आज हमें रेडिसग्राफ 2.8 की सामान्य उपलब्धता रिलीज की घोषणा करते हुए खुशी हो रही है। यह ब्लॉग पोस्ट अब उपलब्ध प्रमुख नई सुविधाओं का विवरण देता है।
RedisGraph के बारे में
RedisGraph, Redis के लिए एक उच्च-प्रदर्शन, मेमोरी-प्रथम ग्राफ़ डेटा संरचना है। RedisGraph ग्राफ़ मल्टी-टेनेंसी का समर्थन करता है (यह एक साथ कई ग्राफ़ रख सकता है) और एक साथ ग्राफ़ तक पहुँचने वाले कई क्लाइंट की सेवा कर सकता है। यह अब रेडिस स्टैक के हिस्से के रूप में भी उपलब्ध है।
RedisGraph 2.8 में प्रमुख नई सुविधाएं
- अमीर ग्राफ मॉडल
- मल्टी-लेबल नोड्स
- उन्नत पूछताछ क्षमताएं
- उन्नत पूर्ण-पाठ खोज
- अधिक साइफर निर्माणों, कार्यों और ऑपरेटरों का समर्थन करना
- प्रदर्शन में सुधार
- संबंध गुणों पर अनुक्रमणिका
- डेल्टा मैट्रिसेस
- नियंत्रणीय नोड निर्माण बफर
- बेंचमार्क
https://redis.com/blog/redisgraph-2-8-is-generally-available/(एक नए टैब में खुलता है)
अमीर ग्राफ मॉडल
मल्टी-लेबल नोड
लेबल किए गए संपत्ति ग्राफ़ (एलपीजी) डेटा मॉडल की कई परिभाषाएं (उदा. प्रॉपर्टी ग्राफ़ डेटाबेस मॉडल - कोण, 2018 , और ISO/IEC JTC 1/SC 32 - GQL ड्राफ्ट) निर्दिष्ट करते हैं कि एक नोड में कई लेबल हो सकते हैं। v2.8 तक, RedisGraph केवल एक लेबल का समर्थन करता था। अभी तक, हम बिना किसी प्रदर्शन में गिरावट या महत्वपूर्ण स्मृति वृद्धि के प्रत्येक नोड में कई लेबल जोड़ सकते हैं।
एकाधिक लेबल के साथ एक नोड बनाने के लिए, आप बस एक कोलन द्वारा अलग किए गए सभी लेबल सूचीबद्ध करते हैं:
GRAPH.QUERY g "CREATE (e:Employee:BoardMember {Name: 'Vincent Chan', Title: 'Web marketing lead'}) return e"
एक से अधिक लेबल (AND शर्त) के साथ एक नोड का मिलान करने के लिए, आपको उसी कोलन नोटेशन का भी उपयोग करना चाहिए:
GRAPH.QUERY g "MATCH (e:Employee:BoardMember) return e"
