<पी> रेल्स फ्रेमवर्क की ख़ूबियों में से एक आपके मॉडलों में रूबी ऑन रेल्स एसोसिएशन का उपयोग करने की क्षमता है। ये एसोसिएशन आपको सुखद सिंटैक्स के साथ अपने कोड में रिकॉर्ड के संग्रह तक पहुंचने की अनुमति देते हैं, जिससे अंतर्निहित SQL क्वेरी लिखने की आवश्यकता दूर हो जाती है। यह अमूर्तता तब तक कायम रहती है जब तक आपका सारा डेटा एक ही स्थान पर रहता है। जैसे ही आपकी तालिकाएँ अलग-अलग डेटाबेस समूहों में फैल जाती हैं, कुछ एसोसिएशन प्रकार काम करना बंद कर देते हैं। <पी> यह आलेख बताता है कि वह सीमा कहां है और रेल उसके भीतर काम करने के लिए क्या प्रदान करती है। हम इससे शुरू करते हैं कि समस्या क्यों होती है और रेल में कौन से एसोसिएशन प्रभावित होते हैं, और डेटाबेस कॉन्फ़िगरेशन और मॉडल पदानुक्रम में आगे बढ़ते हैं जो एकाधिक क्लस्टर और कई से कई रिश्तों का समर्थन करता है। वहां से हम देखेंगे कि अलग-अलग डेटा एक्सेस पैटर्न प्रत्येक उस अपघटन के साथ कैसे इंटरैक्ट करते हैं। <पी> यदि आप एक रेल एसोसिएशन ट्यूटोरियल की तलाश कर रहे हैं जो विशेष रूप से मल्टी-डेटाबेस सेटअप को कवर करता है, तो यही है। हम कई अन्य चीजों पर भी चर्चा करेंगे, इसलिए बने रहें। डेटाबेस अलग-अलग समूहों में क्यों समाप्त होते हैं
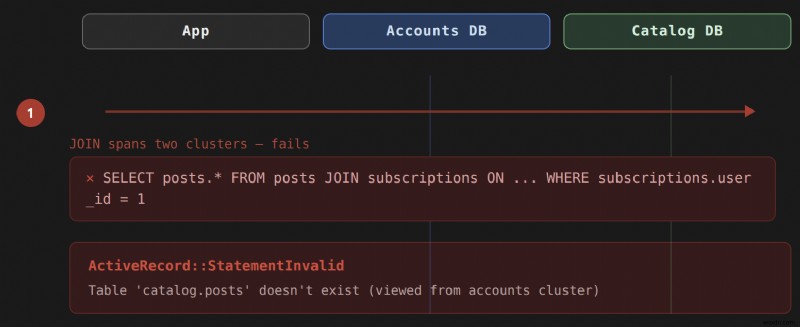
<पी> जब एक रेल एप्लिकेशन अपने सभी डेटा को एक ही डेटाबेस में संग्रहीत करता है, तो सक्रिय रिकॉर्ड एसोसिएशन को पारदर्शी रूप से नियंत्रित किया जाता है, और आप अंतर्निहित SQL के बारे में कभी नहीं सोचते हैं। जिस क्षण आपका डेटा कई डेटाबेस समूहों में रहता है, वह पारदर्शिता टूट जाती है। ए JOIN दोनों तालिकाओं का एक ही डेटाबेस सर्वर में मौजूद होना आवश्यक है। समूहों में एक का प्रयास करने से एक ActiveRecord::StatementInvalid उत्पन्न होता है इस प्रकार की त्रुटि: ActiveRecord::StatementInvalid (Table 'people_cluster.humans' doesn't exist)
<पी> यह कोई कॉन्फ़िगरेशन गलती नहीं है. यह एक कठिन भौतिक बाधा है:डेटाबेस सर्वर JOIN नहीं कर सकते उन तालिकाओं के विरुद्ध जिन्हें वे होस्ट नहीं करते हैं। हमें यह समस्या has_many :through में है और has_one :through एसोसिएशन, क्योंकि वे एसोसिएशन प्रकार हैं जो मध्यवर्ती JOIN उत्पन्न करते हैं प्रश्न. डायरेक्ट has_many या belongs_to रिश्तों को जुड़ने की आवश्यकता नहीं होती है इसलिए वे बिना किसी संशोधन के समूहों में काम करते हैं। <पी> कब को समझना आप इस सीमा को मारेंगे यह पहला कदम है। यदि कोई User accounts में रहता है डेटाबेस और एक Post content में रहता है डेटाबेस, User has_many :posts ठीक काम करता है. लेकिन यदि आप एक मध्यवर्ती Subscription जोड़ते हैं billing में मॉडल डेटाबेस और User has_many :posts, through: :subscriptions को परिभाषित करें , रेल्स subscriptions से जुड़ने का प्रयास करेगी और posts एक ही प्रश्न में. यहीं पर क्लस्टर सीमा एक समस्या बन जाती है। त्रिस्तरीय डेटाबेस कॉन्फ़िगरेशन
