डेटाबेस वृद्धि को नियंत्रित करें:टेबल का आकार छोटा रखने और डेटा ब्लोट से बचने की रणनीतियाँ
<पी> अधिकांश वेब एप्लिकेशन किसी प्रकार के डेटा स्टोर का उपयोग करते हैं, अक्सर एक रिलेशनल डेटाबेस। जब कोई वेब ऐप सफल हो जाता है, तो डेटाबेस में डेटा "जमा करना" शुरू करना बहुत आसान हो जाता है। लेकिन डेटा जमा करने से डेटाबेस तालिकाओं (पंक्ति गणना और संग्रहीत डेटा आकार दोनों) की असीमित वृद्धि होती है। <पी> हालांकि यह एक निश्चित बिंदु तक ठीक काम करता है, यह कुछ डेटा ब्लॉट को रोकने के लिए बहुत उपयोगी है - या, यदि आप इसे रोक नहीं सकते हैं, तो विकास को पर्याप्त रूप से प्रबंधित करने के लिए समय से पहले अपने बुनियादी ढांचे की योजना बनाएं। <पी> इससे पहले कि हम आगे बढ़ें, आइए देखें कि हम फूले हुए अनुप्रयोगों के साथ कैसे समाप्त हो सकते हैं। अधिक डेटा हमेशा अच्छा नहीं होता
<पी> हम जिन अनुप्रयोगों पर काम करते हैं उनमें से अधिकांश समय के साथ बड़े होते जाते हैं। <पी> यदि आप अपने डेटाबेस के लिए क्लाउड प्रदाता का उपयोग करते हैं, तो आप अपनी आवंटित भंडारण सीमा तक पहुंच सकते हैं। एक बार ऐसा होने पर, आपको एक अलग इंस्टेंस प्रकार में अपग्रेड करने की आवश्यकता होगी। हेरोकू पोस्टग्रेएसक्यूएल डेटाबेस की एक सीमा होती है, उदाहरण के लिए, एक "हॉबी" स्तरीय उदाहरण 1GB डेटा तक सीमित है। <पी> अधिक डेटा होने से क्वेरी गति पर भी प्रभाव पड़ता है। जो पहले किसी सूचकांक के बिना संभव होता था वह बड़ी तालिकाओं के साथ असंभव हो जाता है। कुछ पंक्ति श्रेणी स्कैन धीमे हो जाएंगे. डेटाबेस UPDATE करने के लिए अधिक ताले प्राप्त किए जाएंगे और DELETE परिचालन. डेटाबेस टेबल्स कैसे बढ़ते हैं
<पी> डेटा जमाखोरी धीरे-धीरे होती है। जो आज समस्या नहीं है वह आसानी से एक महीने या छह महीने में समस्या बन सकती है। डेटा जमाखोरी के बारे में सबसे विश्वासघाती बात यह है कि इसे चूकना बहुत आसान है। कुछ बहुत ही क्लासिक परिदृश्यों पर विचार करें: - अनुपालन कारणों से, आप
paper_trail जैसे रत्न को अपनाते हैं और एक audit_log_entries प्राप्त करें टेबल. आपके एप्लिकेशन में महत्व के मोड वाला प्रत्येक ऑपरेशन audit_log_entries में एक पंक्ति बनाता है टेबल. वे ऑडिट लॉग प्रविष्टियाँ कभी संग्रहीत नहीं होतीं।
