<पी> एलेक्स नडालिन द्वारा
<पी> एलेक्स नडालिन द्वारा वेब एप्लिकेशन सुरक्षा का एक परिचय
<पी> _फ़ोटो द्वारा [अनस्प्लैश](https://unsplash.com/photos/cVMaxt672ss?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" rel='noopener' target='_blank' title=''>लियाम टकर <पी> आप क्रोम, फ़ायरफ़ॉक्स, एज या सफारी जैसे सबसे लोकप्रिय ब्राउज़रों में से एक के साथ काम करने के आदी हो सकते हैं, लेकिन इसका मतलब यह नहीं है कि वहां अलग-अलग ब्राउज़र नहीं हैं। <पी> उदाहरण के लिए, लिंक्स एक हल्का, टेक्स्ट-आधारित ब्राउज़र है जो आपकी कमांड लाइन से काम करता है। लिंक्स के मूल में वही सटीक सिद्धांत निहित हैं जो आपको किसी भी अन्य "मुख्यधारा" ब्राउज़र में मिलेंगे। एक उपयोगकर्ता एक वेब पता (यूआरएल) दर्ज करता है, ब्राउज़र दस्तावेज़ लाता है और उसे प्रस्तुत करता है - एकमात्र अंतर यह है कि लिंक्स विज़ुअल रेंडरिंग इंजन का उपयोग नहीं करता है, बल्कि एक टेक्स्ट-आधारित इंटरफ़ेस का उपयोग करता है, जो Google जैसी वेबसाइटों को इस तरह दिखता है: <पी>
_फ़ोटो द्वारा [अनस्प्लैश](https://unsplash.com/photos/cVMaxt672ss?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText" rel='noopener' target='_blank' title=''>लियाम टकर <पी> आप क्रोम, फ़ायरफ़ॉक्स, एज या सफारी जैसे सबसे लोकप्रिय ब्राउज़रों में से एक के साथ काम करने के आदी हो सकते हैं, लेकिन इसका मतलब यह नहीं है कि वहां अलग-अलग ब्राउज़र नहीं हैं। <पी> उदाहरण के लिए, लिंक्स एक हल्का, टेक्स्ट-आधारित ब्राउज़र है जो आपकी कमांड लाइन से काम करता है। लिंक्स के मूल में वही सटीक सिद्धांत निहित हैं जो आपको किसी भी अन्य "मुख्यधारा" ब्राउज़र में मिलेंगे। एक उपयोगकर्ता एक वेब पता (यूआरएल) दर्ज करता है, ब्राउज़र दस्तावेज़ लाता है और उसे प्रस्तुत करता है - एकमात्र अंतर यह है कि लिंक्स विज़ुअल रेंडरिंग इंजन का उपयोग नहीं करता है, बल्कि एक टेक्स्ट-आधारित इंटरफ़ेस का उपयोग करता है, जो Google जैसी वेबसाइटों को इस तरह दिखता है: <पी> 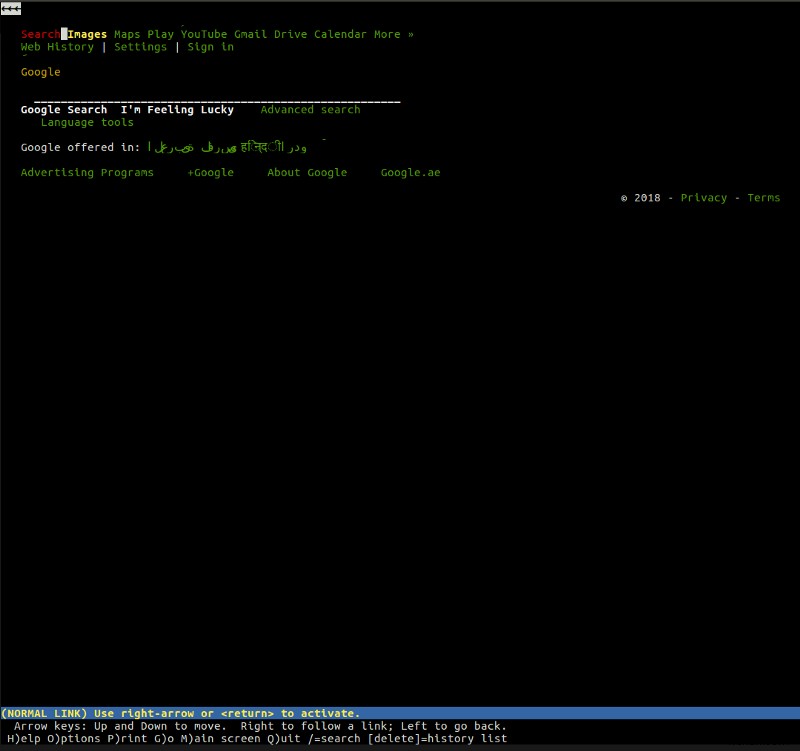 <पी> हम मोटे तौर पर समझते हैं कि एक ब्राउज़र क्या करता है, लेकिन आइए उन कदमों पर करीब से नज़र डालें जो ये सरल एप्लिकेशन हमारे लिए करते हैं।
<पी> हम मोटे तौर पर समझते हैं कि एक ब्राउज़र क्या करता है, लेकिन आइए उन कदमों पर करीब से नज़र डालें जो ये सरल एप्लिकेशन हमारे लिए करते हैं। ब्राउज़र क्या करता है?