उन्नत क्वेरी करने की क्षमता
उन्नत पूर्ण-पाठ खोज
RedisGraph RedisSearch के साथ एम्बेडेड आता है और द्वितीयक अनुक्रमण के लिए लीवरेज किया जाता है, लेकिन इसका उपयोग उन्नत अनुक्रमण और खोज के लिए भी किया जा सकता है। उदाहरण के लिए - पृथ्वी पर किसी दिए गए बिंदु से भौगोलिक निकटता के आधार पर नोड्स ढूंढना, या संबंधित वस्तुओं को अधिक स्कोर करना।
संस्करण 2.8 भाषा और स्टॉपवर्ड कॉन्फ़िगरेशन विकल्प जोड़ता है। भाषा परिभाषित करती है कि टेक्स्ट को स्टेम करने के लिए किस भाषा का उपयोग करना है - जो किसी शब्द के आधार रूप को इंडेक्स में जोड़ रहा है। यह "गोइंग" के लिए क्वेरी को "गो" और "गोन" के परिणाम भी लौटाने की अनुमति देता है, उदाहरण के लिए। स्टॉपवर्ड बहुत ही सामान्य शब्द हैं (जैसे "है, द, ए, और…") जो खोज में अधिक जानकारी नहीं जोड़ते हैं लेकिन अनुक्रमणिका में बहुत अधिक स्थान लेते हैं। खोज करते समय इन शब्दों को अनुक्रमित और अनदेखा नहीं किया जाता है। एक क्वेरी शब्द जिसमें स्टॉपवर्ड होगा, जैसे "इन पेरिस" को केवल "पेरिस" के रूप में देखा जाएगा।
जर्मन भाषा का उपयोग करके और मूवी लेबल के साथ सभी नोड्स के कस्टम स्टॉपवर्ड का उपयोग करके फिल्मों की शीर्षक संपत्ति पर एक पूर्ण-पाठ अनुक्रमणिका बनाने के लिए:
GRAPH.QUERY DEMO_GRAPH "CALL db.idx.fulltext.createNodeIndex({ label: 'Movie', language: 'German', stopwords: ['a', 'ab'] }, 'title')"
RediSearch 3 अतिरिक्त फ़ील्ड कॉन्फ़िगरेशन विकल्प प्रदान करता है:
- वजन - क्षेत्र में पाठ का महत्व
- नोस्टेम - टेक्स्ट को इंडेक्स करते समय स्टेमिंग छोड़ें
- ध्वन्यात्मक - पाठ पर ध्वन्यात्मक खोज सक्षम करें
मूवी लेबल वाले सभी नोड्स की ध्वन्यात्मक खोज के साथ शीर्षक संपत्ति पर एक पूर्ण-पाठ अनुक्रमणिका बनाने के लिए:
