डेटा संरचना क्या है?
डेटा संरचना डेटा को व्यवस्थित और एक्सेस करने का एक विशिष्ट तरीका है ।
उदाहरणों में शामिल हैं:
- सरणी
- बाइनरी ट्री
- हैश
विभिन्न डेटा संरचनाएं अलग-अलग कार्यों में उत्कृष्ट होती हैं।
उदाहरण के लिए, यदि आप शब्दकोश (शब्द और परिभाषा), या फ़ोन बुक (व्यक्ति का नाम और संख्या) जैसा दिखने वाला डेटा संग्रहीत करना चाहते हैं, तो हैश बहुत अच्छा है।
यह जानना कि कौन-सी डेटा संरचनाएं उपलब्ध हैं , और उनमें से प्रत्येक की विशेषताएं , आपको एक बेहतर रूबी डेवलपर बना देगा।
इस लेख में आप यही सीखेंगे!
सरणी को समझना
सरणी पहली डेटा संरचना है जिसके बारे में आप तब सीखते हैं जब आप प्रोग्रामिंग के बारे में पढ़ना शुरू करते हैं।
Arrays स्मृति के एक सन्निहित भाग का उपयोग करते हैं जहाँ वस्तुओं को एक के बाद एक उनके बीच अंतराल के बिना संग्रहीत किया जाता है।
निचले स्तर की प्रोग्रामिंग भाषाओं के विपरीत, सी की तरह, रूबी आपकी मेमोरी को प्रबंधित करने, अधिकतम सरणी आकार का विस्तार करने और तत्वों को हटाने पर इसे कॉम्पैक्ट करने का पूरा काम करती है।
उपयोग करता है :
- अधिक उन्नत डेटा संरचनाओं के आधार के रूप में
- लूप चलाने से परिणाम एकत्रित करने के लिए
- आइटम एकत्रित करना
आपको हर जगह सरणियाँ मिलेंगी, जैसे split &chars विधियाँ, जो एक स्ट्रिंग को वर्णों की एक सरणी में विभाजित करती हैं।
उदाहरण :
out = []
10.times { |i| out << i }
out
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
निम्न तालिका आपको दिखाती है कि सरणी का आकार बढ़ने पर विभिन्न सरणी संचालन कैसे व्यवहार करते हैं।
यदि आप समय जटिलता संकेतन से परिचित नहीं हैं तो इस लेख को पढ़ें।
सरणी के लिए समय जटिलता :
| ऑपरेशन | जटिलता |
|---|---|
| पुश | O(1) |
| पॉप | O(1) |
| पहुंच | O(1) |
| ढूंढें | O(n) |
| हटाएं | O(n) |
यह सहायक क्यों है?
क्योंकि यह आपको सरणियों की प्रदर्शन विशेषताओं को बताता है।
यदि आप बहुत कुछ कर रहे हैं find एक विशाल सरणी पर संचालन जो धीमा होने वाला है...
लेकिन अगर आप जानते हैं कि कौन सी अनुक्रमणिका का उपयोग करना है, तो O(1) के कारण एक सरणी तेज़ होने वाली है समय जटिलता।
इस मानदंड के साथ अपनी डेटा संरचना चुनें :
- प्रदर्शन विशेषताएँ => आप डेटा के साथ क्या कर रहे हैं? आपका डेटासेट कितना बड़ा है?
- आपके डेटा का आकार और रूप => आप किस प्रकार के डेटा के साथ काम कर रहे हैं? क्या आप अपने डेटा को फिर से व्यवस्थित कर सकते हैं ताकि यह एक बेहतर डेटा संरचना में फिट हो सके?
हैश डेटा संरचना
क्या आपके पास देश कोड और देश के नामों के बीच मानचित्रण है?
या हो सकता है कि आप केवल सामान गिनना चाहते हों।
ठीक यही हैश के लिए मददगार होता है!