<पी> किसी भी मॉडल कोड को लिखने से पहले, डेटाबेस कॉन्फ़िगरेशन को मल्टी-क्लस्टर लेआउट को प्रतिबिंबित करने की आवश्यकता होती है। config/database.yml में रेल त्रि-स्तरीय संरचना का उपयोग करती है इस प्रयोजन के लिए. प्रत्येक शीर्ष-स्तरीय पर्यावरण कुंजी में नेस्टेड डेटाबेस नाम होते हैं, और उनमें से प्रत्येक में उस क्लस्टर के लिए कनेक्शन विवरण होते हैं। # config/database.yml
default: &default
adapter: postgresql
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
development:
primary:
<<: *default
database: myapp_primary_dev
accounts:
<<: *default
database: myapp_accounts_dev
migrations_paths: db/accounts_migrate
content:
<<: *default
database: myapp_content_dev
migrations_paths: db/content_migrate
production:
primary:
<<: *default
database: myapp_primary_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
accounts:
<<: *default
database: myapp_accounts_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
content:
<<: *default
database: myapp_content_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
<पी> migrations_paths यदि आप रेल जनरेटर और db:migrate चाहते हैं तो कुंजी गैर-वैकल्पिक है माइग्रेशन को सही निर्देशिका में रूट करने के लिए। इसके बिना, सभी माइग्रेशन डिफ़ॉल्ट रूप से db/migrate पर हो जाते हैं और प्राथमिक डेटाबेस पर लागू हो जाएं। प्रत्येक द्वितीयक डेटाबेस में एक संगत सार रिकॉर्ड वर्ग भी होना चाहिए जो रेल मॉडल को विरासत में मिला है। जब आप --database पास करते हैं तो जेनरेटर इसे स्वचालित रूप से संभाल लेते हैं झंडा: rails generate model Subscription plan:string --database accounts
<पी> यह एक AccountsRecord उत्पन्न करता है क्लास यदि कोई पहले से मौजूद नहीं है, और जेनरेट किया गया Subscription मॉडल इससे विरासत में मिला है। सार रिकॉर्ड कक्षाएं और कनेक्शन रूटिंग
<पी> अमूर्त रिकॉर्ड वर्ग वह तंत्र है जिसका उपयोग रेल प्रश्नों को सही क्लस्टर तक रूट करने के लिए करती है। प्रत्येक व्यक्ति connects_to पर कॉल करता है यह घोषित करने के लिए कि यह लिखने और पढ़ने के संचालन के लिए किस डेटाबेस पर मैप करता है। इस पदानुक्रम में आपके एप्लिकेशन में आमतौर पर तीन परतें होंगी। # app/models/application_record.rb
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to database: { writing: :primary, reading: :primary }
end
# app/models/accounts_record.rb
class AccountsRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :accounts, reading: :accounts }
end
# app/models/content_record.rb
class ContentRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :content, reading: :content }
end
<पी> इस पदानुक्रम को समझने के लिए उपयोगकर्ता मॉडल एक अच्छा एंकर है। यह accounts में रहता है क्लस्टर और AccountsRecord से विरासत में मिला है . content में मॉडल क्लस्टर ContentRecord से प्राप्त होता है . बाकी सब कुछ ApplicationRecord से प्राप्त होता है और प्राथमिक डेटाबेस को हिट करता है। यह इनहेरिटेंस श्रृंखला है कि कैसे सक्रिय रिकॉर्ड यह निर्धारित करता है कि किसी क्वेरी को निष्पादित करते समय किस कनेक्शन पूल का उपयोग किया जाए। यह वर्ग पदानुक्रम पर तब तक चलता है जब तक कि उसे एक ऐसा वर्ग नहीं मिल जाता जिसे connects_to कहा जाता है . 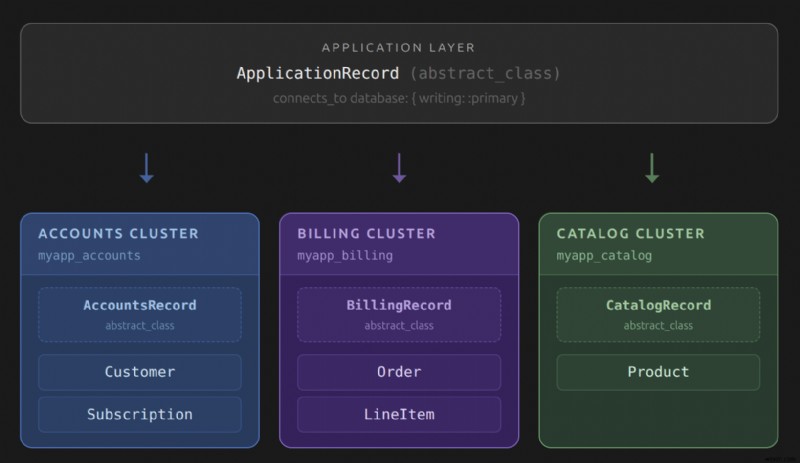 <पी>
