समय जटिलता सबसे दिलचस्प अवधारणाओं में से एक है जिसे आप कंप्यूटर विज्ञान से सीख सकते हैं, और आपको इसे समझने के लिए किसी डिग्री की आवश्यकता नहीं है!
यह दिलचस्प है क्योंकि इससे आपको यह देखने में मदद मिलती है कि कोई विशेष एल्गोरिदम या प्रोग्राम धीमा क्यों हो सकता है और इसे और तेज़ बनाने के लिए आप क्या कर सकते हैं।
आप इसे अपने कोड पर लागू कर सकते हैं।
यह सभी फैंसी एल्गोरिदम से परे है जो आप कंप्यूटर विज्ञान की पुस्तकों में पाते हैं, जैसा कि मैं इस लेख में बाद में आपके लिए प्रदर्शित करूँगा।
लेकिन पहले हमें इस बारे में बात करने की ज़रूरत है कि क्या धीमा है और क्या तेज़ है।
धीमा बनाम तेज़
1 मिलियन संख्याओं को 150ms (मिलीसेकंड) में क्रमित करना धीमा है या तेज़?
मुझे लगता है कि यह बहुत तेज़ है, लेकिन यह वह प्रश्न नहीं है जिसका उत्तर समय जटिलता देने की कोशिश कर रहा है।
हम जानना चाहते हैं कि "इनपुट आकार" बढ़ने के साथ एक एल्गोरिदम कैसा प्रदर्शन करने वाला है।
जब हम "इनपुट आकार" के बारे में बात करते हैं तो हम फ़ंक्शन या विधि के लिए तर्कों के बारे में बात कर रहे होते हैं। यदि कोई विधि एक स्ट्रिंग को तर्क के रूप में लेती है तो वह इनपुट है, और स्ट्रिंग की लंबाई इनपुट आकार है।
बिग ओ नोटेशन
बिग ओ नोटेशन के साथ हम एल्गोरिदम को उनके प्रदर्शन के अनुसार वर्गीकृत कर सकते हैं।
यह इस तरह दिखता है:
O(1)
इस मामले में O(1) एक "निरंतर समय" एल्गोरिथ्म का प्रतिनिधित्व करता है।
इसका मतलब है कि एल्गोरिथम को अपना काम पूरा करने में हमेशा एक ही समय लगेगा, भले ही उसे कितना भी काम करना पड़े।
दूसरा "रैखिक समय" है:
O(n)
जहां "एन" इनपुट के आकार (स्ट्रिंग आकार, सरणी आकार, आदि) का प्रतिनिधित्व करता है। इसका मतलब है कि एल्गोरिथम इनपुट आकार के संबंध में 1:1 में अपना काम पूरा करेगा, इसलिए इनपुट आकार को दोगुना करने से काम पूरा होने में लगने वाला समय भी दोगुना हो जाएगा।
यहां एक तालिका है :
| Notation | <वें संरेखण ="बाएं">नामविवरण | |
|---|---|---|
| O(1) | स्थिर | हमेशा उतना ही समय लगता है। |
| O(log n) | लघुगणक | प्रत्येक लूप पुनरावृत्ति (द्विआधारी खोज) के बाद कार्य की मात्रा को 2 से विभाजित किया जाता है। |
| O(n) | रैखिक | कार्य पूरा करने का समय इनपुट आकार के संबंध में 1 से 1 के अनुपात में बढ़ता है। |
| O(n log n) | रैखिकीय | यह एक नेस्टेड लूप है, जहां इनर लूप log n में चलता है समय। उदाहरणों में क्विकसॉर्ट, मर्जसॉर्ट और हीपसॉर्ट शामिल हैं। |
| O(n^2) | द्विघात | कार्य पूरा करने का समय input size ^ 2 में बढ़ता है संबंध। आप इसे तब भी पहचान सकते हैं जब आपके पास एक लूप होता है जो सभी तत्वों पर जाता है और लूप का प्रत्येक पुनरावृत्ति भी प्रत्येक तत्व पर जाता है। आपके पास नेस्टेड लूप है। |
| O(n^3) | घन | n^2 के समान , लेकिन समय एक n^3 . में बढ़ता है इनपुट आकार के संबंध में इसे पहचानने के लिए ट्रिपल नेस्टेड लूप की तलाश करें। |
| O(2^n) | घातांक | कार्य पूरा करने का समय 2 ^ input size in में बढ़ता है संबंध। यह n^2 . की तुलना में बहुत धीमा है , इसलिए उन्हें भ्रमित न करें! एक उदाहरण पुनरावर्ती फाइबोनैचि एल्गोरिथम है। |
एल्गोरिदम विश्लेषण
यदि आप इनपुट के बारे में "n" तत्वों की एक सरणी के रूप में सोचते हैं, तो आप इसके लिए अपना अंतर्ज्ञान विकसित करना शुरू कर सकते हैं।
कल्पना कीजिए कि आप उन सभी तत्वों को खोजना चाहते हैं जो सम संख्याएं हैं, ऐसा करने का एकमात्र तरीका यह है कि प्रत्येक तत्व को एक बार पढ़कर देखें कि क्या यह स्थिति से मेल खाता है।
[1,2,3,4,5,6,7,8,9,10].select(&:even?)
