सॉलिड क्यू में महारत हासिल करना:रूबी ऑन रेल्स के लिए एक सिद्ध बैकग्राउंड जॉब सॉल्यूशन
<पी> इस श्रृंखला में हमारे पिछले लेख ने स्थापित किया कि यदि आपको पृष्ठभूमि नौकरियों को संसाधित करने के लिए एक सिस्टम की आवश्यकता है तो सॉलिड क्यू एक उत्कृष्ट विकल्प है। यह बाहरी निर्भरता को कम करता है - रेडिस की कोई आवश्यकता नहीं! - अपने डेटाबेस में सभी नौकरियों को संग्रहीत करके। इसके बावजूद, यह अविश्वसनीय रूप से प्रदर्शन करने वाला है। <पी> लेकिन उत्पादन-तैयार पृष्ठभूमि कार्य प्रणाली के लिए केवल निष्पादक होना ही पर्याप्त नहीं है। पिछले कुछ वर्षों में रेल डेवलपर्स को काफी उम्मीदें रही हैं। हम केवल पृष्ठभूमि में चलने के लिए नौकरियों की कतार बनाना नहीं चाहते हैं। हम नौकरियों को शेड्यूल करना चाहते हैं, उन्हें आवर्ती शेड्यूल पर चलाना चाहते हैं, और हम यह भी सीमित करना चाह सकते हैं कि कितनी नौकरियां एक साथ चल सकती हैं। हम और अधिक सुविधाएं चाहते हैं! <पी> आश्चर्यजनक रूप से, सॉलिड क्यू उन सभी सुविधाओं को बॉक्स से बाहर प्रदान करता है। आइए सॉलिड क्यू के बारे में गहराई से जानें और जानें कि यह कैसे संभव है! रूबी ऑन रेल्स के लिए ठोस कतार के साथ नौकरियों का निर्धारण
<पी> सबसे पहले, यह एक छोटे से पुनर्कथन का समय है। सॉलिड क्यू आपके डेटाबेस का उपयोग करता है - और केवल आपके डेटाबेस का - जॉब डेटा संग्रहीत करने के लिए। यह जो कुछ भी करता है वह किसी न किसी डेटाबेस तालिका द्वारा समर्थित होता है। नौकरियों को शेड्यूल करना - यानी, भविष्य में किसी विशिष्ट बिंदु पर चलने के लिए नौकरियों को नामित करना - कोई अलग बात नहीं है। कोई भी निर्धारित कार्य solid_queue_scheduled_executions में संग्रहीत होता है . <पी> यह तालिका लगभग solid_queue_ready_executions के समान है टेबल. एकमात्र अंतर scheduled_at को जोड़ने का है कॉलम, जो हमें बताता है कि किसी निर्धारित कार्य को कब निष्पादित किया जाना चाहिए। आइए यह देखकर पुष्टि करें कि जब हम कोई कार्य शेड्यूल करते हैं तो क्या होता है। <पी> वहां कोई आश्चर्य नहीं है. सॉलिड क्यू solid_queue_scheduled_executions में एक नई पंक्ति जोड़ता है तालिका, जिसमें वह डेटा शामिल है जिसकी हम अपेक्षा करते हैं। लेकिन हम मौजूदा ऐसे रिकॉर्ड से सही समय पर काम चलाने तक कैसे जा सकते हैं? <पी> हमें एक ऐसी प्रक्रिया की आवश्यकता है जो solid_queue_scheduled_executions पर लगातार मतदान करती रहे टेबल. उस प्रक्रिया को डिस्पैचर कहा जाता है, और यह निर्धारित कार्यों को समय पर निष्पादित करने के लिए जिम्मेदार है। यह तब शुरू होता है जब सॉलिड क्यू शुरू होती है - किसी अतिरिक्त कॉन्फ़िगरेशन की आवश्यकता नहीं होती है। हालाँकि, यदि आवश्यक हो तो आप एक विशिष्ट कॉन्फ़िगरेशन