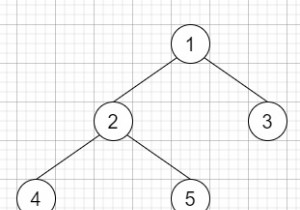
.where जैसे कमांड का उपयोग करके क्वेरी करने और डेटा डालने के लिए एक आसान और तेज़ इंटरफ़ेस प्रदान करता है , .save , .create , और .update . रेल्स इन कमांड्स को SQL क्वेरीज़ में बदलने का काम करता है, जो एक अच्छी बात है, लेकिन कभी-कभी प्रदर्शन संबंधी समस्याएं पैदा हो सकती हैं। यह महत्वपूर्ण है कि आप कुछ सामान्य मुद्दों को समझें और प्रदर्शन को कैसे अनुकूलित करें। रूबी ऑन रेल्स में ActiveRecord पर एक त्वरित नोट
<पी> रेल्स एक्टिवरिकॉर्ड मॉडल-व्यू-कंट्रोलर (एमवीसी) में एक परत है जो आपके डेटाबेस को एक व्यावसायिक ऑब्जेक्ट के रूप में प्रस्तुत करके प्रबंधित करता है। ActiveRecord पैटर्न किसी एप्लिकेशन के ऑब्जेक्ट को रिलेशनल डेटाबेस टेबल प्रबंधन सिस्टम से कनेक्ट करने के लिए ORM तकनीक का उपयोग करता है। <पी> अब, चलिए आगे बढ़ते हैं!रेल में डेटाबेस प्रदर्शन समस्याओं को पहचानने और परीक्षण करने के 3 तरीके
1. ActiveRecord क्वेरीज़ पर एक्सप्लेन चलाएँ
<पी> एक व्याख्या कथन एक SQL क्वेरी के निष्पादन योजना के बारे में जानकारी प्रदर्शित करता है - एक क्वेरी को कैसे निष्पादित किया जाएगा, जिसमें कितनी पंक्तियाँ स्कैन की जाएंगी, किस सूचकांक का उपयोग किया जाएगा, और तालिकाएँ कैसे शामिल होंगी। <पी> निष्पादन योजना हमें निम्न को देखकर यह पता लगाने में मदद करती है कि क्वेरी निष्पादन को धीमा करने वाला कारण क्या है- किसी क्वेरी के प्रदर्शन को बेहतर बनाने के लिए आपको कौन सा इंडेक्स जोड़ना चाहिए।
- यदि तालिकाएँ इष्टतम क्रम में जुड़ी हुई हैं। आप
STRAIGHT_JOINका उपयोग कर सकते हैं बेहतर प्रदर्शन के लिए जॉइन स्टेटमेंट में टेबल ऑर्डर को बाध्य करना।
.explain जोड़ा जा रहा है कमांड के अंत में ActiveRecord कमांड के लिए क्वेरी प्लान प्रदान करता है। उपरोक्त उदाहरण एक बहुत ही सरल क्वेरी है जो id का उपयोग करती है (प्राथमिक कुंजी) तालिका से पूछताछ करने के लिए। explain का आउटपुट कथन से पता चलता है कि यह pkey का उपयोग कर रहा है . इससे, आप निश्चिंत हो सकते हैं कि कथन इष्टतम और तेज़ है। <पी> आप एक .explain जोड़ने का प्रयास कर सकते हैं उपयोग की गई अनुक्रमणिका के साथ-साथ निष्पादन के क्रम को उजागर करने के लिए आपके धीमे प्रश्नों को आदेश दें। यदि क्वेरी योजना Seq Scan दिखाती है , सूचकांक का उपयोग नहीं किया जा रहा है और एक क्वेरी परिवर्तन या एक नया सूचकांक जोड़ने की आवश्यकता है। <पी> यहां शामिल होने का एक और उदाहरण दिया गया है: <पी> यहां, उपयोगकर्ता तालिका को सहयोग तालिका के साथ जोड़ा गया है। जब आप क्वेरी योजना पर गौर करते हैं, तो सहयोग तालिका seq scan का उपयोग कर रही है और पहले निष्पादित कर रहा है - जबकि उपयोगकर्ता तालिका pkey का उपयोग कर रही है अनुक्रमणिका और बाद में क्रियान्वित हो रही है। आप user_id पर एक इंडेक्स जोड़ सकते हैं इस क्वेरी को अनुकूलित करने के लिए सहयोग तालिका में कॉलम। व्याख्या क्वेरी को तोड़ने में मदद करती है, ताकि आप यह पता लगा सकें कि अनुकूलन की आवश्यकता कहाँ है। 2. प्रमुख डेटाबेस मेट्रिक्स को मापें