<पी> establish_connection पर कॉल करना एक सामान्य गलती है अमूर्त वर्गों का उपयोग करने के बजाय व्यक्तिगत मॉडल पर। प्रत्येक establish_connection कॉल एक अलग कनेक्शन पूल खोलता है। यदि आपके पास accounts में 50 मॉडल हैं डेटाबेस, प्रत्येक कॉलिंग establish_connection , आप एक ही सर्वर पर इंगित करने वाले 50 कनेक्शन पूल के साथ समाप्त होते हैं। सार कक्षाएं उन सभी मॉडलों में एक एकल पूल साझा करके इसे हल करती हैं जो उनसे विरासत में मिले हैं। रेल में क्रॉस-क्लस्टर एसोसिएशन वास्तव में कैसे काम करते हैं
<पी> disable_joins: true विकल्प through बनाने के लिए प्रत्यक्ष तंत्र है एसोसिएशन तब काम करती हैं जब शामिल तालिकाएँ अलग-अलग समूहों में रहती हैं। रेल has_many सबसे अधिक इस्तेमाल किया जाने वाला एसोसिएशन प्रकार है, और यह क्लस्टर सीमाओं से सबसे अधिक सीधे प्रभावित होता है। जब रेल्स को किसी एसोसिएशन पर यह विकल्प मिलता है, तो वह सिंगल JOIN को छोड़ देता है क्वेरी रणनीति और इसके बजाय दो (या अधिक) अनुक्रमिक SELECT जारी करती है कथन, पहली क्वेरी से आईडी को WHERE ... IN (...) में पाइप करना दूसरे में उपवाक्य. <पी> यहां तीन समूहों में फैला एक ठोस मॉडल सेटअप है। नीचे दिया गया मॉडल सेटअप एक अनेक-से-अनेक संबंध है, एक उपयोगकर्ता सदस्यता के माध्यम से पोस्ट से जुड़ता है, और यह वह पैटर्न है जो क्रॉस-क्लस्टर समस्या को सबसे सीधे उजागर करता है। # app/models/user.rb - lives in the accounts database
class User < AccountsRecord
has_many :subscriptions
has_many :posts, through: :subscriptions, disable_joins: true
end
# app/models/subscription.rb - lives in the accounts database
class Subscription < AccountsRecord
belongs_to :user
has_many :posts
end
# app/models/post.rb - lives in the content database
class Post < ContentRecord
belongs_to :subscription
end
<पी> जब आप user.posts पर कॉल करते हैं , रेल एकल JOIN के बजाय प्रश्नों की यह जोड़ी उत्पन्न करता है : -- Query 1: fetch subscription IDs from the accounts cluster
SELECT "subscriptions"."id"
FROM "subscriptions"
WHERE "subscriptions"."user_id" = 1
-- Query 2: fetch posts from the content cluster using those IDs
SELECT "posts".*
FROM "posts"
WHERE "posts"."subscription_id" IN (4, 7, 12)
<पी> पहली क्वेरी accounts के विरुद्ध चलती है प्राथमिक कुंजी एकत्र करने के लिए डेटाबेस। दूसरा content के विरुद्ध चलता है . रेल्स विदेशी कुंजियों, user_id का पालन करके संबंध का समाधान करती है सदस्यता और subscription_id पर पोस्टों पर, दो समूहों में। पहली क्वेरी सब्सक्रिप्शन से प्राथमिक कुंजी मान एकत्र करती है, फिर उन्हें IN में भेजती है दूसरी क्वेरी का खंड. कोई भी क्वेरी क्रॉस-क्लस्टर में शामिल होने का प्रयास नहीं करती है। रेल्स एप्लिकेशन मेमोरी में सेट किए गए अंतिम परिणाम को असेंबल करता है। 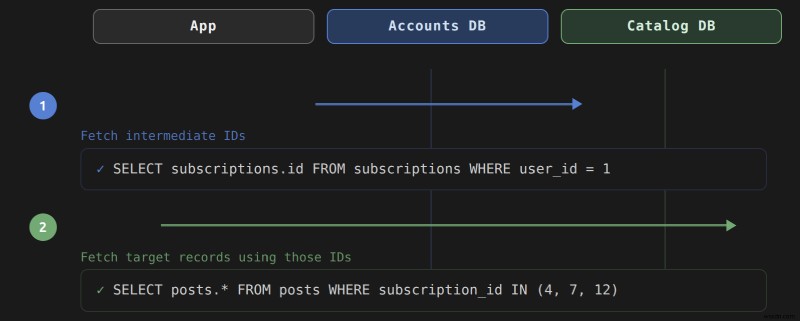