GRAPH.QUERY DEMO_GRAPH "CALL db.idx.fulltext.createNodeIndex('Movie', {field: 'title', phonetic: 'dm:en'})"
अधिक साइफर निर्माण, कार्यों और ऑपरेटरों का समर्थन करना
RedisGraph 2.8 विस्तारित साइफर समर्थन कवरेज:
- पैटर्न की समझ
allShortestPaths
. के लिए समर्थन जोड़ें समारोह- साइफर फ़ंक्शन:
keys, reduce, replace, none,
औरsingle
- नोड एट्रिब्यूट-सेट को
SET
में कॉपी करना खंड - नोड लेबल द्वारा
WHERE
. में फ़िल्टर करना खंड - साइफर ऑपरेटर:
XOR
और^
पैटर्न की समझ
पैटर्न समझ साइफर में उपलब्ध एक वाक्य रचनात्मक निर्माण है। जबकि सूची समझ हमें मौजूदा सूचियों के आधार पर एक सूची बनाने की अनुमति देती है, पैटर्न समझ एक पैटर्न के मिलान के परिणामों के साथ एक सूची को पॉप्युलेट करने का एक तरीका है। यह मानक
MATCH. के अनुसार निर्दिष्ट पैटर्न से मेल खाएगा क्लॉज, विधेय के साथ एक मानक
WHERE. के रूप में खंड, लेकिन एक निर्दिष्ट प्रक्षेपण उपज।
उदाहरण के लिए, निम्न क्वेरी पुरुष कर्मचारियों द्वारा प्राप्त सभी अनुदान प्रकारों वाली एक सूची लौटाएगी जहां अनुदान राशि $1000 से अधिक थी।
GRAPH.QUERY g "CREATE (e:Employee {gender:'Male'})-[:granted]->(g:Grant {type: 'Research', amount: 2000})"
GRAPH.QUERY g "MATCH (e:Employee {gender:'Male'}) RETURN [(e)-[:granted]->(g:Grant) WHERE g.amount > 1000 | g.type] AS grantTypes"
इसके लिए समर्थन जोड़ें सभी लघुतम पथ फ़ंक्शन
allShortestPathsफ़ंक्शन सभी मानदंडों से मेल खाने वाली संस्थाओं की एक जोड़ी के बीच सभी सबसे छोटे पथ देता है। दोनों संस्थाओं को पहले के
WITH. में बाध्य होना चाहिए -सीमांकित दायरा।
GRAPH.QUERY DEMO_GRAPH "MATCH (c:Actor {name: 'Charlie Sheen'}), (k:Actor {name: 'Kevin Bacon'}) WITH c, k MATCH p = allShortestPaths((c)-[:PLAYED_WITH*]->(k)) RETURN nodes(p) as actors"