<पी> यह देखने के लिए कि कोई क्वेरी निष्पादित है या नहीं, क्वेरी समय एकमात्र मीट्रिक नहीं है - कई अन्य डेटाबेस मीट्रिक देखें, जिनमें शामिल हैं:- सीपीयू उपयोग
- मेमोरी उपयोग
- प्रतीक्षारत IO के लिए डिस्क कतार
- इनबाउंड और आउटबाउंड ट्रैफ़िक के लिए नेटवर्क बैंडविड्थ
- उपलब्ध डिस्क स्थान
- थ्रूपुट
- <पी> डेटाबेस प्रकार:
- संबंधपरक
- इन-मेमोरी
- No-SQL
- डेटा-वेयरहाउस
- <पी> सर्वर कैसे होस्ट किया जाता है:
- ऑन-प्रिमाइसेस
- बादल पर
3. AppSignal
का उपयोग करके रेल ऐप के प्रदर्शन को मापें <पी> आपके सभी प्रदर्शन मेट्रिक्स को एक केंद्रीय स्थान के बिना प्रबंधित करना मुश्किल हो सकता है जो आपको सभी प्रश्नों पर दृश्यता प्रदान करता है। प्रत्येक कोड ब्लॉक में प्रदर्शन कोड जोड़ना बोझिल और असहनीय हो सकता है। <पी> ऐपसिग्नल जैसे टूल के साथ, आप आसानी से प्रदर्शन माप को अपने एप्लिकेशन में एकीकृत कर सकते हैं। AppSignal बॉक्स से बाहर रेल का समर्थन करता है। 'AppSignal for Ruby' दस्तावेज़ से सरल AppSignal इंस्टॉलेशन प्रक्रिया के बारे में जानें। <पी> नज़र रखने के लिए कुछ महत्वपूर्ण मीट्रिक हैं:- धीमी क्वेरी
- थ्रूपुट पर आधारित डेटाबेस प्रदर्शन
- एन+1 प्रश्न
- डेटाबेस विलंबता
- सक्रिय कनेक्शन की संख्या
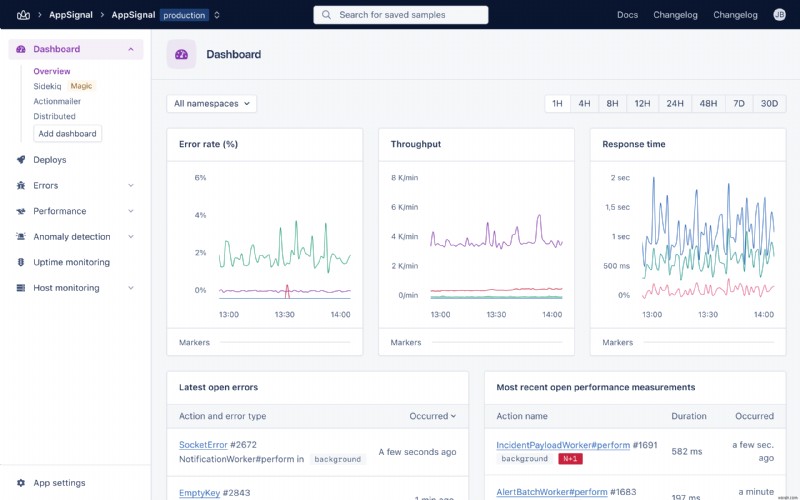
रूबी ऑन रेल्स डेटाबेस प्रदर्शन को अनुकूलित करने के 7 तरीके
1. N+1 क्वेरीज़ के लिए उत्सुक लोडिंग
<पी> N+1 क्वेरीज़ सबसे आम डेटाबेस प्रदर्शन समस्या है। आइएN+1 का एक उदाहरण देखें क्वेरी करें जहां आपके पास दो मॉडल हैं - उपयोगकर्ता और प्रोजेक्ट: <पी> अब, यदि आप उपयोगकर्ता और प्रोजेक्ट नाम ढूंढना चाहते हैं, तो निम्न कोड चलाएँ: <पी> उपरोक्त कोड प्रत्येक लूप के साथ डेटाबेस को क्वेरी करेगा और प्रदर्शन संबंधी समस्याएं पैदा करेगा। निष्पादित क्वेरीज़ की कुल संख्या उपयोगकर्ताओं की संख्या + 1 होगी। <पी> इस समस्या को दूर करना बहुत सरल है:एसोसिएशन को उत्सुकता से लोड करें। बस .includes(:projects) जोड़ें क्वेरी के अंत में: <पी> अब, लूप को निष्पादित करने से डेटाबेस से पूछताछ नहीं की जाएगी, क्योंकि ऊपर दी गई क्वेरी उत्सुकता से परियोजनाओं को लोड करती है: <पी> रेल्स 6.1 यह सुनिश्चित करने के लिए सख्त लोडिंग प्रदान करता है कि एसोसिएशन तक पहुंचने से पहले उत्सुकता से लोड किया गया है। सख्त लोडिंग सक्षम करने के लिए, मॉडल में निम्नलिखित पंक्ति जोड़ें: <पी> अब, जब आप उत्सुकतापूर्वक लोड किए बिना परियोजनाओं तक पहुंचने का प्रयास करेंगे, तो रेल एक ActiveRecord::StrictLoadingViolationError फेंक देगा अपवाद. <पी> यदि आपके पास रेल्स 6.1 नहीं है, तो आप बुलेट जैसे रत्नों का उपयोग कर सकते हैं। 2. डेटाबेस इंडेक्स