 वही विकल्प
वही विकल्प has_one :through पर समान रूप से काम करता है : # app/models/user.rb
class User < AccountsRecord
has_one :profile
has_one :avatar, through: :profile, disable_joins: true
end
# app/models/profile.rb - accounts database
class Profile < AccountsRecord
belongs_to :user
has_one :avatar
end
# app/models/avatar.rb - content database
class Avatar < ContentRecord
belongs_to :profile
end
<पी> user.avatar दो क्वेरी निष्पादित करेगा:एक profile_id प्राप्त करने के लिए , सामग्री क्लस्टर से अवतार रिकॉर्ड लाने के लिए दूसरा। जब disable_joins स्पष्ट रूप से सेट किया जाना चाहिए
<पी> रेल्स स्वचालित रूप से क्लस्टर सीमाओं का पता नहीं लगाती है और disable_joins सम्मिलित नहीं करती है आपके लिए. सक्रिय रिकॉर्ड में एसोसिएशन लोड करना आलसी है। किसी एसोसिएशन के लिए एसक्यूएल उस बिंदु पर निर्धारित किया जाता है जहां एसोसिएशन को मॉडल पर परिभाषित किया जाता है, न कि तब जब यह वास्तव में ट्रिगर होता है। user.posts के समय तक निष्पादित करता है, रेल्स ने पहले ही तय कर लिया है कि JOIN का उपयोग करना है या नहीं या एसोसिएशन घोषणा के आधार पर अलग-अलग प्रश्न। <पी> इसका मतलब प्रत्येक through है क्लस्टर सीमा को पार करने वाले एसोसिएशन को disable_joins: true की आवश्यकता होती है घोषणा पर. <पी> अपने मॉडलों का ऑडिट करने का एक व्यावहारिक तरीका किसी भी through: को देखना है एसोसिएशन जहां स्रोत मॉडल और लक्ष्य मॉडल विभिन्न अमूर्त रिकॉर्ड वर्गों से प्राप्त होते हैं। यदि User < AccountsRecord और Post < ContentRecord , फिर has_many :posts, through: :subscriptions disable_joins: true की आवश्यकता है भले ही Subscription कहां हो रहता है. क्लस्टरों में उत्सुक लोडिंग
<पी> disable_joins विकल्प प्रभावित करता है कि एसोसिएशन कैसे लोड किए जाते हैं, लेकिन यह नहीं बदलता है कि उत्सुक लोडिंग रणनीतियाँ क्रॉस-क्लस्टर डेटा के साथ कैसे इंटरैक्ट करती हैं। मल्टी-डेटाबेस सेटअप में N+1 प्रश्नों से बचने के लिए इस अंतर को समझना मायने रखता है। <पी> eager_load क्रॉस-क्लस्टर एसोसिएशनों के लिए टेबल से बाहर है। यह एक LEFT OUTER JOIN उत्पन्न करता है , जिसकी भौतिक सीमा नियमित JOIN के समान ही है , दोनों तालिकाएँ एक ही सर्वर पर होनी चाहिए। यदि आप User.eager_load(:posts) का प्रयास करते हैं जहां पोस्ट एक अलग क्लस्टर में रहते हैं, आपको वही StatementInvalid मिलेगा त्रुटि. <पी> preload सही रणनीति है. यह प्रत्येक एसोसिएशन के लिए अलग-अलग प्रश्न जारी करता है और रूबी में संबंध जोड़ता है। यह संरचनात्मक रूप से disable_joins के समान है एकल रिकॉर्ड के लिए करता है. अंतर स्केल है:preload सभी लोड किए गए मूल रिकॉर्ड में दूसरी क्वेरी को बैच करता है। # This works across clusters.