के साथ सॉलिड क्यू चलाकर केवल डिस्पैचर प्रक्रिया शुरू कर सकते हैं। <पी> यदि आप सोच रहे थे कि डिस्पैचर प्रक्रिया की निगरानी कैसे की जाती है, तो यह उपयुक्त नाम Supervisor की जिम्मेदारी है। . यह कार्यकर्ता प्रक्रियाओं और डिस्पैचर्स सहित सॉलिड क्यू के भीतर चल रही किसी भी प्रक्रिया का ट्रैक रखता है। <पी> तो, डिस्पैचर वास्तव में कैसे काम करता है? यह poll को परिभाषित करता है अनुसूचित नौकरियों की लगातार जांच करने के लिए लूप के भीतर विधि को बुलाया जाता है। मतदान कोड कई वर्गों और मॉड्यूलों में फैला हुआ है, लेकिन अत्यधिक सरलीकृत रूप में, यह इस तरह दिखता है: <पी> 'तैयार' निर्धारित निष्पादन को पुनः प्राप्त करने की क्वेरी सीधी है। <पी> तो, scheduled_at के साथ कोई भी निर्धारित कार्य अतीत में भेजने के लिए तैयार है. जैसा कि हमने इस श्रृंखला के भाग एक में बताया था, जब सॉलिड क्यू कोई कार्य भेजता है, तो यह एक ReadyExecution बनाता है संबंधित ScheduledExecution को रिकॉर्ड करें और नष्ट कर दें रिकार्ड. ReadyExecution फिर नियमित कार्यकर्ता प्रक्रियाओं द्वारा रिकॉर्ड उठाया जाता है, और संबंधित कार्य चलता है। <पी> अब तक, बहुत अच्छा. अनुसूचित नौकरियाँ वास्तव में उतनी जटिल नहीं हैं! आइए कुछ अधिक जटिल चीज़ों पर नज़र डालें:आवर्ती कार्य। आवर्ती कार्य
<पी> आवर्ती कार्य पृष्ठभूमि जॉब प्रोसेसर के लिए अक्सर अनुरोधित सुविधा है। सीधे शब्दों में कहें तो, ये पृष्ठभूमि की नौकरियां हैं जिन्हें आवर्ती शेड्यूल पर चलना चाहिए। वे क्रॉन जॉब्स के समान हैं जिसमें आप एक शेड्यूल परिभाषित करते हैं (जैसे कि हर पांच मिनट में, हर दिन दोपहर में, और इसी तरह) कि काम कब होना चाहिए। <पी> सॉलिड क्यू में, आप config/recurring.yml का उपयोग करके अपनी आवर्ती नौकरियों को कॉन्फ़िगर करते हैं फ़ाइल. उदाहरण के लिए, यदि हम CleanupData चलाना चाहते हैं हर दिन दोपहर में काम, हम इसे इसी तरह करेंगे। <पी> सॉलिड क्यू शेड्यूल अभिव्यक्तियों को पार्स करने के लिए फुगिट का उपयोग करता है, यही कारण है कि 'हर दिन दोपहर में' जैसे मानव-पठनीय शेड्यूल की अनुमति है। निर्धारित कार्यों का उपयोग करते समय, आप चलाए जाने वाले कार्य की श्रेणी और किसी भी कार्य तर्क को परिभाषित करते हैं। उत्कृष्ट SolidQueue आवर्ती कार्य ReadMe अधिक विवरण प्रदान करता है। हम यहां यह सीखने के लिए आए हैं कि यह कैसे काम करता है, तो आइए हुड के नीचे देखें। <पी> आवर्ती कार्यों को RecurringTask द्वारा दर्शाया जाता है मॉडल, जो संबंधित solid_queue_recurring_tasks द्वारा समर्थित है टेबल. उसमें मौजूद कॉलम कॉन्फ़िगरेशन फ़ाइल में उपलब्ध फ़ील्ड के अनुरूप हैं। <पी> जब आप SolidQueue प्रारंभ करते हैं, तो आवर्ती कार्य रिकॉर्ड आपके आवर्ती कार्य