- आप अपलोड स्वीकार करते हैं और ActiveStorage का उपयोग कर रहे हैं। आप कभी भी अपलोड को नहीं हटाते हैं, इसलिए आपका
activestorage_blobs टेबल बड़ी और बड़ी होती जा रही है।
- आप वेब पर प्रकाशन के लिए एक साझा सीएमएस चलाते हैं, और आप लेख खंडों को अपने डेटाबेस में संग्रहीत करने की अनुमति देते हैं। आपका मंच सफल हो जाता है, लेकिन आपके अधिकांश लेखक किताब के आकार के लेख लिखते हैं।
pages तालिका बहुत बड़ी हो जाती है, भले ही इसमें केवल कुछ हज़ार पृष्ठ हों।
- आप उपयोगकर्ता द्वारा अपलोड की गई सामग्री की अनुमति देते हैं, लेकिन आप अनुपालन कारणों से डेटा नहीं हटाते हैं, और इसके बजाय
paranoia जैसी किसी चीज़ का उपयोग करते हैं ध्वज के माध्यम से हटाना. आपका user_items तालिका अनिश्चित काल तक बढ़ती है, और आपके जाने बिना, 10M पंक्तियाँ पार कर जाती है।
<पी> अगर समय रहते इन्हें नहीं पकड़ा गया तो इन पैटर्न के निहितार्थ होंगे। यदि आपके पास अपनी तालिकाओं के आकार का अच्छा दृश्य है, तो आप अनुमान लगा सकते हैं कि आपको कम उपयोगकर्ता प्रभाव के साथ अपग्रेड करने के लिए ऑफ-पीक समय पर कब अपग्रेड करना होगा और रखरखाव शेड्यूल करना होगा। <पी> अनुमान बनाना भी बहुत आसान हो जाता है। उदाहरण के लिए: - आज हमारा
events तालिका स्मृति में फ़िट हो जाती है. वर्तमान विकास दर पर, यह सात महीनों में स्मृति में फिट नहीं होगा।
- हम अपने आरडीएस इंस्टेंस प्रकार के लिए 30% भंडारण उपयोग पर हैं। हम अगले साल जनवरी में 90% तक पहुंच जाएंगे।
- हमारे पास
payments पर एक पूर्ण तालिका स्कैन क्वेरी है प्रत्येक पंक्ति पर एक फ़ंक्शन की गणना करने के लिए जहां इनपुट क्वेरी पर निर्भर करता है। हम जानते हैं कि payments तालिका तीन सप्ताह में दो मिलियन पंक्तियों से अधिक हो जाएगी और अगले वर्ष जनवरी तक 20 मिलियन से अधिक हो जाएगी।
<पी> इन सभी में एक घटना या आउटेज के रूप में प्रस्तुत होने की क्षमता है। लेकिन यदि आप जल्दी हमला करते हैं, तो आप इसे काफी आसानी से कम कर सकते हैं। उदाहरण के लिए: events में 30 दिनों से अधिक पुराने सभी डेटा के लिए संग्रहण सेट करें तालिका.- अपने आरडीएस इंस्टेंस को चार महीने में अपग्रेड करें।