<पी> लंबी कहानी को संक्षेप में कहें तो, एक ब्राउज़र का काम मुख्य रूप से होता है:- DNS रिज़ॉल्यूशन
- HTTP एक्सचेंज
- प्रतिपादन
- धोएं और दोहराएं
DNS रिज़ॉल्यूशन
<पी> यह प्रक्रिया सुनिश्चित करती है कि एक बार जब उपयोगकर्ता यूआरएल दर्ज करता है, तो ब्राउज़र को पता चल जाता है कि उसे किस सर्वर से कनेक्ट करना है। ब्राउज़र उसgoogle.com को खोजने के लिए DNS सर्वर से संपर्क करता है 216.58.207.110 में अनुवादित , एक आईपी पता जिससे ब्राउज़र कनेक्ट हो सकता है। HTTP एक्सचेंज
<पी> एक बार जब ब्राउज़र यह पहचान लेता है कि कौन सा सर्वर हमारे अनुरोध को पूरा करेगा, तो वह इसके साथ एक टीसीपी कनेक्शन शुरू करेगा और HTTP एक्सचेंज शुरू करेगा। . यह और कुछ नहीं बल्कि ब्राउज़र के लिए सर्वर के साथ संचार करने का एक तरीका है जिसकी उसे आवश्यकता है, और सर्वर के लिए जवाब देने का एक तरीका है। <पी> HTTP वेब पर संचार करने के लिए सबसे लोकप्रिय प्रोटोकॉल का नाम है, और सर्वर के साथ संचार करते समय ब्राउज़र ज्यादातर HTTP के माध्यम से बात करते हैं। HTTP एक्सचेंज में क्लाइंट (हमारा ब्राउज़र) एक अनुरोध भेजता है , और सर्वर एक प्रतिक्रिया के साथ उत्तर दे रहा है . <पी> उदाहरण के लिए, ब्राउज़र केgoogle.com के पीछे सर्वर से सफलतापूर्वक कनेक्ट होने के बाद , यह एक अनुरोध भेजेगा जो निम्नलिखित जैसा दिखेगा: GET / HTTP/1.1Host: google.comAccept: */*
GET / HTTP/1.1:इस पहली पंक्ति के साथ, ब्राउज़र सर्वर से/स्थान पर दस्तावेज़ को पुनः प्राप्त करने के लिए कहता है , यह कहते हुए कि शेष अनुरोध HTTP/1.1 प्रोटोकॉल का पालन करेगा (यह1.0का भी उपयोग कर सकता है) या2)Host: google.com:यह HTTP/1.1 में अनिवार्य एकमात्र HTTP हेडर है . चूंकि सर्वर एकाधिक डोमेन (google.com) परोस सकता है ,google.co.uk, आदि) ग्राहक यहां उल्लेख करता है कि अनुरोध उस विशिष्ट होस्ट के लिए थाAccept: */*:एक वैकल्पिक हेडर, जहां ब्राउज़र सर्वर को बता रहा है कि वह किसी भी प्रकार की प्रतिक्रिया स्वीकार करेगा। सर्वर में एक संसाधन हो सकता है जो JSON, XML या HTML प्रारूपों में उपलब्ध हो, इसलिए वह जो भी प्रारूप पसंद करे उसे चुन सकता है
HTTP/1.1 200 OKCache-Control: private, max-age=0Content-Type: text/html; charset=ISO-8859-1Server: gwsX-XSS-Protection: 1; mode=blockX-Frame-Options: SAMEORIGINSet-Cookie: NID=1234; expires=Fri, 18-Jan-2019 18:25:04 GMT; path=/; domain=.google.com; HttpOnly
<!doctype html><html">......</html>
200 OK ) और प्रतिक्रिया में कुछ शीर्षलेख जोड़ता है उदाहरण के लिए, यह विज्ञापन देता है कि किस सर्वर ने हमारे अनुरोध को संसाधित किया (Server: gws ), X-XSS-Protection क्या है इस प्रतिक्रिया की नीति इत्यादि इत्यादि। <पी> अभी, आपको प्रतिक्रिया की प्रत्येक पंक्ति को समझने की आवश्यकता नहीं है। हम इस श्रृंखला में बाद में HTTP प्रोटोकॉल, उसके हेडर इत्यादि को कवर करेंगे। <पी> अभी के लिए, आपको बस यह समझने की आवश्यकता है कि क्लाइंट और सर्वर सूचनाओं का आदान-प्रदान कर रहे हैं और वे HTTP के माध्यम से ऐसा करते हैं। रेंडरिंग