का उपयोग करें <पी> डेटाबेस तेजी से डेटा पुनर्प्राप्त करने में सहायता के लिए इंडेक्स प्रदान करते हैं। व्याख्या कमांड का उपयोग करके जिसे हमने पहले कवर किया था, आप यह पता लगाने में सक्षम होंगे कि कोई क्वेरी उचित इंडेक्स का उपयोग कर रही है या नहीं। <पी> आप पहले से मौजूद इंडेक्स या अतिरिक्त इंडेक्स का उपयोग करने के लिए धीमी क्वेरी को बदल सकते हैं जो प्रदर्शन को बेहतर बनाने में मदद करता है। <पी> MySQL में चार अलग-अलग प्रकार के इंडेक्स हैं:- प्राथमिक कुंजी - सूचकांक स्वचालित रूप से प्राथमिक कुंजी में जुड़ जाता है, जो यह भी सुनिश्चित करता है कि यह अद्वितीय है
- अद्वितीय - अद्वितीय कुंजी सूचकांक यह सुनिश्चित करता है कि किसी विशेषता में जोड़े गए आइटम हमेशा अद्वितीय हों
- सूचकांक - प्राथमिक कुंजी के अलावा अन्य विशेषताओं में जोड़ा गया
- पूर्ण पाठ - वर्ण-आधारित डेटा के विरुद्ध क्वेरी करने में मदद करता है
"abc" में बहुत सारे उपयोगकर्ता हो सकते हैं और देश क्षेत्र को स्कैन किया जाएगा। बड़े परिणाम डेटासेट के कारण यह धीमी प्रक्रिया हो सकती है। इस मामले में, आप प्रदर्शन को बेहतर बनाने के लिए प्रोजेक्ट और देश दोनों फ़ील्ड में एक समग्र सूचकांक जोड़ सकते हैं। <पी> आप निम्नलिखित ActiveRecord माइग्रेशन कमांड के साथ इंडेक्स को रेल्स में जोड़ सकते हैं: <पी> एकल सूचकांक: <पी> समग्र सूचकांक: 3. सीमाओं का उपयोग करें
<पी> जितने अधिक रिकॉर्ड लौटाए जाएंगे, प्रदर्शन उतना ही धीमा हो सकता है। एक बड़ी डेटा सेट लौटाने वाली एकल क्वेरी की तुलना में एकाधिक क्वेरी करना बेहतर है। <पी> अगले 100 बैच लाने के लिए, आप ऑफ़सेट का उपयोग कर सकते हैं: <पी> इससे प्रदर्शन में उल्लेखनीय सुधार होगा. ध्यान रखने योग्य एक बात यह है कि अधिक ऑफसेट के साथ, क्वेरी धीमी हो जाती है। ऑफसेट में एक सीमा जोड़ें।4. find_each का प्रयोग करें बड़ी संख्या में आइटम लोड करने के लिए
<पी> रिकॉर्ड्स पर पुनरावृत्ति करते समय, बेहतर प्रदर्शन के लिए उन्हें रेल में बैच करें: <पी> यह डेटाबेस में सभी रिकॉर्ड को एक बार क्वेरी कर देगा और मेमोरी और डेटाबेस प्रदर्शन संबंधी समस्याएं पैदा करेगा। <पी> find_each का उपयोग करना या find_in_batches एक बैच में एक ही ऑपरेशन करके प्रदर्शन को बेहतर बनाने में मदद मिलेगी: <पी> डिफ़ॉल्ट रूप से, find_each प्रश्नों का परिणाम 1,000 का बैच होता है। आप इसे एक तर्क के रूप में परिभाषित करके बैच आकार बदल सकते हैं: <पी> आप find_in_batches का भी उपयोग कर सकते हैं आपके द्वारा किए जाने वाले ऑपरेशन के आधार पर। find_in_batches के बीच अंतर और find_each क्या वह find_in_batches है परिणाम व्यक्तिगत रिकॉर्ड के बजाय मॉडलों की एक श्रृंखला के रूप में प्राप्त होता है। 5. प्लक