कॉन्फ़िगरेशन फ़ाइल के अनुसार बनाए जाते हैं। सही समय पर नौकरियाँ पैदा करने के लिए, हमें एक बार फिर एक नई प्रक्रिया की आवश्यकता है - इस बार शेड्यूलर कहा जाता है। शेड्यूलर डिस्पैचर का सहोदर है, जिसके बारे में हम पहले से ही जानते हैं। यह लगभग उसी तरह से काम करता है:सॉलिड क्यू शुरू होने पर एक नई प्रक्रिया शुरू हो जाती है, और यह प्रक्रिया एक अंतहीन लूप चलाती है। शेड्यूलर और डिस्पैचर के बीच अंतर यह है कि उस लूप के भीतर क्या होता है। जहां डिस्पैचर solid_queue_scheduled_executions पर सवाल उठाता है तालिका, शेड्यूलर क्वेरीज़ solid_queue_recurring_tasks - और सही समय पर कार्य शेड्यूल करता है। तो, शेड्यूलर को वास्तव में कैसे पता चलता है कि सही समय क्या है, और सही कार्य कब शेड्यूल करना है? <पी> उस प्रश्न का उत्तर देने के लिए, हमें कार्यान्वयन की बारीकी से जांच करनी होगी। शेड्यूलर क्लास एक नया RecurringSchedule बनाता है ऑब्जेक्ट जो schedule को परिभाषित करता है विधि. प्रत्येक निर्धारित कार्य के लिए उस विधि को बार-बार बुलाया जाता है। यहां एक सरलीकृत संस्करण है: <पी> आइए इस कोड को सुलझाएं। सॉलिड क्यू Concurrent::ScheduledTask का उपयोग करता है (समवर्ती-रूबी लाइब्रेरी से) एक नया थ्रेड उत्पन्न करने के लिए। वह थ्रेड आवर्ती कार्य के शेड्यूल द्वारा निर्दिष्ट समय पर चलने के लिए निर्धारित है। जब वह थ्रेड चलता है, तो यह पहले अगले आवर्ती कार्य को शेड्यूल करने के लिए पुनरावर्ती रूप से एक और थ्रेड उत्पन्न करता है। फिर, यह 'वर्तमान' निर्धारित कार्य को कतारबद्ध करता है। <पी> आइए चीजों पर नियंत्रण पाने के लिए एक सरल आवर्ती कार्य का एक उदाहरण देखें। <पी> यदि हम 8:30 पर सॉलिड क्यू शुरू करते हैं, तो शेड्यूल विधि के भीतर चर को निम्नलिखित मान निर्दिष्ट किए जाते हैं। शब्दशः नहीं, ध्यान रखें। हम यहां बहुत सरलीकरण कर रहे हैं। <पी> तो, हमारा बैकग्राउंड थ्रेड अब से तीस मिनट बाद चलने के लिए निर्धारित है, जो कि 9:00 बजे है। जब वह समय घूमता है, तो पृष्ठभूमि थ्रेड निष्पादित होता है। यह thread_task.enqueue(at: 9:00) चलता है - तो CleanupData का एक उदाहरण निष्पादन के लिए कतारबद्ध है. यह स्वयं को thread_schedule.schedule के माध्यम से पुनरावर्ती रूप से भी कॉल करता है . क्योंकि अब 9:00 बज चुके हैं, इस आह्वान के लिए चर बदल गए हैं। <पी> इसलिए, पृष्ठभूमि थ्रेड 10:00 बजे फिर से चलने के लिए निर्धारित है, और चक्र जारी रहता है। आप सोच रहे होंगे कि यदि शेड्यूलिंग थ्रेड समाप्त हो जाए तो क्या होगा, उदाहरण के लिए पुनः तैनाती या सिस्टम क्रैश के दौरान। क्या इससे आपका शेड्यूल नहीं बिगड़ेगा? सौभाग्य से, उत्तर नहीं है। क्रॉन शेड्यूल स्थिर हैं। 