वेब साइट के मालिक वेब रोबोट को अपनी साइट के बारे में निर्देश देने के लिए /robots.txt फ़ाइल का उपयोग करते हैं; इसे रोबोट्स एक्सक्लूजन प्रोटोकॉल कहते हैं। यह फ़ाइल कंप्यूटर प्रोग्रामों के लिए एक साधारण पाठ-आधारित अभिगम नियंत्रण प्रणाली है जो स्वचालित रूप से वेब संसाधनों तक पहुँच प्राप्त करती है। ऐसे कार्यक्रमों को स्पाइडर, क्रॉलर आदि कहा जाता है। फ़ाइल उपयोगकर्ता एजेंट पहचानकर्ता को निर्दिष्ट करती है जिसके बाद उन URL की सूची होती है जिन तक एजेंट पहुंच नहीं सकता है।
उदाहरण के लिए
#robots.txt Sitemap: https://example.com/sitemap.xml User-agent: * Disallow: /admin/ Disallow: /downloads/ Disallow: /media/ Disallow: /static/
यह फ़ाइल आमतौर पर आपके वेब सर्वर की शीर्ष-स्तरीय निर्देशिका में रखी जाती है।
पायथन का urllib.robotparser मॉड्यूल RobotFileParser वर्ग प्रदान करता है। यह इस बारे में प्रश्नों का उत्तर देता है कि क्या कोई विशेष उपयोगकर्ता एजेंट robots.txt फ़ाइल को प्रकाशित करने वाली वेब साइट पर URL प्राप्त कर सकता है या नहीं।
निम्नलिखित विधि को RobotFileParser वर्ग में परिभाषित किया गया है
set_url(url)
यह विधि एक robots.txt फ़ाइल का संदर्भ देने वाले URL को सेट करती है।
पढ़ें ()
यह विधि robots.txt URL को पढ़ती है और इसे पार्सर को फीड करती है।
पार्स ()
यह विधि लाइन तर्क को पार्स करती है।
can_fetch()
यदि उपयोगकर्ता robots.txt में निहित नियमों के अनुसार url प्राप्त करने में सक्षम है, तो यह विधि सही है।
mtime()
यह विधि वह समय लौटाती है जब robots.txt फ़ाइल पिछली बार प्राप्त की गई थी।
संशोधित ()
यह विधि उस समय को निर्धारित करती है जब robots.txt को अंतिम बार लाया गया था।
crawl_delay()
यह विधि विचाराधीन उपयोगकर्ता के लिए क्रॉल-विलंब पैरामीटर robots.txt का मान लौटाती है।
request_rate()
यह विधि Request-rate पैरामीटर की सामग्री को नामित tuple RequestRate (अनुरोध, सेकंड) के रूप में लौटाती है।
उदाहरण
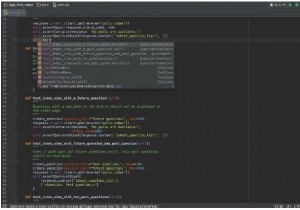
from urllib import parse from urllib import robotparser AGENT_NAME = 'PyMOTW' URL_BASE = 'https://example.com/' parser = robotparser.RobotFileParser() parser.set_url(parse.urljoin(URL_BASE, 'robots.txt')) parser.read()