इस लेख में, हम पायथन 3.x का उपयोग करके मशीन सीखने की मूल बातें सीखेंगे। या पहले।
सबसे पहले, हमें मशीन सीखने के माहौल को स्थापित करने के लिए मौजूदा पुस्तकालयों का उपयोग करने की आवश्यकता है
>>> pip install numpy >>> pip install scipy >>> pip install matplotlib >>> pip install scikit-learn
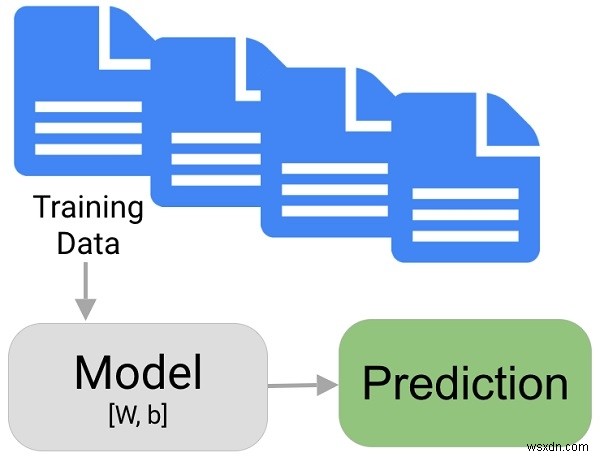
मशीन लर्निंग अनुभवों और तथ्यों के अध्ययन से संबंधित है और भविष्यवाणी प्रदान किए गए इरादों के आधार पर दी जाती है। डेटाबेस जितना बड़ा होगा मशीन लर्निंग मॉडल उतना ही बेहतर होगा।
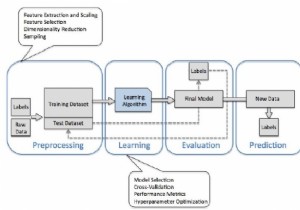
मशीन लर्निंग का प्रवाह
- डेटा साफ़ करना
- डेटासेट को फीड करना
- मॉडल को प्रशिक्षण देना
- डेटासेट का परीक्षण करना
- मॉडल को लागू करना
आइए अब पहचानें कि किस पुस्तकालय का उपयोग किस उद्देश्य के लिए किया जाता है -
सुस्त - इन इनपुट सरणियों पर काम करने के लिए गणितीय कार्यों के विस्तृत संग्रह के साथ विशाल, बहु-आयामी सूचियों और मैट्रिक्स के लिए समर्थन जोड़ता है।
SciPy - एक मुक्त और खुला स्रोत पायथन पुस्तकालय जिसका उपयोग वैज्ञानिक/गणितीय कंप्यूटिंग के लिए किया जाता है। इसमें एल्गोरिदम के अनुकूलन, डेटा के एकीकरण, प्रक्षेप, कुछ विशेष कार्यों और रैखिक बीजगणित के लिए मॉड्यूल शामिल हैं
मैटप्लोटलिब - चार्ट और आंकड़े बनाने के लिए इस्तेमाल किया जाने वाला पुस्तकालय। यह डेटा को प्लॉट करने की अनुमति देता है ताकि मॉडल में बेहतर अंतर्दृष्टि प्राप्त हो सके
स्किट-लर्न - इसमें डेटा को अच्छी तरह से परिभाषित तरीके से वितरित और व्यवस्थित करने के लिए विभिन्न वर्गीकरण, क्लस्टरिंग और रिग्रेशन एल्गोरिदम हैं
आइए अब स्किकिट की मदद से एक बुनियादी मशीन लर्निंग मॉडल बनाते हैं - सीखें। यहां हम इनबिल्ट डेटासेट यानी स्की-किट लर्निंग में उपलब्ध आईरिस और डिजिट डेटासेट लेंगे।
from sklearn import datasets iris = datasets.load_iris() digits = datasets.load_digits()
अब हमारे द्वारा उपयोग किए जाने वाले डेटासेट से डेटा देखने के लिए
print(digits.data)
[[ 0. 0. 5. ... 0. 0. 0.] [ 0. 0. 0. ... 10. 0. 0.] [ 0. 0. 0. ... 16. 9. 0.] ... [ 0. 0. 1. ... 6. 0. 0.] [ 0. 0. 2. ... 12. 0. 0.] [ 0. 0. 10. ... 12. 1. 0.]]
.target फ़ंक्शन हमें उन चीज़ों को देखने की अनुमति देता है जो हम चाहते हैं कि हमारा मॉडल सीखें
digits.target
array([0, 1, 2, ..., 8, 9, 8])
हमारे द्वारा उपयोग किए जाने वाले अंक डेटासेट के आकार तक पहुँचने के लिए
digits.images[0]
array([[ 0., 0., 5., 13., 9., 1., 0., 0.], [ 0., 0., 13., 15., 10., 15., 5., 0.], [ 0., 3., 15., 2., 0., 11., 8., 0.], [ 0., 4., 12., 0., 0., 8., 8., 0.], [ 0., 5., 8., 0., 0., 9., 8., 0.], [ 0., 4., 11., 0., 1., 12., 7., 0.], [ 0., 2., 14., 5., 10., 12., 0., 0.], [ 0., 0., 6., 13., 10., 0., 0., 0.]])
अब चलिए सीखने और भविष्यवाणी करने वाले भाग पर चलते हैं
from sklearn import svm clf = svm.SVC(gamma=0.001, C=100.)
यहां एसवीसी समर्थन वेक्टर वर्गीकरण है जो हमारे मॉडल के लिए एक अंतर्निहित अनुमानक के रूप में कार्य करता है
clf.fit(digits.data[:-1], digits.target[:-1]) SVC(C=100.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma=0.001, kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
सबसे पहले हमें फिट विधि का उपयोग करके मॉडल को डेटासेट के साथ फीड करने की आवश्यकता है ताकि हमारा मॉडल सीख सके यहां हम अंतिम छवि को छोड़कर सभी छवियों को प्रशिक्षण डेटा के रूप में फीड करते हैं जिसका उपयोग हम परीक्षण के उद्देश्य से करेंगे।
अब जब हमारा मॉडल प्रशिक्षित हो गया है तो हम .predict फ़ंक्शन का उपयोग करके परीक्षण डेटा के आउटपुट का अनुमान लगा सकते हैं
clf.predict(digits.data[-1:]) array([8])
अब जब हमारा मॉडल प्रशिक्षित हो गया है तो हम अपने मॉडल की दक्षता और समय-चक्र की गणना कर सकते हैं
निष्कर्ष
इस लेख में, हमने मशीन लर्निंग की कुछ बुनियादी बातों और इसे पायथन में लागू करने के लिए इस्तेमाल की जाने वाली कुछ बुनियादी लाइब्रेरी के बारे में सीखा।