# Query 1: SELECT "users".* FROM "users"
# Query 2: SELECT "posts".* FROM "posts" WHERE "posts"."subscription_id" IN (...)
users = User.preload(:posts).all
users.each do |user|
user.posts.each { |post| puts post.title } # No additional queries fired
end
<पी> includes उन मामलों में काम करेगा जहां यह preload को सौंपता है आंतरिक रूप से, जो यह डिफ़ॉल्ट रूप से तब करता है जब संबंधित तालिका को संदर्भित करने वाली कोई शर्तें नहीं होती हैं। यदि आप .where जोड़ते हैं खंड जो संबंधित तालिका के कॉलम को छूता है, includes eager_load पर स्विच हो जाता है व्यवहार, और समूहों में विफल हो जाएगा। जब आपको किस रणनीति के बारे में संदेह हो includes चुनेंगे, स्पष्ट होंगे और preload का उपयोग करेंगे सीधे. # includes delegates to preload here, works across clusters
User.includes(:posts).all
# includes switches to eager_load because of the where clause, fails across clusters
User.includes(:posts).where("posts.published = ?", true)
# Use preload + a separate where for cross-cluster filtering
User.preload(:posts).all.select { |u| u.posts.any?(&:published?) }
# Or filter in application code after loading
स्कोप्ड एसोसिएशन और क्रॉस-क्लस्टर फ़िल्टरिंग
<पी> मल्टी-डेटाबेस सेटअप में अधिक सूक्ष्म इंटरैक्शन में से एक स्कोप्ड एसोसिएशन है। जब आप has_many पर एक दायरा परिभाषित करते हैं जो क्लस्टर को पार करता है, स्कोप का SQL लक्ष्य डेटाबेस के विरुद्ध चलता है, स्रोत के विरुद्ध नहीं। class User < AccountsRecord
has_many :subscriptions
has_many :published_posts,
-> { where(published: true) },
through: :subscriptions,
source: :posts,
class_name: "Post",
disable_joins: true
end
<पी> where(published: true) क्लॉज दूसरी क्वेरी में जुड़ जाता है, जो content के विरुद्ध चलता है डेटाबेस. यह सही व्यवहार है, और इसका मतलब है कि आपके दायरे बिना किसी समस्या के लक्ष्य तालिका पर कॉलम को संदर्भित कर सकते हैं। आप जो नहीं कर सकते हैं वह उस दायरे में मध्यवर्ती तालिका से संदर्भ कॉलम है, क्योंकि स्कोप्ड क्वेरी निष्पादित होने तक मध्यवर्ती क्वेरी पहले ही पूरी हो चुकी है। # This will fail because subscriptions.active is not a column in the content database
has_many :active_posts,
-> { where("subscriptions.active = ?", true) },
through: :subscriptions,
source: :posts,
disable_joins: true
<पी> इसके बजाय मध्यवर्ती एसोसिएशन में एक दायरा जोड़कर मध्यवर्ती रिकॉर्ड फ़िल्टर करें: class User < AccountsRecord
has_many :active_subscriptions, -> { where(active: true) }, class_name: "Subscription"
has_many :active_posts, through: :active_subscriptions, source: :posts, disable_joins: true
end
<पी> अब subscriptions.active पर फ़िल्टरिंग पहली क्वेरी में, accounts के विरुद्ध होता है डेटाबेस, और केवल सक्रिय सदस्यता की आईडी ही दूसरी क्वेरी को पास की जाती है। क्षैतिज शार्डिंग और क्रॉस-शार्क एसोसिएशन