- पूर्ण तालिका स्कैन को सीमित करने के लिए, एक अतिरिक्त
WHERE जोड़ें इसके बजाय पंक्तियों के बहुत छोटे उपसमूह पर फ़ंक्शन की गणना करने के लिए हमारी क्वेरी की शर्त।
अपने डेटाबेस के विकास पर दृश्यता प्राप्त करें
<पी> अपने डेटाबेस के विकास पर नज़र रखने के लिए, आपके पास दो संभावनाएँ हैं: - विशेष टूलिंग स्थापित करें (जैसे MySQL के लिए आँकड़े) और इसे प्रोमेथियस, टेलीग्राफ, या अन्य टूल के माध्यम से अपने मेट्रिक्स संग्रह इंजन से कनेक्ट करें।
- AppSignal का उपयोग करें, खासकर यदि आप इसे पहले से ही अपने एप्लिकेशन के लिए उपयोग कर रहे हैं।
<पी> AppSignal कई मीट्रिक प्रकारों को संग्रहीत कर सकता है, और जिन मीट्रिक प्रकारों का यह समर्थन करता है उनमें से एक को gauge कहा जाता है . ए gauge प्रति परिवेश एक एकल समय श्रृंखला है (जैसे production , staging , या development ) जिसे आप समय-समय पर अपडेट कर सकते हैं। ऐपसिग्नल मेट्रिक्स भी टैग की अनुमति देता है, इसलिए हम स्वचालित रूप से कुछ टैग gauge बना सकते हैं हमारे डेटाबेस तालिकाओं के लिए मेट्रिक्स। आइए ऐसा करें: db.row_count हमारी तालिकाओं में पंक्तियों की अनुमानित संख्या के लिए, प्रति तालिका (अनुमान हम बाद में प्राप्त करेंगे)db.data_size_bytes किसी तालिका द्वारा उपयोग की जा रही बाइट्स की संख्या के लिएdb.index_size_bytes तालिका के सूचकांकों द्वारा उपयोग किए जा रहे बाइट्स की संख्या के लिए
<पी> ध्यान दें कि मैं मीट्रिक नाम को मान प्रकार के साथ जोड़ रहा हूं - इससे बाद में मदद मिलती है जब हम परिभाषित करते हैं कि मीट्रिक कैसे प्रदर्शित किया जाएगा। अलग-अलग "डेटा" और "सूचकांक" मेट्रिक्स भी महत्वपूर्ण हैं। यदि किसी तालिका में कई पंक्तियाँ और कुछ से अधिक सूचकांक हैं, तो उन सूचकांकों का आकार संग्रहीत डेटा के आकार का दो या तीन गुना हो सकता है (क्योंकि प्रत्येक सूचकांक अपने लिए व्युत्पन्न डेटा संग्रहीत करता है, जिससे कुछ भंडारण ओवरहेड बनता है)। डेटाबेस तालिका पंक्तियों की त्वरित गिनती