हैश एक डेटा संरचना है जहां हर मान की एक कुंजी होती है और यह कुंजी कुछ भी हो सकती है , जैसे एक स्ट्रिंग, एक पूर्णांक, एक प्रतीक, आदि।
यह कैसे काम करता है?
एक हैश आपकी कुंजी को एक संख्या में बदल देता है (hash . का उपयोग करके रूबी में विधि) और फिर उस संख्या को अनुक्रमणिका के रूप में उपयोग करता है। लेकिन आपको अपने रूबी कार्यक्रमों में हैश का उपयोग करने में सक्षम होने के लिए यह समझने की आवश्यकता नहीं है।
उपयोग करता है :
- एक स्ट्रिंग में वर्णों की गणना करना
- शब्दों को परिभाषाओं, नामों से फोन नंबरों, आदि पर मैप करना।
- एक सरणी के अंदर डुप्लीकेट ढूंढें
उदाहरण :
"aaabcd"
.each_char
.with_object(Hash.new(0)) { |ch, hash| hash[ch] += 1 }
# {"a"=>3, "b"=>1, "c"=>1, "d"=>1}
समय की जटिलता :
| ऑपरेशन | जटिलता |
|---|---|
| store | O(1) |
| पहुंच | O(1) |
| हटाएं | O(1) |
| ढूंढें (मान) | O(n) |
निरंतर O(1) . के कारण प्रदर्शन के मामले में हैश सबसे उपयोगी डेटा संरचनाओं में से एक है स्टोर, डिलीट और एक्सेस टाइम।
हैश के संदर्भ में खोजें का अर्थ है कि आप एक विशिष्ट मान की तलाश कर रहे हैं।
ढेर
स्टैक प्लेटों के ढेर की तरह होता है, आप एक प्लेट को दूसरे के ऊपर रख देते हैं और आप केवल प्लेट को ऊपर से हटा सकते हैं।
यह पहले की तुलना में अधिक उपयोगी है!
उपयोग करता है :
- पुनरावर्ती विधियों को एक नियमित लूप से बदल देता है
- सबसे हाल के काम को सबसे ऊपर छोड़कर बाकी बचे काम पर नज़र रखें
- सरणी को उल्टा करें
उदाहरण :
stack = [1,2,3,4,5]
(1..stack.size).map { stack.pop }
# [5, 4, 3, 2, 1]
हां, आप reverse . का उपयोग कर सकते हैं इसके बजाय।
यह आपको स्टैक की इस विशेष विशेषता को दिखाने के लिए केवल एक उदाहरण है।
समय की जटिलता :
| ऑपरेशन | जटिलता |
|---|---|
| पुश | O(1) |
| पॉप | O(1) |
| ढूंढें | --- |
| पहुंच | --- |
ध्यान दें कि स्टैक (और कतार) में केवल दो ऑपरेशन होते हैं, insert &delete , या push &pop ।
हालांकि स्टैक के अंदर खोजना संभव है, यह बहुत दुर्लभ है।
बाइनरी ट्री का उपयोग कैसे करें
अधिकांश रूबी डेवलपर्स ने शायद बाइनरी ट्री के बारे में सुना होगा, लेकिन उन्होंने कभी इसका इस्तेमाल नहीं किया।
ऐसा क्यों है?
