष रूप से, व्यक्तिगत रूप से लिखता/अपडेट/हटाता है), एकल नेता प्रतिकृति मॉडल का उपयोग किया जाता है। चाबियों का एक समूह एक नेता प्रतिकृति को सौंपा जाता है, जिसे सदस्यता परिवर्तन के बाद एक नेता चुनाव तंत्र का उपयोग करके चुना जाता है। शेष प्रतिकृतियां चाबियों के उस समूह के लिए उस नेता का बैकअप बन जाती हैं। जब नेता प्रतिकृति को विफलता डिटेक्टर द्वारा विफल पाया जाता है, तो शेष प्रतिकृतियां एक नया नेता चुनाव दौर शुरू करती हैं और एक नए नेता का चुनाव करती हैं। चुनाव प्रक्रिया के दौरान, डेटाबेस अनुपलब्ध हो जाता है थोड़े समय के लिए और चुनाव पूरा होने तक सभी अनुरोधों को अवरुद्ध कर दिया जाएगा।
केवल लीडर रेप्लिका ही राइट रिक्वेस्ट को स्वीकार और प्रोसेस करती है, बैकअप रेप्लिकाएं क्लाइंट को सूचित किए बिना लीडर को आंतरिक रूप से फॉरवर्ड करती हैं। इसलिए रेप्लिका प्रकार, लीडर या बैकअप की परवाह किए बिना, क्लाइंट एक लिखित अनुरोध भेज सकता है। लिखने के अनुरोध को संसाधित करने के बाद, नेता प्रतिकृति इसे बैकअप प्रतिकृतियों के लिए प्रचारित करती है।
एकरूपता पर अधिक
वर्तमान में, वैश्विक डेटाबेस कमजोर रूप से संगत हैं, वे अभी तक मजबूत स्थिरता का समर्थन नहीं करते हैं। अधिकांश बैकअप से एसीके की प्रतीक्षा किए बिना, लीडर प्रतिकृति ऑपरेशन को संसाधित करने के बाद क्लाइंट को लिखित अनुरोध का जवाब वापस कर दिया जाता है। लेखन का परिणाम समानांतर में समकालिक रूप से बैकअप प्रतिकृति में दोहराया जाता है।
रीड रिक्वेस्ट किसी भी रेप्लिका द्वारा प्रोसेस की जाती हैं, जो बेहतर रीड स्केलेबिलिटी देता है, लेकिन इसका मतलब यह भी है कि रीड रिक्वेस्ट एक बासी वैल्यू लौटा सकती है, जब तक कि उसी की के लिए राइट ऑपरेशन का परिणाम बैकअप रेप्लिका तक नहीं पहुंच जाता।
विरोधों के बिना आसान होगा!
नेटवर्क विभाजन जैसे क्लस्टर व्यापक विफलता के मामले में, एक ही कुंजी के लिए कई नेताओं को चुना जा सकता है। इसका मतलब है कि कई प्रतिकृतियां अलग-अलग प्रतिकृतियों पर अलग-अलग लिखने और डेटा को स्वीकार करने के लिए स्वीकार करती हैं। केल्विन या स्पैनर (या शायद पैक्सोस, राफ्ट) जैसे प्रोटोकॉल का उपयोग करके एक मजबूत मॉडल के साथ शुरुआत में होने वाले संघर्षों को रोकना संभव होगा, लेकिन यह एक अलग रास्ता है जिसे हम इस समय नहीं लेना चाहते हैं।
इसके बजाय, ग्लोबल डेटाबेस संघर्षों को होने देता है और एक LWW (अंतिम-लेखन-जीत) का उपयोग करके उनका समाधान करता है ) एल्गोरिथम और प्रतिकृतियों को अंततः उसी स्थिति में परिवर्तित करें। Upstash डेटाबेस में प्रत्येक लेखन में एक अद्वितीय, मोनोटोनिक अनुक्रम संख्या होती है। हर बार जब एक प्रतिकृति नेता बन जाती है, तो यह पहली लेखन प्रक्रियाओं के अनुक्रम को चिह्नित करती है। जब दो नेता प्रतिरूप एक-दूसरे को खोजते हैं, तो वे नेता बनने के बाद अपने लेखन को साझा करते हैं, और वे अपने संघर्षों को सुलझाते हैं।
सभी प्रतिकृतियां समान नहीं हैं
कुछ प्रतिकृतियां दूसरों की तुलना में अधिक समान हैं। क्योंकि उनमें से कुछ ही नेता चुने जा सकते हैं। एक वैश्विक डेटाबेस क्लस्टर में, एक प्रतिकृति को शिक्षार्थी . के रूप में चिह्नित किया जा सकता है , जो इसे नेता चुनाव के लिए अनुपयुक्त बनाता है। शिक्षार्थी प्रतिकृतियां हमेशा पढ़ने के लिए बनी रहती हैं और नेतृत्व के लिए उम्मीदवार नहीं हो सकतीं।
शिक्षार्थी प्रतिकृतियों को जोड़ने से क्लस्टर की स्थिरता प्रभावित नहीं होती है और जब वे अलग हो जाते हैं तो वे लिखने के विरोध का कारण नहीं बन सकते। यहां तक कि जब वे नेता से अलग हो जाते हैं, तब भी वे पढ़ने के अनुरोधों की अनुमति देना जारी रखते हैं और विभाजन के ठीक होने के बाद शेष लेखन को सिंक करते हैं। इसलिए शिक्षार्थी प्रतिकृतियां हमारे लिए अधिक किनारे वाले स्थानों का विस्तार करने के लिए एक बहुत अच्छी उपयोगिता हैं।
अधिक क्षेत्र, अधिक प्रतिकृतियां?
अपनी प्रारंभिक रिलीज़ में, हम पाँच प्रतिकृतियों और पाँच क्षेत्रों में ग्लोबल डेटाबेस की पेशकश कर रहे हैं। और यूएस और ईयू के बाहर की प्रतिकृतियों को शिक्षार्थी . के रूप में चिह्नित किया गया है s, इसलिए केवल यूएस और यूरोपीय संघ के क्षेत्रों में प्रतिकृतियों को नेताओं के रूप में चुना जा सकता है। यह नेटवर्क विभाजन के दौरान लेखन-संघर्ष की संभावना को कम करता है। लेकिन हमें नेटवर्क विभाजन के बारे में चिंता किए बिना सीखने वाले प्रतिकृतियों के रूप में और क्षेत्रों को जोड़ने की अनुमति देता है।
अभी भी जाना बाकी है
वर्तमान में वैश्विक डेटाबेस केवल पढ़ने के संचालन की विलंबता को अनुकूलित/न्यूनतम करने के लिए डिज़ाइन किए गए हैं। वे लिखने-भारी भार के लिए उपयुक्त नहीं हैं। हम बेहतर डिजाइन के साथ लेखन कार्यों के लिए विलंबता को बेहतर बनाने के लिए भी काम कर रहे हैं।
शुरुआती पांच क्षेत्र सेटअप के अलावा, हम अपने उपयोगकर्ताओं की मांग और प्रतिक्रिया के कारण भविष्य में और अधिक क्षेत्रों और/या विभिन्न क्षेत्र समूहों को खोलने पर विचार कर रहे हैं।
आप अपने विचारों/विचारों और अपने प्रश्नों को साझा करने के लिए Twitter और Discord पर हमसे संपर्क कर सकते हैं।