हमारा काम एक वेब पेज को क्रॉल करना और शब्द की आवृत्ति की गणना करना है। और अंततः सबसे अधिक बार आने वाले शब्दों को पुनः प्राप्त कर रहा है।
सबसे पहले हम अनुरोध और सुंदर सूप मॉड्यूल का उपयोग कर रहे हैं और इन मॉड्यूल की सहायता से वेब-क्रॉलर बना रहे हैं और वेब पेज से डेटा निकाल सकते हैं और एक सूची में स्टोर कर सकते हैं।
उदाहरण कोड
import requests
from bs4 import BeautifulSoup
import operator
from collections import Counter
def my_start(url):
my_wordlist = []
my_source_code = requests.get(url).text
my_soup = BeautifulSoup(my_source_code, 'html.parser')
for each_text in my_soup.findAll('div', {'class':'entry-content'}):
content = each_text.text
words = content.lower().split()
for each_word in words:
my_wordlist.append(each_word)
clean_wordlist(my_wordlist)
# Function removes any unwanted symbols
def clean_wordlist(wordlist):
clean_list =[]
for word in wordlist:
symbols = '!@#$%^&*()_-+={[}]|\;:"<>?/., '
for i in range (0, len(symbols)):
word = word.replace(symbols[i], '')
if len(word) > 0:
clean_list.append(word)
create_dictionary(clean_list)
def create_dictionary(clean_list):
word_count = {}
for word in clean_list:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
c = Counter(word_count)
# returns the most occurring elements
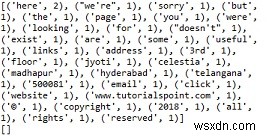
top = c.most_common(10)
print(top)
# Driver code
if __name__ == '__main__':
my_start("https://www.tutorialspoint.com/python3/python_overview.htm/")
आउटपुट
<केंद्र>