आप संख्याओं को छोड़ नहीं सकते हैं क्योंकि आप कुछ संख्याओं को याद कर सकते हैं जिन्हें आप ढूंढ रहे हैं, जिससे यह एक रैखिक समय एल्गोरिदम बनाता है O(n) ।
एक ही समस्या के 3 अलग-अलग समाधान
अलग-अलग उदाहरणों का विश्लेषण करना दिलचस्प है, लेकिन इस विचार को समझने में वास्तव में जो मदद करता है वह यह देखना है कि हम विभिन्न समाधानों का उपयोग करके एक ही समस्या को कैसे हल कर सकते हैं।
हम स्क्रैबल सॉल्यूशन चेकर के लिए 3 कोड उदाहरण तलाशने जा रहे हैं।
स्क्रैबल एक ऐसा गेम है जिसमें पात्रों की एक सूची दी गई है (जैसे ollhe ) आपसे शब्द बनाने के लिए कहता है (जैसे hello ) इन वर्णों का उपयोग करना।
यह रहा पहला समाधान :
def scramble(characters, word)
word.each_char.all? { |c| characters.count(c) >= word.count(c) }
end
क्या आप जानते हैं कि इस कोड की समय जटिलता क्या है? कुंजी count . में है विधि, इसलिए सुनिश्चित करें कि आप समझते हैं कि वह विधि क्या करती है।
उत्तर है:O(n^2) ।
और उसका कारण यह है कि each_char . के साथ हम स्ट्रिंग में सभी वर्णों पर जा रहे हैं word . वह अकेला एक रैखिक समय एल्गोरिथ्म होगा O(n) , लेकिन ब्लॉक के अंदर हमारे पास count . है विधि।
यह विधि प्रभावी रूप से एक और लूप है जो स्ट्रिंग में सभी वर्णों को गिनने के लिए फिर से जाता है।
दूसरा समाधान
ठीक है।
हम कैसे बेहतर कर सकते हैं? क्या हमें कुछ लूपिंग से बचाने का कोई तरीका है?
