Hash Table एक डेटा संरचना है जो डेटा को एक सहयोगी तरीके से संग्रहीत करती है। हैश तालिका में, डेटा को एक सरणी प्रारूप में संग्रहीत किया जाता है, जहां प्रत्येक डेटा मान का अपना विशिष्ट अनुक्रमणिका मान होता है। यदि हम वांछित डेटा की अनुक्रमणिका जानते हैं तो डेटा तक पहुंच बहुत तेज़ हो जाती है।
इस प्रकार, यह एक डेटा संरचना बन जाती है जिसमें डेटा के आकार के बावजूद सम्मिलन और खोज संचालन बहुत तेज़ होते हैं। हैश टेबल एक भंडारण माध्यम के रूप में एक सरणी का उपयोग करता है और एक इंडेक्स उत्पन्न करने के लिए हैश तकनीक का उपयोग करता है जहां एक तत्व डाला जाना है या जहां से स्थित होना है।
हैशिंग
हैशिंग एक ऐसी तकनीक है जो प्रमुख मानों की एक श्रृंखला को एक सरणी के अनुक्रमित की श्रेणी में परिवर्तित करती है। हम प्रमुख मूल्यों की एक श्रृंखला प्राप्त करने के लिए मोडुलो ऑपरेटर का उपयोग करने जा रहे हैं। आकार 20 की हैश तालिका के एक उदाहरण पर विचार करें, और निम्नलिखित वस्तुओं को संग्रहीत किया जाना है। आइटम (कुंजी, मान) प्रारूप में है।
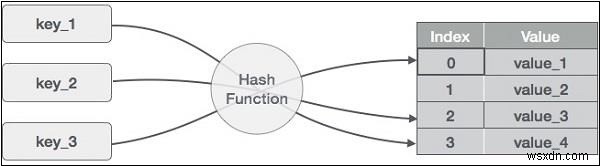
यहां हमारे पास एक हैश फ़ंक्शन है जो कुंजी लेता है और एक तालिका के लिए सूचकांक उत्पन्न करता है। ये सूचकांक हमें बताते हैं कि मूल्य कहाँ संग्रहीत है। अब जब भी हम किसी कुंजी से जुड़े मान की खोज करना चाहते हैं, तो हमें बस कुंजी पर फिर से हैश फ़ंक्शन चलाने और लगभग स्थिर समय में मान प्राप्त करने की आवश्यकता होती है।
हालांकि हैश फ़ंक्शंस को डिज़ाइन करना बहुत कठिन है। आइए एक उदाहरण लेते हैं -
मान लें कि हमारे पास निम्नलिखित हैश फ़ंक्शन है -
उदाहरण
function modBy11(key) {
return key % 11;
} और हम इसे की-वैल्यू पेयर पर चलाना शुरू करते हैं, जिसे हम स्टोर करना चाहते हैं, उदाहरण के लिए -
- (15, 20) - हैश कोड:4
- (25, 39) - हैश कोड:3
- (8, 55) - हैश कोड:8
- (26, 84) - हैश कोड:4
यहां हम देखते हैं कि हमारे पास एक टक्कर है, यानी, अगर हम पहले 15 स्टोर करते हैं और फिर इस हैश फ़ंक्शन के साथ कुंजी 26 का सामना करते हैं, तो यह उसी छेद में इस प्रविष्टि को ठीक करने का प्रयास करेगा। इसे टकराव कहा जाता है। और ऐसी स्थितियों से निपटने के लिए, हमें टकराव से निपटने के तंत्र को परिभाषित करने की आवश्यकता है। कुछ अच्छी तरह से परिभाषित सरल टक्कर समाधान एल्गोरिदम हैं। उदाहरण के लिए -
- लीनियर प्रोबिंग:इस एल्गोरिथम में, हम अगले सेल में देखकर एरे में अगला खाली स्थान खोज सकते हैं जब तक कि हमें एक खाली सेल न मिल जाए। हमारे उदाहरण में, चूंकि 4 पर छेद लिया गया है, हम इसे 5 में भर सकते हैं।
- अलग श्रृंखला:इस कार्यान्वयन में:हम हैश तालिका में प्रत्येक स्थान को एक सूची के साथ जोड़ते हैं। जब भी हमें टक्कर मिलती है, हम इस सूची के अंत में की-वैल्यू पेयर को जोड़ देते हैं। यदि शृंखला लंबी होती जाती है, तो इससे खोज समय बहुत लंबा हो सकता है।
अब जब हम समझ गए हैं कि हैश तालिका कैसे काम करती है और हम टकराव समाधान का उपयोग कैसे कर सकते हैं, आइए हैशटेबल वर्ग को लागू करें।
वे तरीके जिन्हें हम लागू करेंगे
हम इन विधियों को अपने कार्यान्वयन में लागू करेंगे -
- put(key, value):हैश टेबल में एक नया की-वैल्यू पेयर जोड़ता है
- get(key):एक कुंजी से संबद्ध मान प्राप्त करें
- remove(key):टेबल से की-वैल्यू पेयर को हटाता है
- forEach():सभी की-वैल्यू पेयर पर पुनरावृति की अनुमति देता है
- static join():2 हैश टेबल को एक नए में जोड़ने की एक स्थिर विधि