<पी> अंतिम, लेकिन कम से कम, प्रतिपादन प्रक्रिया. एक ब्राउज़र कितना अच्छा होगा यदि वह उपयोगकर्ता को केवल मज़ेदार पात्रों की सूची ही दिखाए?<!doctype html><html">......</html>
Content-Type के अनुसार प्रतिक्रिया का प्रतिनिधित्व शामिल होता है शीर्षक. हमारे मामले में, सामग्री प्रकार text/html पर सेट किया गया था , इसलिए हम प्रतिक्रिया में HTML मार्कअप की अपेक्षा कर रहे हैं - जो बिल्कुल वैसा ही है जैसा हम मुख्य भाग में पाते हैं। <पी> यहीं पर ब्राउज़र वास्तव में चमकता है। यह HTML को पार्स करता है, मार्कअप में शामिल अतिरिक्त संसाधनों को लोड करता है (उदाहरण के लिए, लाने के लिए JavaScript फ़ाइलें या CSS दस्तावेज़ हो सकते हैं) और उन्हें जितनी जल्दी हो सके उपयोगकर्ता के सामने प्रस्तुत करता है। <पी> एक बार फिर, अंतिम परिणाम कुछ ऐसा है जिसे औसत व्यक्ति समझ सकता है। <पी>  <पी> जब हम किसी ब्राउज़र के एड्रेस बार में एंटर दबाते हैं तो वास्तव में क्या होता है, इसके अधिक विस्तृत संस्करण के लिए मैं "क्या होता है जब..." पढ़ने का सुझाव दूंगा, जो प्रक्रिया के पीछे के तंत्र को समझाने का एक बहुत विस्तृत प्रयास है। <पी> चूंकि यह सुरक्षा पर केंद्रित एक श्रृंखला है, इसलिए हमने जो अभी सीखा है उस पर मैं एक संकेत देना चाहता हूं:हमलावर आसानी से HTTP एक्सचेंज और रेंडरिंग भाग में कमजोरियों से लाभ उठाते हैं . कमजोरियाँ, और दुर्भावनापूर्ण उपयोगकर्ता, अन्यत्र भी छिपे हुए हैं, लेकिन उन स्तरों पर एक बेहतर सुरक्षा दृष्टिकोण पहले से ही आपको अपनी सुरक्षा स्थिति में सुधार करने में प्रगति करने की अनुमति देता है।
<पी> जब हम किसी ब्राउज़र के एड्रेस बार में एंटर दबाते हैं तो वास्तव में क्या होता है, इसके अधिक विस्तृत संस्करण के लिए मैं "क्या होता है जब..." पढ़ने का सुझाव दूंगा, जो प्रक्रिया के पीछे के तंत्र को समझाने का एक बहुत विस्तृत प्रयास है। <पी> चूंकि यह सुरक्षा पर केंद्रित एक श्रृंखला है, इसलिए हमने जो अभी सीखा है उस पर मैं एक संकेत देना चाहता हूं:हमलावर आसानी से HTTP एक्सचेंज और रेंडरिंग भाग में कमजोरियों से लाभ उठाते हैं . कमजोरियाँ, और दुर्भावनापूर्ण उपयोगकर्ता, अन्यत्र भी छिपे हुए हैं, लेकिन उन स्तरों पर एक बेहतर सुरक्षा दृष्टिकोण पहले से ही आपको अपनी सुरक्षा स्थिति में सुधार करने में प्रगति करने की अनुमति देता है। विक्रेता
<पी> वहां मौजूद 4 सबसे लोकप्रिय ब्राउज़र अलग-अलग विक्रेताओं के हैं:- Google द्वारा Chrome
- मोज़िला द्वारा फ़ायरफ़ॉक्स
- एप्पल द्वारा सफारी
- माइक्रोसॉफ्ट द्वारा एज
 <पी> यह हमें 2 बातें बताता है:
<पी> यह हमें 2 बातें बताता है: - सफारी अपने उपयोगकर्ताओं की सुरक्षा के बारे में पर्याप्त परवाह नहीं करता है (मजाक कर रहा हूं:सेमसाइट कुकीज़ सफारी 12 में उपलब्ध होंगी, जो कि जब तक आप यह लेख पढ़ रहे होंगे तब तक पहले ही जारी हो चुकी होगी)
- एक ब्राउज़र पर भेद्यता को पैच करने का मतलब यह नहीं है कि आपके सभी उपयोगकर्ता सुरक्षित हैं
विक्रेता या मानक बग?