पात्रों को गिनने के बजाय हम उन्हें हटा सकते हैं, इस तरह हमारे पास जाने के लिए कम वर्ण हैं।
यह रहा दूसरा समाधान :
def scramble(characters, word)
characters = characters.dup
word.each_char.all? { |c| characters.sub!(c, "") }
end
यह वाला थोड़ा और दिलचस्प है। यह count . से बहुत तेज़ होगा सर्वोत्तम स्थिति में संस्करण, जहां हम जिन वर्णों की तलाश कर रहे हैं, वे स्ट्रिंग की शुरुआत के करीब हैं।
लेकिन जब अक्षर सभी अंत में हों, तो वे word . में कैसे पाए जाते हैं इसके विपरीत क्रम में हैं , प्रदर्शन count . के समान होगा संस्करण, इसलिए हम कह सकते हैं कि यह अभी भी एक O(n^2) . है एल्गोरिथम।
हमें उस मामले के बारे में चिंता करने की ज़रूरत नहीं है जहां word . में कोई भी वर्ण नहीं है उपलब्ध हैं, क्योंकि all? जैसे ही sub! . मेथड बंद हो जाएगी रिटर्न false . लेकिन आपको यह तभी पता चलेगा जब आपने रूबी का व्यापक अध्ययन किया हो, जो कि रूबी के नियमित पाठ्यक्रमों की पेशकश से कहीं अधिक है।
चलो एक और दृष्टिकोण के साथ प्रयास करें
क्या होगा अगर हम ब्लॉक के अंदर किसी भी प्रकार की लूपिंग को हटा दें? हम हैश के साथ ऐसा कर सकते हैं।
def scramble(characters, word)
available = Hash.new(1)
characters.each_char { |c| available[c] += 1 }
word.each_char.all? { |c| available[c] -= 1; available[c] > 0 }
end
हैश मान पढ़ना और लिखना एक O(1) है ऑपरेशन, जिसका अर्थ है कि यह बहुत तेज़ है, विशेष रूप से लूपिंग की तुलना में।
हमारे पास अभी भी दो लूप हैं :
एक हैश टेबल बनाने के लिए, और एक इसे जांचने के लिए। क्योंकि ये लूप नेस्टेड नहीं हैं, यह एक O(n) है एल्गोरिथम।
यदि हम इन 3 समाधानों को बेंचमार्क करते हैं तो हम देख सकते हैं कि हमारा विश्लेषण परिणामों से मेल खाता है:
hash 1.216667 0.000000 1.216667 ( 1.216007) sub 6.240000 1.023333 7.263333 ( 7.268173) count 222.866644 0.073333 222.939977 (223.440862)
ये रहा एक लाइन चार्ट:
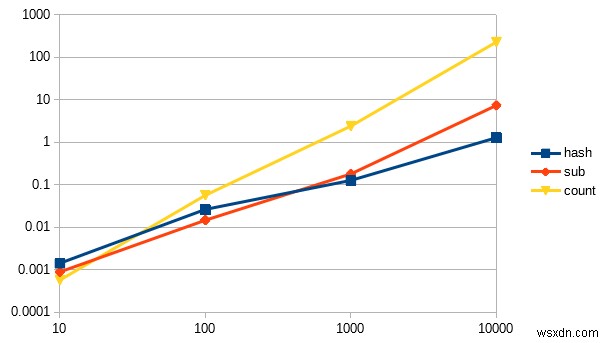
कुछ बातों पर ध्यान दें :
- Y अक्ष (ऊर्ध्वाधर) दर्शाता है कि कार्य को पूरा करने में कितने सेकंड लगे, जबकि X अक्ष (क्षैतिज) इनपुट आकार का प्रतिनिधित्व करता है।
- यह एक लघुगणकीय चार्ट है, जो एक निश्चित सीमा में मानों को संपीड़ित करता है, लेकिन वास्तव में
countलाइन बहुत तेज है। - इसका कारण मैंने इसे एक लघुगणकीय चार्ट बनाया है ताकि आप एक बहुत ही छोटे इनपुट आकार के साथ एक दिलचस्प प्रभाव की सराहना कर सकें
countवास्तव में तेज़ है!
सारांश
आपने एल्गोरिथम समय जटिलता, बड़े ओ अंकन और समय जटिलता विश्लेषण के बारे में सीखा। आपने कुछ उदाहरण भी देखे जहां हम एक ही समस्या के विभिन्न समाधानों की तुलना करते हैं और उनके प्रदर्शन का विश्लेषण करते हैं।
आशा है कि आपने कुछ नया और दिलचस्प सीखा!
यदि आपने कृपया इस पोस्ट को सोशल मीडिया पर साझा करें और न्यूज़लेटर की सदस्यता लें यदि आपने अभी तक ऐसा नहीं किया है तो मैं आपको इस तरह की और सामग्री भेज सकता हूं।
पढ़ने के लिए धन्यवाद।