'हर घंटे' जैसी अभिव्यक्ति हमेशा 10:00, 11:00, 12:00, इत्यादि पर आधारित होती है, भले ही सॉलिड क्यू कब शुरू हो। शेड्यूलिंग थ्रेड में कोई भी रुकावट उसमें बदलाव नहीं लाती। <पी> यहां कुछ अन्य कार्यान्वयन विवरण दिए गए हैं जिनके बारे में पता होना चाहिए। सबसे पहले, किसी आवर्ती कार्य को निष्पादित करने से पहले उसकी अगली घटना को शेड्यूल करने का यह पैटर्न गुडजॉब से प्रेरित है। दूसरा, RecurringTask.enqueue कोई नया Job नहीं बनाता और ReadyExecution जैसा आप उम्मीद कर सकते हैं वैसा ही रिकॉर्ड करें। इसके बजाय, यह एक और रिकॉर्ड बनाता है, जिसका नाम है RecurringExecution . <पी> यह रिकॉर्ड पूरी तरह से आवर्ती कार्यों को कई बार निष्पादित करने से बचने के लिए है। इसका सूचकांक task_key पर है और run_at उस उद्देश्य को पूरा करने के लिए अद्वितीय बाधाओं के साथ। ए RecurringTask केवल तभी कतारबद्ध किया जाता है जब कोई पूर्व RecurringExecution न हो एक ही समय और एक ही काम के लिए। <पी> चौकस पाठक देखेंगे कि यह कोड स्निपेट सॉलिड क्यू में एक सीमा की ओर इशारा करता है। यानी, यदि आप अपने क्रॉन-शैली कार्यों को चलाने के लिए बैकएंड के रूप में सॉलिड क्यू का उपयोग नहीं कर रहे हैं - हां, आप ऐसा कर सकते हैं - सॉलिड क्यू यह गारंटी नहीं दे सकता है कि आवर्ती नौकरियां केवल एक बार ही कतार में हैं। यदि आप स्वयं को ऐसी स्थिति में पाते हैं, तो आपको इसके प्रति सचेत हो जाना चाहिए। <पी> आप यह भी सोच रहे होंगे कि यदि शेड्यूलर प्रक्रिया समाप्त हो जाती है या समाप्त हो जाती है - उदाहरण के लिए, तैनाती के दौरान क्या होता है। चूँकि पुनरावृत्तियाँ एक थ्रेड द्वारा प्रबंधित की जाती हैं, तो क्या थ्रेड ब्रेक शेड्यूल समाप्त नहीं हो जाएगा? सौभाग्य से, इसका उत्तर नहीं है। समवर्ती नियंत्रण
<पी> आइए सॉलिड क्यू की एक अंतिम विशेषता, अर्थात् समवर्ती नियंत्रण पर नजर डालें। कभी-कभी, आप यह सीमित करना चाहते हैं कि एक निश्चित प्रकार की कितनी नौकरियां एक साथ चल सकती हैं। आप limits_concurrency के साथ सॉलिड क्यू का उपयोग करके ऐसा कर सकते हैं . <पी> यहां, हम SolidQueue को MyJob का अधिकतम एक इंस्टेंस चलाने के लिए कह रहे हैं प्रत्येक उपयोगकर्ता के लिए. आइए कॉन्फ़िगरेशन की अधिक विस्तार से जांच करें। to :अधिकतम संख्या में नौकरियां जो आप एक साथ चलाना चाहते हैं।key :यह निर्दिष्ट करने के लिए एक आवश्यक तर्क कि किन नौकरियों को एक साथ सीमित किया जाना चाहिए। हमारे उदाहरण में, समान उपयोगकर्ता आईडी वाली नौकरियां एकल समवर्ती निष्पादन तक सीमित हैं। आप किसी भी कार्य तर्क का उपयोग key के रूप में कर सकते हैं , लेकिन स्ट्रिंग्स या प्रतीकों जैसे स्थिरांक की भी अनुमति है।duration :अधिकतम समय जिसके लिए सॉलिड क्यू किसी कार्य के कतारबद्ध होने के बाद समवर्तीता की गारंटी दे सकता है। यदि आपकी नौकरियां इससे अधिक समय तक चलती हैं, तो समवर्ती नियंत्रण लागू नहीं होंगे और नौकरियां ओवरलैप हो सकती हैं। हम बाद में जानेंगे कि क्यों!group :आप विभिन्न कार्य वर्गों में समवर्तीता को सीमित करने के लिए इस विकल्प का उपयोग कर सकते हैं।