<पी> यह तथ्य कि औसत उपयोगकर्ता तीसरे पक्ष के क्लाइंट (ब्राउज़र) के माध्यम से हमारे एप्लिकेशन तक पहुंचता है, एक स्पष्ट, सुरक्षित ब्राउज़िंग अनुभव के प्रति संकेत का एक और स्तर जोड़ता है:ब्राउज़र स्वयं एक सुरक्षा भेद्यता प्रस्तुत कर सकता है। <पी> विक्रेता आम तौर पर पुरस्कार (उर्फ बग बाउंटी) प्रदान करते हैं ) सुरक्षा शोधकर्ताओं के लिए जो ब्राउज़र पर ही भेद्यता ढूंढ सकते हैं। ये बग आपके कार्यान्वयन से जुड़े नहीं हैं, बल्कि ब्राउज़र अपने आप सुरक्षा कैसे संभालता है, उससे जुड़े हैं। <पी> उदाहरण के लिए, क्रोम पुरस्कार कार्यक्रम, सुरक्षा इंजीनियरों को क्रोम सुरक्षा टीम तक पहुंचने और उन्हें मिली कमजोरियों की रिपोर्ट करने की सुविधा देता है। यदि इन कमजोरियों की पुष्टि हो जाती है, तो एक पैच जारी किया जाता है, एक सुरक्षा सलाहकार नोटिस आम तौर पर जनता के लिए जारी किया जाता है, और शोधकर्ता को कार्यक्रम से एक (आमतौर पर वित्तीय) इनाम मिलता है। <पी> Google जैसी कंपनियां अपने बग बाउंटी कार्यक्रमों में अपेक्षाकृत अच्छी मात्रा में पूंजी निवेश करती हैं, क्योंकि इससे उन्हें एप्लिकेशन में कोई समस्या पाए जाने पर वित्तीय लाभ का वादा करके शोधकर्ताओं को आकर्षित करने की अनुमति मिलती है। <पी> बग बाउंटी कार्यक्रम में, हर कोई जीतता है:विक्रेता अपने सॉफ़्टवेयर की सुरक्षा में सुधार करने का प्रबंधन करता है, और शोधकर्ताओं को उनके निष्कर्षों के लिए भुगतान मिलता है। हम इन कार्यक्रमों पर बाद में चर्चा करेंगे, क्योंकि मेरा मानना है कि बग बाउंटी पहल सुरक्षा परिदृश्य में अपने स्वयं के अनुभाग के लायक हैं। <पी> जेक आर्चीबाल्ड Google में एक डेवलपर वकील हैं जिन्होंने हाल ही में एक से अधिक ब्राउज़र को प्रभावित करने वाली भेद्यता की खोज की है। उन्होंने अपने प्रयासों, विभिन्न विक्रेताओं से कैसे संपर्क किया और उनकी प्रतिक्रियाओं को एक दिलचस्प ब्लॉग पोस्ट में दर्ज किया, जिसे मैं आपको पढ़ने की सलाह दूंगा।डेवलपर्स के लिए एक ब्राउज़र
<पी> अब तक, हमें एक बहुत ही सरल लेकिन महत्वपूर्ण अवधारणा समझनी चाहिए थी:ब्राउज़र केवल HTTP क्लाइंट हैं जो औसत इंटरनेट सर्फर के लिए बनाए गए हैं . <पी> वे निश्चित रूप से एक प्लेटफ़ॉर्म के नंगे HTTP क्लाइंट से अधिक शक्तिशाली हैं (NodeJS केrequire('http') के बारे में सोचें) , उदाहरण के लिए), लेकिन दिन के अंत में, वे सरल HTTP क्लाइंट का "सिर्फ" एक प्राकृतिक विकास हैं। <पी> डेवलपर्स के रूप में, हमारी पसंद का HTTP क्लाइंट संभवतः डेनियल स्टेनबर्ग द्वारा लिखित कर्ल है, जो वेब डेवलपर्स द्वारा दैनिक आधार पर उपयोग किए जाने वाले सबसे लोकप्रिय सॉफ्टवेयर प्रोग्रामों में से एक है। यह हमें हमारी कमांड लाइन से एक HTTP अनुरोध भेजकर ऑन-द-फ्लाई HTTP एक्सचेंज करने की अनुमति देता है: $ curl -I localhost:8080