यह क्वेरी चार्ली शीन का प्रतिनिधित्व करने वाले अभिनेता नोड को केविन बेकन का प्रतिनिधित्व करने वाले से जोड़ने वाली न्यूनतम लंबाई के सभी पथों का उत्पादन करेगी। दो अभिनेताओं के बीच कई 2-हॉप पथ हैं, और ये सभी वापस आ जाएंगे। पथों की गणना तब समाप्त हो जाती है, क्योंकि हम 2 से अधिक लंबाई के किसी भी पथ में रुचि नहीं रखते हैं।
खोज के लिए न्यूनतम लंबाई (1 होना चाहिए) और अधिकतम लंबाई (कम से कम 1 होनी चाहिए) निर्दिष्ट की जा सकती है। शून्य या अधिक संबंध प्रकार निर्दिष्ट किए जा सकते हैं (उदा.
[:R|Q*1..3]) पैटर्न में कोई भी प्रॉपर्टी फ़िल्टर पेश नहीं किया जा सकता है।
इसके लिए समर्थन जोड़ें कुंजी साइफर फ़ंक्शन
keysफ़ंक्शन एक इनपुट के रूप में एक नोड, एक संबंध, या एक मानचित्र को स्वीकार करता है, और इनपुट में शामिल सभी कुंजियों की एक सरणी देता है।
MATCH (a) RETURN keys(a)
MATCH ()-[e]->() RETURN keys(e)
RETURN keys({a:1, b:2})
इसके लिए समर्थन जोड़ें कम करें साइफर फ़ंक्शन
reduceफ़ंक्शन एक प्रारंभिक मान और एक सूची स्वीकार करता है। यह तब सूची के प्रत्येक तत्व के विरुद्ध एक व्यंजक का मूल्यांकन करके मूल्य को अद्यतन करता है।
GRAPH.QUERY g "RETURN reduce(sum = 0, n IN range(1,10) | sum + n)"
इस फ़ंक्शन का आउटपुट 55 होगा - 1 और 10 के बीच के पूर्णांकों का योग।
GRAPH.QUERY g "RETURN reduce(arr = [], n IN range(1,10) | arr + [n*n])"
इस फ़ंक्शन का आउटपुट 1 और 10 के बीच के पूर्णांकों के वर्गों वाली एक सरणी होगी।
साइफर स्ट्रिंग फ़ंक्शन को बदलने के लिए समर्थन जोड़ें
किसी दिए गए सबस्ट्रिंग की सभी घटनाओं को दूसरे के साथ बदल देता है। फ़ंक्शन को 3 पैरामीटर प्राप्त होते हैं:मूल स्ट्रिंग, बदलने की घटनाएं, और उन्हें किसके साथ बदलना है।