<पी> tenant_id जैसी विभाजन कुंजी के आधार पर एक तार्किक डेटाबेस को कई सर्वरों में विभाजित करना क्रॉस-क्लस्टर समस्या का दूसरा आयाम प्रस्तुत करता है। disable_joins तंत्र अभी भी लागू होता है, लेकिन कनेक्शन रूटिंग अधिक शामिल हो जाती है। <पी> रेल connected_to प्रदान करती है अनुरोध के भीतर शार्ड के बीच स्विच करने के लिए: ActiveRecord::Base.connected_to(role: :writing, shard: :shard_one) do
User.find(1) # Hits shard_one
end
<पी> जब एसोसिएशन क्लस्टर और शार्ड दोनों तक फैली होती है, तो आपको शार्ड संदर्भ और disable_joins दोनों को सुनिश्चित करने की आवश्यकता होती है। विकल्प मौजूद हैं. ए User shard_one पर एक अलग content में रहने वाले पोस्ट तक पहुँचना डेटाबेस को अभी भी उसी दो-क्वेरी अपघटन की आवश्यकता है। <पी> रेल्स 8 ने आत्मनिरीक्षण विधियाँ जोड़ीं जो रनटाइम पर शार्ड टोपोलॉजी के बारे में तर्क करना आसान बनाती हैं: class ShardedBase < ActiveRecord::Base
self.abstract_class = true
connects_to shards: {
shard_one: { writing: :shard_one },
shard_two: { writing: :shard_two }
}
end
class User < ShardedBase; end
User.shard_keys # => [:shard_one, :shard_two]
User.sharded? # => true
ShardedBase.connected_to_all_shards do
User.current_shard # Yields :shard_one, then :shard_two
end
<पी> connected_to_all_shards पृष्ठभूमि नौकरियों के लिए विशेष रूप से उपयोगी है जिन्हें प्रत्येक शार्ड में रिकॉर्ड संसाधित करने की आवश्यकता होती है। यह क्रम में प्रत्येक शार्ड पर पुनरावृत्ति करता है, प्रत्येक ब्लॉक निष्पादन के लिए कनेक्शन संदर्भ को स्विच करता है। <पी> किरायेदार-आधारित शार्डिंग के लिए, lock: true शार्ड स्विचिंग पर डिफ़ॉल्ट, किरायेदार को अनुरोध के बीच में आकस्मिक रूप से रुकने से रोकता है। यह एक सुरक्षा तंत्र है:एक बार अनुरोध किरायेदार के शार्ड पर भेज दिया जाता है, तो एप्लिकेशन कोड स्पष्ट रूप से lock: false पास किए बिना किसी अन्य किरायेदार के शार्ड पर स्विच नहीं कर सकता है। . एकल किरायेदार के हिस्से के भीतर क्रॉस-क्लस्टर एसोसिएशन अभी भी disable_joins का उपयोग करते हैं उन एसोसिएशनों के लिए जो एक अलग डेटाबेस क्लस्टर को छूते हैं। क्रॉस-क्लस्टर एसोसिएशन का परीक्षण
<पी> मल्टी-डेटाबेस सेटअप का परीक्षण करने के लिए आवश्यक है कि आपका परीक्षण वातावरण उत्पादन डेटाबेस टोपोलॉजी को प्रतिबिंबित करे। रेल का परीक्षण ढांचा इसका समर्थन करता है, लेकिन कॉन्फ़िगरेशन स्पष्ट होना चाहिए। <पी> database.yml में प्रत्येक डेटाबेस test की आवश्यकता है पर्यावरण ब्लॉक. फिक्स्चर और फ़ैक्टरी-आधारित परीक्षण डेटा को सही डेटाबेस को लक्षित करना चाहिए। यदि कोई User फ़ैक्टरी accounts में एक रिकॉर्ड बनाती है डेटाबेस और एक Post फ़ैक्टरी content में एक बनाती है , उनके बीच संबंध केवल तभी काम करता है जब दोनों रिकॉर्ड एक ही परीक्षण लेनदेन के भीतर उनके संबंधित डेटाबेस में मौजूद हों। <पी> रेल्स प्रत्येक परीक्षण को डिफ़ॉल्ट रूप से लेनदेन में लपेटता है, लेकिन वह लेनदेन प्रति-कनेक्शन है। एकाधिक डेटाबेस के साथ, प्रत्येक कनेक्शन को अपना स्वयं का लेनदेन मिलता है। इसका मतलब है कि परीक्षण क्लीनअप (प्रत्येक परीक्षण के अंत में स्वचालित रोलबैक) प्रत्येक डेटाबेस पर स्वतंत्र रूप से होता है। यदि आपका परीक्षण User लिखता है accounts पर और एक Post content पर , दोनों को वापस ले लिया जाएगा, लेकिन केवल तभी जब परीक्षण ढांचे को दोनों कनेक्शनों के बारे में पता हो। <पी> fixtures जब मॉडल सही अमूर्त वर्ग से प्राप्त होते हैं तो घोषणा स्वचालित रूप से इसे संभालती है। फ़ैक्टरी-आधारित सेटअप (फ़ैक्टरीबॉट, फैब्रिकेटर) के लिए, प्रत्येक फ़ैक्टरी का create सुनिश्चित करें रणनीति मॉडल को अपना connects_to देकर सही डेटाबेस तक पहुंचती है रूटिंग कार्य करें. # spec/factories/users.rb