<पी> पंक्तियों की संख्या का "अनुमानित" भाग आवश्यक है। आम तौर पर, यदि आप किसी तालिका में पंक्तियों की सटीक संख्या चाहते हैं, तो आप SELECT COUNT(1) FROM my_table जैसी क्वेरी कर सकते हैं . हालाँकि, यह हमारी अपेक्षा से धीमा हो सकता है। <पी> जब आप COUNT , डेटाबेस यह सुनिश्चित करता है कि क्वेरी के दौरान तालिका में पंक्तियों की संख्या नहीं बदलती है - और इसलिए क्वेरी चलने के दौरान तालिका लॉक हो जाएगी या एक भिन्न लेनदेन बनाएगी। तालिका जितनी बड़ी होगी, क्वेरी उतनी ही धीमी होगी - अधिक पंक्तियाँ स्कैन की जाएंगी, और अधिक लॉक जमा होंगे। <पी> इसलिए, जब हम केवल पंक्तियों की संख्या का "काफी करीब" अनुमान चाहते हैं (प्रदर्शन अनुमान के लिए, 10-30 हजार पंक्तियों की सटीकता कम या अधिक काफी अच्छी है), तो हम इस प्रकार के डेटा के लिए क्वेरी करने के लिए आंतरिक डेटाबेस इंजन आंकड़ों का उपयोग कर सकते हैं। <पी> अधिकांश डेटाबेस ने तालिका डेटा तक पहुंच को अनुकूलित किया है क्योंकि पंक्तियाँ "पृष्ठों" में लिखी गई हैं। डेटाबेस इंजन इस बात पर नज़र रखता है कि कौन सी पंक्तियाँ किन पृष्ठों को सौंपी गई हैं, मोटे तौर पर सम्मिलन क्रम में: - पंक्तियाँ 1-100 पृष्ठ 1 पर हैं
- पंक्तियाँ 101-200 पृष्ठ 2 पर हैं
- पंक्तियाँ 201-300 पृष्ठ 3 पर हैं
<पी> वगैरह. <पी> चूंकि इंजन को पता है कि इसमें प्रति तालिका कितने पृष्ठ हैं और प्रति पृष्ठ इसका उपयोग करने वाली रफ पंक्ति गणना, यह आवंटित पृष्ठों की गणना कर सकता है और फिर आपको यह अनुमान देने के लिए इसे पृष्ठ आकार (प्रति पृष्ठ पंक्तियाँ) से गुणा कर सकता है। इसके कुछ फायदे हैं:गिनती बहुत तेज़ है, और क्वेरी चलने के दौरान तालिका को लॉक करने की आवश्यकता नहीं है। MySQL के लिए तालिका आकार रिकॉर्ड करें