GRAPH.QUERY g "RETURN replace('abc*efg', '*', 'd')" वापसी मूल्य 'abcdefg' होगा।
यह फ़ंक्शन सबस्ट्रिंग को एक खाली स्ट्रिंग ('') से प्रतिस्थापित करके भी हटा सकता है।
इसके लिए समर्थन जोड़ें कोई नहीं और एकल साइफर फ़ंक्शन
किसी सूची को देखते हुए, यदि कोई विधेय किसी तत्व के लिए होल्ड नहीं करता है, तो कोई भी सत्य नहीं लौटाता है, जबकि दिए गए विधेय में केवल एक तत्व के लिए एकल रिटर्न सही होता है।
GRAPH.QUERY g "RETURN none(x IN range(1,10) WHERE x>10)"
GRAPH.QUERY g "RETURN single(x IN range(1,10) WHERE x>9)"
ये फ़ंक्शन सभी और किसी भी फ़ंक्शन के समान हैं।
पथ फ़िल्टरिंग एक संभावित उपयोग मामला है:
graph.query DEMO_GRAPH "MATCH p =(a {name:'Johnny Depp'})-[*2..5]->(b {name:'Kevin Bacon'}) जहां कोई नहीं (n नोड्स में (p) WHERE n.year> 1970) रिटर्न पी”
यह क्वेरी जॉनी डेप से लेकर केविन बेकन तक लंबाई 2 से 5 तक के सभी पथ लौटाएगी, जिसमें 1970 के बाद पैदा हुआ कोई भी अभिनेता शामिल नहीं है।
SET
. में नोड विशेषता सेट की प्रतिलिपि बनाने के लिए समर्थन जोड़ें खंड
SETक्लॉज का उपयोग एक नोड के सभी संपत्ति मूल्यों को दूसरे नोड के संपत्ति मूल्यों के साथ बदलने या जोड़ने के लिए किया जा सकता है।
निम्नलिखित क्वेरी दो संस्थाओं से मेल खाएगी, और फिर सभी गुणों को b के गुणों से बदल देगी:
GRAPH.QUERY g "MATCH (a {v: 1}), (b {v: 2}) SET a = b"
निम्न क्वेरी दो निकायों से मेल खाएगी, और फिर a के गुणों को b के गुणों के साथ जोड़ (या मान बदलें)।
GRAPH.QUERY g "MATCH (a {v: 1}), (b {v: 2}) SET a += b"
हम गुणों को बदले बिना किसी रिश्ते के प्रकार को भी बदल सकते हैं:
GRAPH.QUERY g "MATCH (a)-[b]->(c) WHERE ID(b)=0 CREATE (a)-[d:bar]->(c) SET d=b DELETE b RETURN d"
नोड लेबल द्वारा फ़िल्टर करने के लिए समर्थन जोड़ें कहां खंड