<पी> यदि आप अधिक जानना चाहते हैं, तो मैं आपको समवर्ती नियंत्रण दस्तावेज़ का संदर्भ देता हूं। समवर्ती नियंत्रण आसानी से सॉलिड क्यू की सबसे परिष्कृत सुविधा है। यदि निर्धारित कार्यों ने पहले से ही आपका सिर नहीं घुमाया है, तो यह जानना निश्चित रूप से काम करेगा कि यह सुविधा कैसे काम करती है। <पी> आइए बुनियादी बातों से शुरू करें। अन्य सॉलिड क्यू सुविधाओं की तरह, समवर्ती नियंत्रण विभिन्न मॉडलों और उनके संबंधित डेटाबेस तालिकाओं द्वारा समर्थित होते हैं। दो जिनके बारे में आपको विशेष रूप से जागरूक होने की आवश्यकता है वे हैं Semaphore और BlockedExecution . <पी> आइए Semaphore पर नजर डालें प्रथम. जैसा कि नाम से पता चलता है, यह गिनती सेमाफोर पैटर्न का कार्यान्वयन है। जब भी सॉलिड क्यू limits_concurrency के साथ किसी कार्य को सूचीबद्ध करता है , यह सबसे पहले एक समवर्ती कुंजी के आधार पर एक सेमाफोर लॉक प्राप्त करने का प्रयास करता है। यह समवर्ती कुंजी limits_concurrency को दिए गए तर्कों पर आधारित है , अर्थात् कार्य वर्ग, कुंजी, और समूह का नाम - यदि कोई प्रदान किया गया था। यदि सेमाफोर उपलब्ध है, तो कार्य कतारबद्ध है। यदि ऐसा नहीं है, तो एक BlockedExecution इसके बजाय रिकॉर्ड बनाया जाता है। <पी> सेमाफोर में value होता है एकाधिक समवर्ती नौकरियों का समर्थन करने के लिए। आप इसे सेमाफोर की शेष क्षमता के रूप में सोच सकते हैं। सेमाफोर प्राप्त करने का अर्थ है उस मूल्य को कम करना, और इसे जारी करने का अर्थ है इसे बढ़ाना। एक सेमाफोर का मान शून्य होने पर उसे अनुपलब्ध माना जाता है। आइए एक उदाहरण देखें कि एक साधारण काम के लिए लॉकिंग तंत्र कैसे काम करता है। <पी> आइए देखें कि यदि हम इस कार्य को लगातार कई बार करने का प्रयास करें तो क्या होता है। MyJob का पहला उदाहरण कतारबद्ध है. अभी तक कोई सेमाफोर नहीं है, इसलिए एक बनाया गया है। इसका प्रारंभिक मान limit - 1 है . चूँकि आपकी सीमा तीन है, सेमाफोर का प्रारंभिक मान दो है।MyJob का दूसरा उदाहरण कतारबद्ध है. सॉलिड क्यू उस कार्य के लिए लॉक प्राप्त करने का प्रयास करता है। कार्य को पंक्तिबद्ध किया जा सकता है क्योंकि मान दो है, जो शून्य से अधिक है। सेमाफोर का मान घटकर एक हो गया है।- हमारी नौकरी का तीसरा उदाहरण कतारबद्ध है। हम पहले जैसी ही प्रक्रिया दोहराते हैं। सेमाफोर का मान अब शून्य है।