<पी> फिर हमें प्रत्येक डेटाबेस के लिए अलग-अलग कार्य करने की आवश्यकता है क्योंकि हमें तालिका आँकड़ों के लिए डेटाबेस इंजन को क्वेरी करने की आवश्यकता है। आइए MySQL से शुरू करें। यहां वह क्वेरी है जिसे हमें चलाने की आवश्यकता है: <पी> फिर, इसके आउटपुट से कुछ कॉलम लें। जिनमें हमारी रुचि है वे Data_length हैं , Index_length , और Rows . तालिका का आकार Data_length + Index_length के योग के रूप में परिभाषित किया गया है , और पृष्ठों के आधार पर अनुमानित पंक्ति गणना Rows में है . <पी> आइए इसे एक कोड ब्लॉक में पैकेज करें जो आपके संपूर्ण डेटाबेस के लिए इस डेटा को एकत्र करता है। चूँकि हम किसी भी ActiveModel के साथ काम नहीं कर रहे हैं कक्षाओं में, हम सीधे ActiveRecord द्वारा प्रदान की गई क्वेरी विधियों का उपयोग करने जा रहे हैं: PostgreSQL के लिए तालिका आकार रिकॉर्ड करें
<पी> हमें PostgreSQL के लिए अधिक विस्तृत क्वेरी की आवश्यकता है क्योंकि हमारे पास SHOW TABLE STATUS जैसी कोई शॉर्टकट क्वेरी नहीं है . हमें आंतरिक PostgreSQL तालिकाओं को क्वेरी करना होगा: <पी> ध्यान दें कि यह केवल public के लिए है स्कीमा (डिफ़ॉल्ट वह जिसे आप संभवतः उपयोग कर रहे हैं)। यदि आप अन्य स्कीमा शामिल करना चाहते हैं, तो आपको WHERE t.table_schema = 'public' को हटाना होगा शर्त लगाएं और table_info.fetch('name') बदलें table_info.fetch('full_table_name') के साथ . सुनिश्चित करें कि मेट्रिक्स नियमित रूप से अपडेट हों
<पी> इस ब्लॉक को नियमित अंतराल पर चलाना होता है, इसलिए इसे साइडकिक शेड्यूलर या क्रॉन से चलने वाले रेक कार्य में डालना एक अच्छा विचार है। उदाहरण के लिए, यदि आप Good_job का उपयोग करते हैं, तो आप इसे अपने "क्रॉन" अनुभाग में इस प्रकार जोड़ सकते हैं: एक डैशबोर्ड बनाएं
<पी> एक बार जब आपके पास डेटा आ जाए, तो एक डैशबोर्ड बनाएं। आप अपनी आवश्यकताओं के लिए निम्नलिखित डैशबोर्ड को कॉपी कर सकते हैं: <पी> Add dashboard पर क्लिक करें और फिर Import dashboard दिखाई देने वाले मोडल संवाद में. डैशबोर्ड आपको इस तरह के ग्राफ़ देगा: <पी> 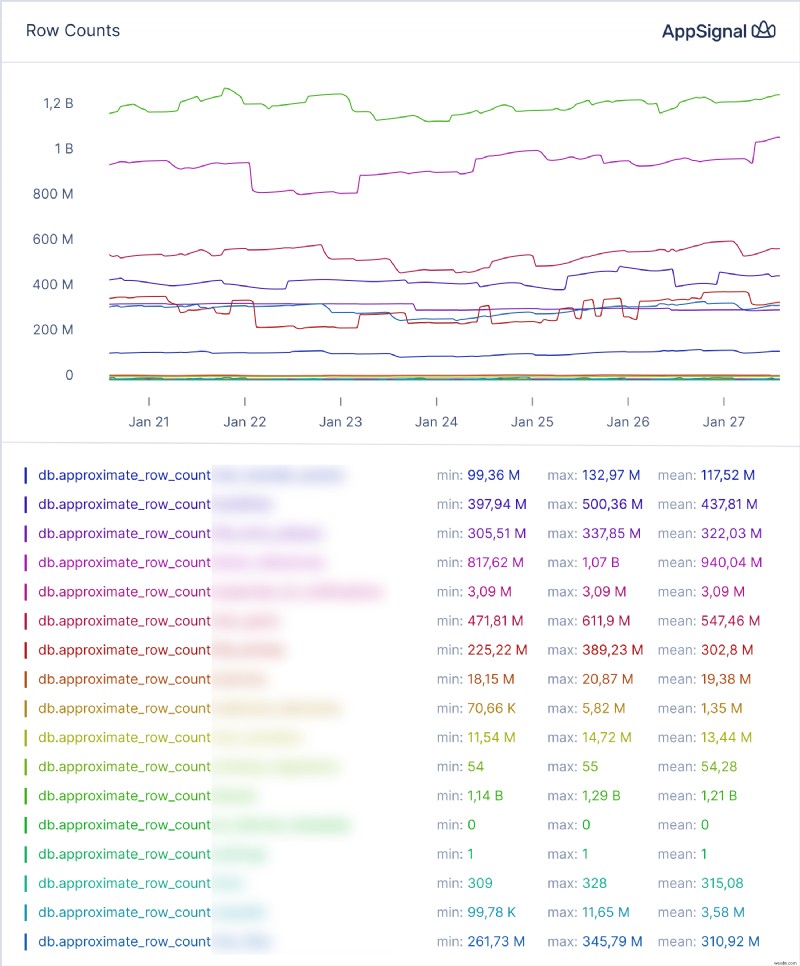 <पी> और यह तालिका आकार ग्राफ़: <पी>
<पी> और यह तालिका आकार ग्राफ़: <पी> 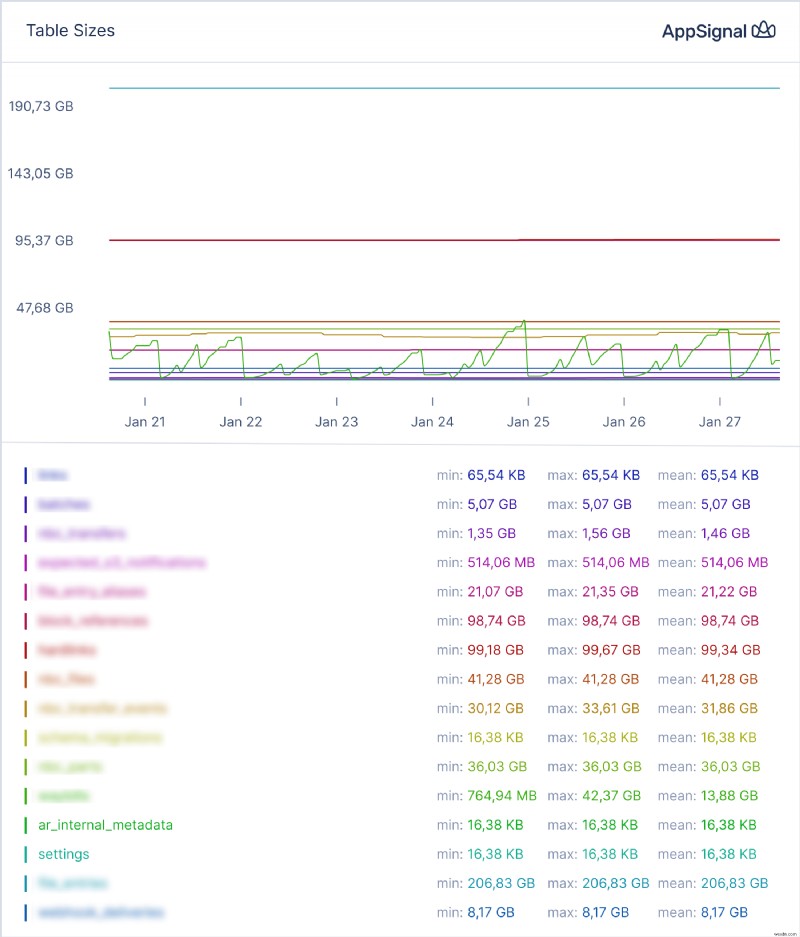 <पी> ध्यान दें कि हम डेटाबेस में प्रत्येक तालिका के लिए स्वचालित रूप से ग्राफ़ बनाने के लिए वाइल्डकार्ड टैग का उपयोग कैसे करते हैं।