FactoryBot.define do
factory :user do
# User inherits from AccountsRecord and writes to accounts DB automatically
name { Faker::Name.name }
end
end
# spec/factories/posts.rb
FactoryBot.define do
factory :post do
# Post inherits from ContentRecord and writes to content DB automatically
association :subscription
title { Faker::Lorem.sentence }
end
end
<पी> यह सत्यापित करने के लिए कि क्रॉस-क्लस्टर एसोसिएशन अपेक्षित संख्या में क्वेरी सक्रिय कर रहे हैं, sql.active_record की सदस्यता लें। अधिसूचना: # spec/support/query_counter.rb
module QueryCounter
def assert_query_count(expected, &block)
count = 0
callback = ->(_name, _start, _finish, _id, payload) do
count += 1 unless payload[:name] == "SCHEMA" || payload[:sql].start_with?("EXPLAIN")
end
ActiveSupport::Notifications.subscribed(callback, "sql.active_record", &block)
assert_equal expected, count, "Expected #{expected} queries, got #{count}"
end
end
<पी> ए has_many :through disable_joins: true के साथ एक ही रिकॉर्ड पर बिल्कुल 2 प्रश्न उत्पन्न होने चाहिए। यदि आप 1 देखते हैं, तो जुड़ने का प्रयास अभी भी किया जा रहा है (और अलग-अलग सर्वरों के विरुद्ध उत्पादन में विफल हो जाएगा)। यदि आप N+1 देखते हैं, तो उत्सुक लोडिंग अपेक्षा के अनुरूप काम नहीं कर रही है। कुछ चेतावनी
<पी> disable_joins एसोसिएशन लोडिंग समस्या को हल करता है, लेकिन यह क्वेरी चेनिंग तक विस्तारित नहीं होता है। आप .where को श्रृंखलाबद्ध नहीं कर सकते , .order , या .group खंड जो एकल सक्रिय रिकॉर्ड संबंध पर समूहों में स्तंभों को संदर्भित करता है: # This does not work, you cannot filter products by order columns across clusters
customer.purchased_products.where("orders.total > ?", 100)
<पी> उन प्रश्नों के लिए जिन्हें एकाधिक समूहों में डेटा के आधार पर फ़िल्टर या सॉर्ट करने की आवश्यकता होती है, उन्हें मैन्युअल रूप से विघटित करें। एक क्लस्टर से आवश्यक आईडी या मान प्राप्त करें, फिर उन्हें दूसरे के विरुद्ध क्वेरी में इनपुट के रूप में उपयोग करें: high_value_order_ids = Order.where(customer_id: customer.id)
.where("total > ?", 100)
.pluck(:id)
line_item_product_ids = LineItem.where(order_id: high_value_order_ids).pluck(:product_id)
products = Product.where(id: line_item_product_ids)
<पी> यह वही अपघटन है जो disable_joins है आंतरिक रूप से कार्य करता है, लेकिन स्पष्ट रूप से किया जाता है ताकि आप प्रत्येक चरण में फ़िल्टरिंग लागू कर सकें। यह अधिक क्रियात्मक है, लेकिन यह क्लस्टर सीमाओं को रेल सिंटैक्स में एसोसिएशन के पीछे छिपाने के बजाय कोड में दृश्यमान बनाता है। <पी> संपादक का नोट:यह पोस्ट मूल रूप से जनवरी 2023 में प्रकाशित हुई थी और सटीकता के लिए इसे अपडेट किया गया है।