MyJob का चौथा उदाहरण कतारबद्ध है. सेमाफोर प्राप्त करना विफल हो जाता है क्योंकि इसका मान अब शून्य है। ए BlockedExecution काम के लिए रिकॉर्ड बनाया जाता है.- हमारे कार्य का पहला उदाहरण समाप्त होता है। जब यह समाप्त हो जाता है, तो यह सेमाफोर जारी करता है, इसलिए सेमाफोर मान एक बार फिर से एक होता है।
- समाप्त होने पर, पहला कार्य उदाहरण किसी भी अवरुद्ध कार्य को जारी करने के लिए एक विधि को भी कॉल करता है।
MyJob का चौथा उदाहरण जारी किया जाता है और फिर से ताला प्राप्त करने का प्रयास करता है। सेमाफोर मान एक है, इसलिए लॉक प्राप्त किया जा सकता है और अवरुद्ध कार्य को कतारबद्ध किया जा सकता है। सेमाफोर मान अब शून्य है।
<पी> कार्य समाप्त होने पर सेमाफोर जारी करने का कोड सीधा है। <पी> एक और विवरण है जिसे हमने अभी तक नहीं छुआ है। सेमाफोर की समाप्ति तिथि क्यों होती है, और हमें limits_concurrency का उपयोग करते समय अवधि निर्धारित करने की आवश्यकता क्यों होती है ? <पी> आइए विचार करें कि क्या होता है जब कोई कार्य अपने सेमाफोर को जारी किए बिना क्रैश हो जाता है - उदाहरण के लिए, जब उस कार्य को संसाधित करने वाला एक कर्मचारी मर जाता है। जब तक हम सेमाफोर को साफ करने के लिए कोई तंत्र नहीं जोड़ते, उस कार्य पर लगा ताला हमेशा के लिए बरकरार रहेगा। सबसे खराब स्थिति में, यह हमेशा के लिए अन्य नौकरियों को संसाधित होने से रोक देगा। <पी> सेमाफोर की एक समाप्ति तिथि होती है जो उस स्थिति से बचने के लिए कार्य परिभाषा में दी गई अवधि के अनुरूप होती है। यदि एक सेमाफोर की समय सीमा समाप्त हो जाती है - जो तब होता है जब कोई नौकरियां कतारबद्ध नहीं होती हैं - सेमाफोर नष्ट हो जाएगा। हम इसके लिए ज़िम्मेदार प्रक्रिया को पहले से ही जानते हैं - यह हमारा मित्र, डिस्पैचर है . यह ConcurrencyMaintenance को इंस्टेंटियेट करता है क्लास, जो दो काम करती है: - सबसे पहले, यह किसी भी समाप्त हो चुके सेमाफोर को हटा देता है।
- दूसरा, यह जांच करेगा कि क्या कोई अवरुद्ध नौकरियां हैं और उन्हें जारी करेगा।
<पी> नौकरियाँ एक-एक करके जारी की जाती हैं, इसलिए समवर्ती सीमाएँ अभी भी कायम रहेंगी। हालाँकि, विचार करें कि यदि आपकी नौकरी दी गई अवधि से अधिक समय तक चलती है तो क्या होगा। उस स्थिति में, सेमाफोर को साफ कर दिया जाएगा, हालांकि काम फिर भी चलेगा। यदि फिर कोई अन्य कार्य कतार में रखा जाता है, तो वे कार्य ओवरलैप हो जाएंगे। AppSignal के साथ रेल के लिए ठोस कतार की निगरानी