<पी> ध्यान दें कि हम डेटाबेस में प्रत्येक तालिका के लिए स्वचालित रूप से ग्राफ़ बनाने के लिए वाइल्डकार्ड टैग का उपयोग कैसे करते हैं। डेटा की व्याख्या करना
<पी> अपने डेटा को देखते समय, पंक्ति गणना या आकार में घातीय या रैखिक वृद्धि पर ध्यान दें - दूसरे शब्दों में, एक तालिका बड़ी और बड़ी होती जा रही है। <पी> यदि आप इसे देखते हैं, तो आपके पास कुछ विकल्प हैं। एक तो इस असीमित विकास के लिए वास्तुकार बनना है - जानें कि कब अपग्रेड करना है, और क्या आप अगले सर्वोत्तम आकार में अपग्रेड कर सकते हैं। दूसरा है नियमित विलोपन कार्य स्थापित करना - मेरे पूर्व सहयोगी वांडर हिलन ने इस विषय पर एक बेहतरीन लेख लिखा है। <पी> उदाहरण के लिए, ऊपर दिए गए स्क्रीनशॉट में, कुछ तालिकाएँ नियमित रूप से सिकुड़ती हैं - यह तब होता है जब नियमित सफाई कार्य चलते हैं। आप देख सकते हैं कि डेटा एक निश्चित बिंदु तक जमा होता है, लेकिन जब पंक्तियों का प्रवेश काफी स्थिर होता है, तो आकार और पंक्तियों की संख्या कम हो जाती है। <पी> जब तक ये गिरावटें हैं और आपकी तालिकाओं में डेटा की मात्रा स्थिर दर से बढ़ती है, आपका डेटाबेस आपको अचानक सीमा बस्ट से आश्चर्यचकित नहीं करेगा। सारांश:डेटाबेस तालिकाओं से डेटा ब्लोट से बचें
<पी> इस पोस्ट में, हमने देखा कि आप अपने डेटाबेस के विकास पर दृश्यता कैसे प्राप्त कर सकते हैं और अपने डेटा को कम रख सकते हैं। <पी> डेटा ब्लॉट उन अनुप्रयोगों के लिए एक वास्तविक जोखिम है जो बाज़ार में सफल हो जाते हैं। अपने डेटाबेस तालिकाओं के लिए मेट्रिक्स सेट करके, आप बेहतर अनुमान लगा सकते हैं कि कब अपने डेटाबेस को लंबवत रूप से स्केल करना है और क्या आपको नियमित पुराने डेटा क्लीनअप स्थापित करने की आवश्यकता है। टैग के साथ AppSignal गेज, थोड़े SQL के साथ मिलकर, आपको यह डेटा एक सुविधाजनक और सुखद प्रारूप में प्राप्त कर सकता है। <पी> अपने डेटाबेस को आपको आश्चर्यचकित न करने दें! 
जूलिक तारखानोव
<पी> अतिथि लेखक जूलिक तारखानोव चेडर पेमेंट्स में एक स्टाफ सॉफ्टवेयर इंजीनियर हैं और कई रूबी ओपन-सोर्स लाइब्रेरी के लेखक हैं। <पी> जूलिक तारखानोव के सभी लेख