अब WHERE क्लॉज में भी नोड लेबल या रिलेशनशिप टाइप द्वारा फ़िल्टर करना संभव है:
GRAPH.QUERY g "MATCH (a) WHERE a:L RETURN a"
GRAPH.QUERY g "MATCH (a)-[b]-(c) WHERE b:L RETURN b"
साइफर ऑपरेटरों XOR और ^ . के लिए समर्थन जोड़ें
GRAPH.QUERY g "RETURN true XOR true”
GRAPH.QUERY g "RETURN 2 ^ 3”
परिणाम
falseहैं और
8, क्रमशः।
प्रदर्शन सुधार
संबंध गुणों पर अनुक्रमणिका
नोड्स के लिए, हम निम्नलिखित कमांड जारी करके एक इंडेक्स पेश कर सकते हैं
GRAPH.QUERY g "CREATE INDEX FOR (n:GRANTS) ON (n.GrantedBy)"
अब संबंधों के लिए भी अनुक्रमणिका प्रस्तुत करना संभव है:
GRAPH.QUERY g "CREATE INDEX FOR ()-[r:R]-() ON (r.prop)"
निम्नलिखित प्रश्न पर विचार करें:
GRAPH.QUERY g "MATCH (a)-[r:R {prop:5}]-(b) return *"
आइए इंडेक्स बनाने से पहले निष्पादन योजना देखें:
redis:6379> GRAPH.EXPLAIN g "MATCH (a)-[r:R {prop:5}]-(b) return *"
1) "Results" |
और यह इंडेक्स बनाने के बाद उसी क्वेरी के लिए निष्पादन योजना है:
redis:6379> GRAPH.EXPLAIN g "MATCH (a)-[r:R {prop:5}]-(b) return *"
1) "Results" |
डेल्टा मैट्रिसेस
संस्करण 2.8 के बाद से, ग्राफ़ नोड्स और संबंध जोड़ और हटाना बहुत तेज़ हैं, क्योंकि वे पहले छोटे डेल्टा मैट्रिसेस में अपडेट किए जाते हैं। फिर मुख्य मैट्रिसेस को बल्क-अपडेट किया जाता है।
RedisGraph में, ग्राफ़ को आसन्न मैट्रिक्स के साथ दर्शाया जाता है। ग्राफ़ में प्रत्येक नोड लेबल और प्रत्येक संबंध प्रकार का अपना मैट्रिक्स होता है। पहले, हर बार ग्राफ़ में एक नया नोड जोड़ा जाता था, सभी मैट्रिक्स को आकार देने की आवश्यकता होती थी, और डेटाबेस जितना बड़ा होता था, उतना ही अधिक समय लगता था।
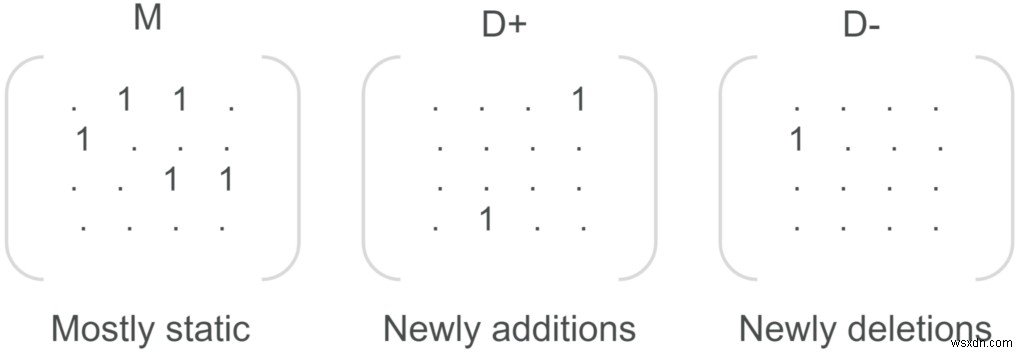