का उपयोग करके अपना आवश्यक फ़ील्ड चुनें <पी> प्लक कमांड किसी क्वेरी के परिणाम को ActiveRecord ऑब्जेक्ट के बजाय सीधे एक सरणी में परिवर्तित करता है। <पी> यदि कोई क्वेरी बड़े परिणाम देती है, तो प्लक का उपयोग करने से कोड प्रदर्शन में सुधार होगा। प्लक डेटाबेस से केवल एक आवश्यक फ़ील्ड का चयन करेगा: <पी> परिणाम मुख्य तालिका से नहीं, बल्कि एक सूचकांक से प्राप्त किया जाता है, और विभिन्न प्रकार से संबंधित प्रश्नों के साथ यह अधिक प्रभावी होता है।6. थोक परिचालन का उपयोग करें
<पी> बल्क हटाएं ActiveRecord ऑब्जेक्ट पर लूपिंग डिलीट ऑपरेशन एक समय में एक रिकॉर्ड हटा देगा: <पी> प्रत्येक रिकॉर्ड को हटाने के लिए डेटाबेस में कई क्वेरीज़ करने की आवश्यकता होती है। इसके बजाय, एकल बल्कdelete_all का उपयोग करना इष्टतम है क्वेरी: <पी> थोक निर्माण कुछ लोगों को यह एहसास नहीं है कि बल्क डिलीट के समान, आप ActiveRecord के साथ बल्क इंसर्ट भी कर सकते हैं। इससे n को कम किया जा सकता है केवल एक के लिए प्रश्नों की संख्या। ActiveRecord::Base create विधि इनपुट के रूप में हैश की एक सरणी स्वीकार करती है: 7. यदि आवश्यक हो तो इन-मेमोरी गणना का उपयोग करें
<पी> कुछ उदाहरणों में, क्वेरी करने की तुलना में इन-मेमोरी गणना बेहतर होती है। मान लीजिए कि हम अपने डेटाबेस में उन देशों को ढूंढना चाहते हैं जिनके पास उपयोगकर्ताओं का रिकॉर्ड नहीं है: <पी> उपरोक्त क्वेरी के परिणाम प्राप्त करने के लिए N क्वेरी की आवश्यकता है। इसके बजाय, हम दिए गए देशों में उपयोगकर्ताओं को ढूंढने के लिए एक क्वेरी लिख सकते हैं और मेमोरी में अन्य गणना कर सकते हैं: <पी> आप अनुरोध-प्रतिक्रिया चक्र का पुन:उपयोग करने और कुछ मामलों में डेटाबेस लोड को कम करने के लिए कैश कर सकते हैं। रेल तीन प्रकार की कैशिंग तकनीकें प्रदान करती है:पेज, एक्शन और फ्रैगमेंट कैशिंग (फ्रैगमेंट कैशिंग डिफ़ॉल्ट रूप से पेश की जाती है)।रैप अप:ActiveRecord और AppSignal के साथ अपने रूबी ऑन रेल्स प्रदर्शन को अनुकूलित करें
<पी> ठीक है, पुनर्कथन करने का समय! इस पोस्ट में, हमने रेल्स में डेटाबेस प्रदर्शन समस्याओं की पहचान और परीक्षण करने के तीन तरीकों को शामिल किया है:- ActiveRecord क्वेरीज़ पर एक्सप्लेन चलाना
- प्रमुख डेटाबेस मेट्रिक्स को मापना
- AppSignal का उपयोग करके रेल ऐप के प्रदर्शन को मापना
- एन+1 प्रश्नों के लिए उत्सुक लोडिंग
- एक डेटाबेस इंडेक्स
- सीमाएं
find_eachबड़ी संख्या में आइटम लोड करने के लिए- आवश्यक फ़ील्ड का चयन करने के लिए प्लक करें
- बल्क ऑपरेशन
- इन-मेमोरी गणना