सबसे पहले, हमारे पास अंतर्निहित बाइनरी ट्री कार्यान्वयन नहीं है।
दूसरा, बाइनरी ट्री रोज़मर्रा की प्रोग्रामिंग चुनौतियों के लिए उतना मददगार नहीं है, जितना कि एरेज़ और हैश के विपरीत जो आप हर समय इस्तेमाल करते हैं।
लेकिन बाइनरी ट्री एक बहुत ही दिलचस्प डेटा संरचना हैं ।
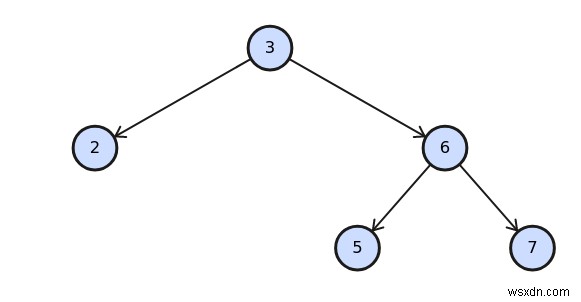
वास्तव में, कई विविधताएं हैं, जैसे ट्री (अगले भाग में शामिल), बी-ट्री (डेटाबेस में प्रयुक्त) और हीप जैसे मल्टीवे ट्री।
उपयोग करता है :
- डेटा संपीड़न
- रूटिंग टेबल
- एब्स्ट्रैक्ट सिंटैक्स ट्री (एएसटी)
उदाहरण :
# https://github.com/jamesconant/bstree require 'bstree' root = Bstree::Node.new(5) root.insert(2) root.insert(7) root.search(3) # nil
समय की जटिलता :
| ऑपरेशन | जटिलता |
|---|---|
| डालें | O(log n) |
| हटाएं | O(log n) |
| ढूंढें | O(log n) |
| पहुंच | --- |
एक संतुलित बाइनरी ट्री तब होता है जब सभी नोड्स में दो बच्चे होते हैं और सभी पत्तियों का स्तर समान होता है
यदि कोई पेड़ असंतुलित हो जाता है, तो प्रदर्शन O(n) . तक कम हो जाता है ।
स्व-संतुलित बाइनरी ट्री . में (रेड-ब्लैक ट्री या AVL ट्री की तरह), हर ऑपरेशन में पेड़ की ऊंचाई (या लेवल) के अनुपात में समय लगता है।
ध्यान दें कि कैसे कोई एक्सेस टाइम नहीं है क्योंकि किसी नोड को एक्सेस करने के लिए आपको सबसे पहले उसे ढूंढना होगा...
उस स्थिति में, आपके पास O(log n) . होगा पहुंच के लिए।
लेकिन अगर किसी विशिष्ट नोड के लिए एक संदर्भ (चर के रूप में) रखें, तो वह O(1) . होगा पहुंच का समय।
द ट्री डेटा स्ट्रक्चर
ट्री एक विशेष पेड़ जैसी डेटा संरचना है।
यह शब्दों के साथ काम करने और फिर जल्दी से उपसर्ग से शुरू होने वाले शब्दों की खोज करने या पूरा शब्द खोजने में मददगार होता है।
उपयोग करता है :
- शब्दों का खेल
- वर्तनी जांचकर्ता
- स्वतः पूर्ण सुझाव
उदाहरण :
# https://github.com/gonzedge/rambling-trie
require 'rambling-trie'
trie = Rambling::Trie.create('words.txt')
trie.include?('chocolate')
# true
trie.include?('salmon')
# true
समय की जटिलता :
| ऑपरेशन | जटिलता |
|---|---|
| जोड़ें | O(k) |
| शामिल है? | O(k) |
| शब्द | O(k) |
इस तालिका में, मैं k . का उपयोग करता हूं इनपुट स्ट्रिंग के आकार को दर्शाने के लिए, जबकि n डेटा संरचना के आकार को स्वयं दर्शाने के लिए उपयोग किया जाता है।
तो apple शब्द के लिए , k 5 होगा।
सारांश
आपने सामान्य डेटा संरचनाओं, उनके मुख्य उपयोगों और विशेषताओं और रूबी में उनका उपयोग करने के तरीके के बारे में सीखा है।
जब आप इस नए ज्ञान को लागू करते हैं तो आप समस्याओं को तेजी से हल करने में सक्षम होंगे!
क्या आप इस पोस्ट को मेरे लिए साझा कर सकते हैं यदि आपको यह मददगार लगी हो?
धन्यवाद 🙂