v2.8 के बाद से, नए नोड्स और संबंध सम्मिलित करने में लगने वाला समय काफी कम है और यह अब ग्राफ़ के आकार पर निर्भर नहीं करता है। यह अनुकूलन ग्राफ़ में प्रत्येक मैट्रिक्स के लिए दो डेल्टा मैट्रिसेस को पेश करके प्राप्त किया गया था:एक नोड जोड़ (डी +) के लिए और एक नोड विलोपन (डी-) के लिए। नोड जोड़ना और हटाना उनके उपयुक्त डेल्टा मैट्रिक्स में परिलक्षित होता है, और एक बार डेल्टा मैट्रिक्स 10000 नोड्स की सीमा तक पहुंच जाता है (
DELTA_MAX_PENDING_CHANGESके माध्यम से कॉन्फ़िगर करने योग्य) कॉन्फ़िगरेशन पैरामीटर), यह एक ही बल्क ऑपरेशन में मुख्य मैट्रिक्स के साथ सिंक्रोनाइज़ होता है, खाली हो जाता है, और वही चक्र फिर से शुरू हो सकता है।
नियंत्रणीय नोड निर्माण बफर
एक नया लोड-टाइम कॉन्फ़िगरेशन पैरामीटर, NODE_CREATION_BUFFER, भविष्य के नोड निर्माण के लिए मैट्रिसेस में आरक्षित मेमोरी की मात्रा को नियंत्रित करता है। उदाहरण के लिए, जब 16,384 पर सेट किया जाता है, तो मैट्रिस के निर्माण पर 16384 नोड्स के लिए अतिरिक्त स्थान होगा। जब भी अतिरिक्त स्थान समाप्त होगा, मैट्रिक्स का आकार 16384 तक बढ़ जाएगा।
इस मान को कम करने से मेमोरी की खपत कम हो जाएगी, लेकिन मैट्रिक्स रियललोकेशन की बढ़ी हुई आवृत्ति के कारण प्रदर्शन में गिरावट आएगी। इसके विपरीत, इसे बढ़ाने से लेखन-भारी कार्यभार के प्रदर्शन में सुधार हो सकता है लेकिन स्मृति खपत में वृद्धि होगी।
यदि पारित तर्क 2 की शक्ति नहीं थी, तो इसे स्मृति संरेखण में सुधार करने के लिए 2 की अगली सबसे बड़ी शक्ति में गोल किया जाएगा।
बेंचमार्क
हमने डेल्टा मैट्रिसेस के अलावा कई अन्य प्रदर्शन संवर्द्धन भी जोड़े। हम LDBC SNB बेंचमार्क का उपयोग करके इन सुधारों को नीचे प्रदर्शित करते हैं।
एलडीबीसी एसएनबी (लिंक्ड डेटा बेंचमार्क काउंसिल - सोशल नेटवर्क बेंचमार्क) ग्राफ डेटाबेस की तुलना करने के लिए उद्योग-मानक बेंचमार्क है, वास्तविक दुनिया में वर्कलोड पढ़ता है और लिखता है।