HTTP/1.1 200 OKserver: ecstatic-2.2.1Content-Type: text/htmletag: "23724049-4096-"2018-07-20T11:20:35.526Z""last-modified: Fri, 20 Jul 2018 11:20:35 GMTcache-control: max-age=3600Date: Fri, 20 Jul 2018 11:21:02 GMTConnection: keep-alive
localhost:8080/ पर दस्तावेज़ का अनुरोध किया है , और एक स्थानीय सर्वर ने सफलतापूर्वक उत्तर दिया। <पी> प्रतिक्रिया के मुख्य भाग को कमांड लाइन पर डंप करने के बजाय, यहां हमने -I का उपयोग किया है ध्वज जो कर्ल को बताता है कि हम केवल प्रतिक्रिया शीर्षलेखों में रुचि रखते हैं। इसे एक कदम आगे बढ़ाते हुए, हम cURL को उसके द्वारा किए गए वास्तविक अनुरोध सहित थोड़ी और जानकारी डंप करने का निर्देश दे सकते हैं, ताकि हम इस संपूर्ण HTTP एक्सचेंज पर बेहतर नज़र डाल सकें। हमें जिस विकल्प का उपयोग करने की आवश्यकता है वह -v है (क्रिया): $ curl -I -v localhost:8080* Rebuilt URL to: localhost:8080/* Trying 127.0.0.1...* Connected to localhost (127.0.0.1) port 8080 (#0)> HEAD / HTTP/1.1> Host: localhost:8080> User-Agent: curl/7.47.0> Accept: */*>< HTTP/1.1 200 OKHTTP/1.1 200 OK< server: ecstatic-2.2.1server: ecstatic-2.2.1< Content-Type: text/htmlContent-Type: text/html< etag: "23724049-4096-"2018-07-20T11:20:35.526Z""etag: "23724049-4096-"2018-07-20T11:20:35.526Z""< last-modified: Fri, 20 Jul 2018 11:20:35 GMTlast-modified: Fri, 20 Jul 2018 11:20:35 GMT< cache-control: max-age=3600cache-control: max-age=3600< Date: Fri, 20 Jul 2018 11:25:55 GMTDate: Fri, 20 Jul 2018 11:25:55 GMT< Connection: keep-aliveConnection: keep-alive
<* Connection #0 to host localhost left intact
HTTP प्रोटोकॉल में
<पी> जैसा कि हमने बताया, HTTP एक्सचेंज औरप्रतिपादनकरना चरण वे हैं जिन्हें हम अधिकतर कवर करने जा रहे हैं, क्योंकि वे सबसे बड़ी संख्या में हमला वेक्टर प्रदान करते हैं दुर्भावनापूर्ण उपयोगकर्ताओं के लिए. <पी> अगले लेख में, हम HTTP प्रोटोकॉल पर गहराई से नज़र डालने जा रहे हैं और यह समझने की कोशिश करेंगे कि HTTP एक्सचेंजों को सुरक्षित करने के लिए हमें क्या उपाय करने चाहिए। <पी> मूल रूप से odino.org पर प्रकाशित (29 जुलाई 2018)।_आप मुझे ट्विटर पर फ़ॉलो कर सकते हैं - टिप्पणियों का स्वागत है!_ ? <पी> मुफ़्त में कोड करना सीखें. फ्रीकोडकैंप के ओपन सोर्स पाठ्यक्रम ने 40,000 से अधिक लोगों को डेवलपर्स के रूप में नौकरी पाने में मदद की है। आरंभ करें