<पी> जैसा कि हमने स्थापित किया है, सॉलिड क्यू बहुत कुछ कर सकती है। हालाँकि, इन सभी गतिशील भागों के साथ, निगरानी महत्वपूर्ण हो जाती है। सौभाग्य से, ऐपसिग्नल कार्य निष्पादन समय, थ्रूपुट और विफलता दर के लिए तैयार डैशबोर्ड के साथ सॉलिड क्यू के लिए अंतर्निहित समर्थन प्रदान करता है। बस अपने रेल एप्लिकेशन में AppSignal इंस्टॉल करें, और आप जाने के लिए तैयार हैं। <पी> ऐपसिग्नल स्वचालित रूप से सॉलिड क्यू के आपके उपयोग का पता लगाएगा और एक सक्रिय जॉब डैशबोर्ड बनाएगा जिसमें त्रुटि दर और थ्रूपुट जैसे महत्वपूर्ण मैट्रिक्स के लिए ग्राफ़ होंगे। <पी> 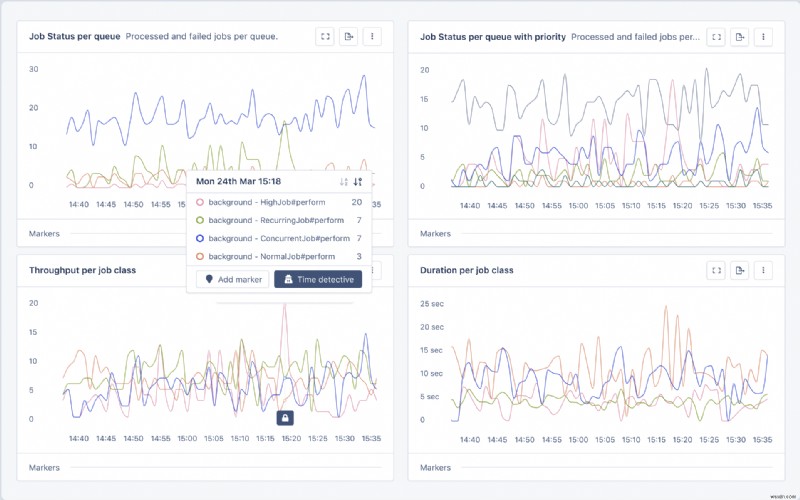 <पी> यदि आप कभी ऐसी नौकरियाँ देखते हैं जो गलत व्यवहार करती हैं - या तो क्योंकि वे धीमी गति से चलती हैं या उनमें बहुत अधिक त्रुटियाँ होती हैं - तो समस्या को प्रभावी ढंग से हल करने के लिए उन्हें एक दर्जा और नियुक्तकर्ता नियुक्त करें। <पी>
<पी> यदि आप कभी ऐसी नौकरियाँ देखते हैं जो गलत व्यवहार करती हैं - या तो क्योंकि वे धीमी गति से चलती हैं या उनमें बहुत अधिक त्रुटियाँ होती हैं - तो समस्या को प्रभावी ढंग से हल करने के लिए उन्हें एक दर्जा और नियुक्तकर्ता नियुक्त करें। <पी> 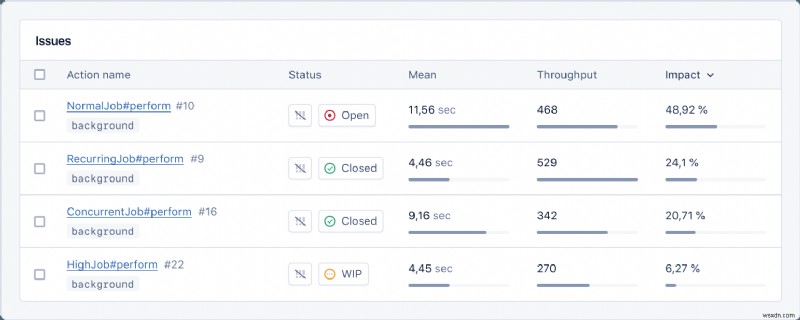 <पी> जाहिर है, कोई समस्या है या नहीं, इसका पता लगाने के लिए आपको पूरे दिन डैशबोर्ड को देखने की ज़रूरत नहीं है। ऐपसिग्नल अलर्ट आपकी सहायता करता है। बस नौकरी मेट्रिक्स, जैसे विफलता दर और नौकरी की अवधि के लिए एक नया अलर्ट बनाएं, और आप पूरी तरह तैयार हैं। <पी>
<पी> जाहिर है, कोई समस्या है या नहीं, इसका पता लगाने के लिए आपको पूरे दिन डैशबोर्ड को देखने की ज़रूरत नहीं है। ऐपसिग्नल अलर्ट आपकी सहायता करता है। बस नौकरी मेट्रिक्स, जैसे विफलता दर और नौकरी की अवधि के लिए एक नया अलर्ट बनाएं, और आप पूरी तरह तैयार हैं। <पी>  <पी> सॉलिड क्यू आपके एप्लिकेशन में बिना किसी परेशानी के शक्तिशाली जॉब प्रोसेसिंग जोड़ने के लिए अद्भुत है। जब निगरानी की बात आती है तो AppSignal भी ऐसा ही करता है!
<पी> सॉलिड क्यू आपके एप्लिकेशन में बिना किसी परेशानी के शक्तिशाली जॉब प्रोसेसिंग जोड़ने के लिए अद्भुत है। जब निगरानी की बात आती है तो AppSignal भी ऐसा ही करता है! समापन
<पी> सॉलिड क्यू की उन्नत सुविधाओं की खोज में हमने काफी कुछ कवर किया है। निर्धारित नौकरियों से लेकर जटिल निर्भरता श्रृंखलाओं तक, प्रत्येक सुविधा उस ठोस आधार पर निर्मित होती है जिसकी चर्चा हमने भाग एक में की थी। जैसा कि हमने देखा है, जॉब प्रोसेसिंग बैकएंड बनाना आसान नहीं है। लेकिन सॉलिड क्यू सोर्स कोड और उसके कामकाज में गहराई से गोता लगाने से, हमें इसमें शामिल चुनौतियों के बारे में समझ और कुछ सराहना मिली है। <पी> किसी भी स्थिति में, अपने उत्कृष्ट डेटाबेस डिज़ाइन और प्रक्रिया समन्वय के कारण, सॉलिड क्यू रेल पारिस्थितिकी तंत्र के लिए एक अद्भुत अतिरिक्त है। यह अपने मूल वादे को बनाए रखते हुए आपको आवश्यक उपकरण प्रदान करता है:सरलता और विश्वसनीयता, बाहरी निर्भरता के बिना। <पी> हैप्पी कोडिंग!