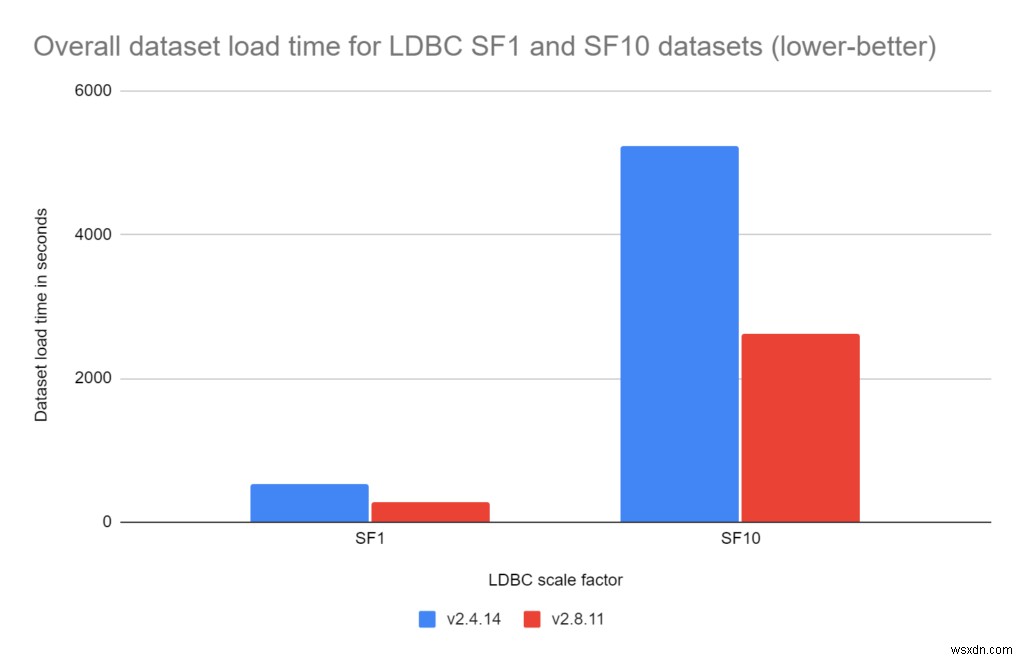
RedisGraph 2.8 में समग्र डेटा लोड बहुत तेज़ है:
- एलडीबीसी स्केल फैक्टर 1:
RedisGraph 2.8 RedisGraph 2.4 . से 1.92 गुना तेज है
- एलडीबीसी स्केल फैक्टर 10:
RedisGraph 2.8, RedisGraph 2.4 से 2.00 गुना तेज है
रेडिसग्राफ 2.8 में एलडीबीसी क्वेरी (पढ़ने और लिखने दोनों) को बहुत तेजी से निष्पादित किया जाता है:
- प्रश्न पढ़ें:
RedisGraph 2,8 RedisGraph 2.4 . से 2.32 गुना तेज है
- प्रश्न लिखें:
RedisGraph 2,8 RedisGraph 2.4 से 1.09 गुना तेज है
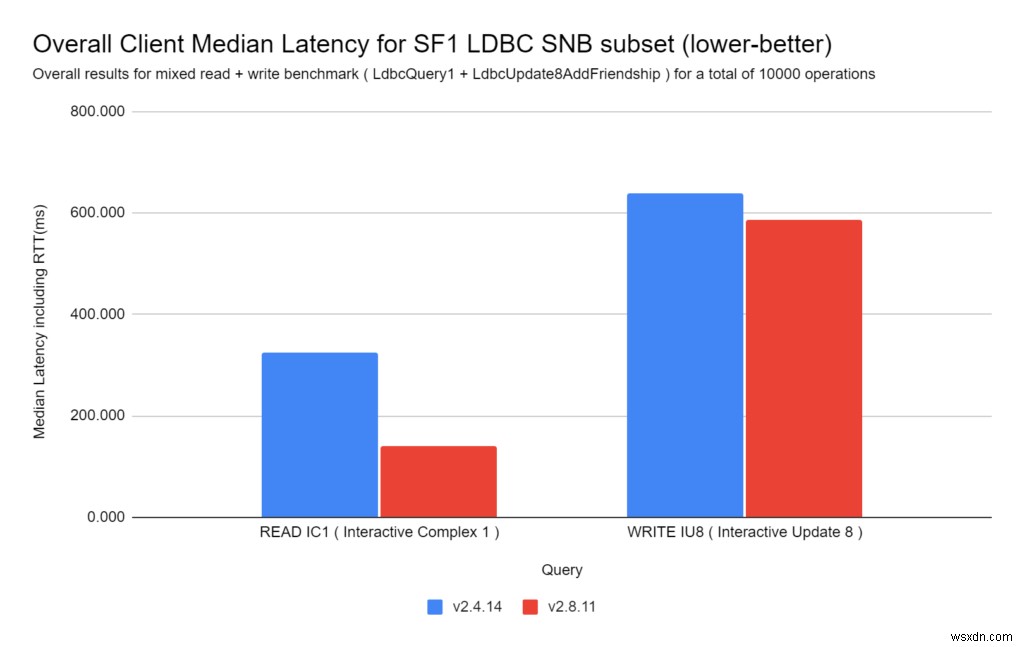
डेटा को पुनर्स्थापित करना और समन्वयित करना (RDB और AOF) भी बहुत तेज़ है (कुछ स्थितियों में परिमाण के कई क्रमों तक)।
RedisGraph, Redis Stack का हिस्सा है
RedisGraph अब Redis Stack का हिस्सा है। आप macOS, Ubuntu, या Redhat के लिए नवीनतम Redis Stack Server बायनेरिज़ डाउनलोड कर सकते हैं या Docker, Homebrew, या Linux के साथ इंस्टॉल कर सकते हैं।
RedisInsight का उपयोग करके RedisGraph का अनुभव करें
RedisInsight डेवलपर्स के लिए एक दृश्य उपकरण है जो Redis या Redis Stack का उपयोग करके विकास के दौरान RedisTimes से डेटा का पता लगाने का एक शानदार तरीका प्रदान करता है।
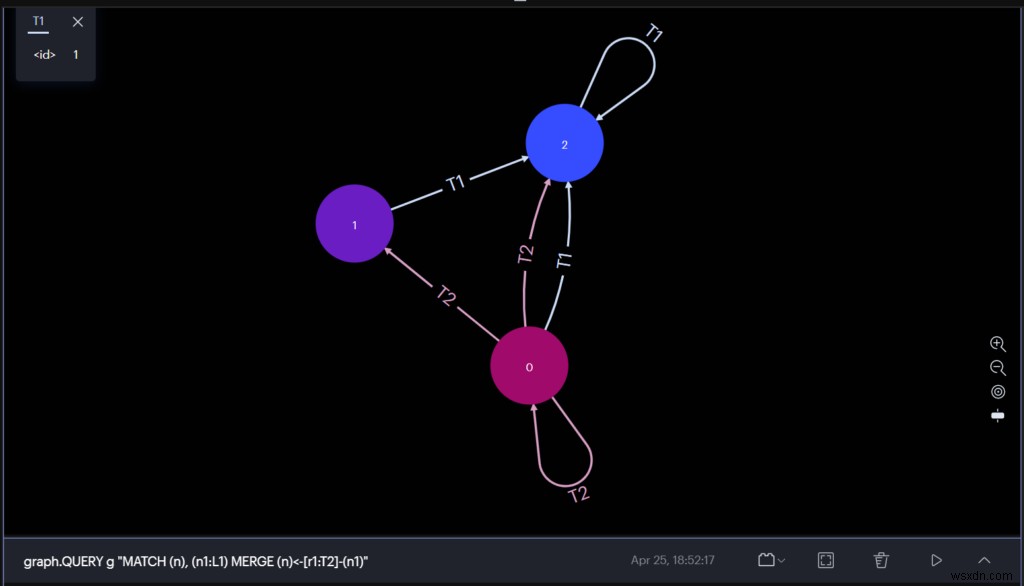
आप ग्राफ प्रश्नों को निष्पादित कर सकते हैं और सीधे ग्राफिकल यूजर इंटरफेस से परिणाम देख सकते हैं। RedisInsight अब RedisGraph क्वेरी परिणामों की कल्पना कर सकता है।
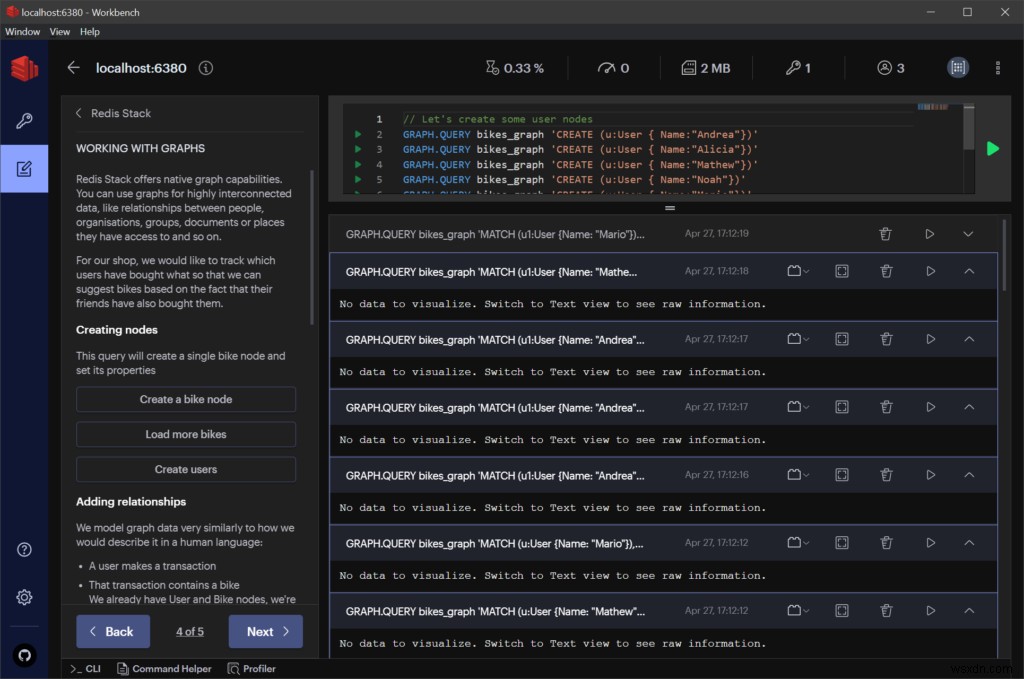
इसके अलावा, RedisInsight में RedisGraph को अंतःक्रियात्मक रूप से सीखने के लिए त्वरित मार्गदर्शिकाएँ और ट्यूटोरियल शामिल हैं।
redis.io और developer.redis.com पर RedisGraph के बारे में और जानें।