ब्लॉग में बिग डेटा के बारे में हमने बिग डेटा की कार्यात्मक परतों के बारे में चर्चा की और अपने पिछले ब्लॉग में मैंने टॉप 11 क्लाउड डेटा स्टोरेज टूल्स को सूचीबद्ध किया था। संग्रहण के बाद अगला चरण डेटा शोधन प्रक्रिया है।
जब हम बड़े डेटा के बारे में बात करते हैं, तो यह स्वत:स्पष्ट हो जाता है कि डेटा खतरनाक दर से बढ़ रहा है, चाहे वह व्यावसायिक डेटा हो या व्यक्तिगत डेटा। अगर तथ्यों की माने तो दुनिया में हर दिन 2.5 क्विंटिलियन बाइट डेटा बनाया जाता है। इस डेटा में दोहराए जाने वाले और गलत रिकॉर्ड भी हैं जिन्हें हमें इसमें अंतर्दृष्टि के लिए खनन करने से पहले हटाने की आवश्यकता है। गलत डेटा गलत धारणाओं और विश्लेषण की ओर ले जाता है जो अंततः परियोजना की विफलता का कारण बनता है।
डेटा क्लींजिंग एक विशेष डेटाबेस से गलत रिकॉर्ड को सही करने और हटाने (यदि आवश्यक हो) की प्रक्रिया का नाम है। डेटा सफाई का उद्देश्य तथाकथित गंदे डेटा का पता लगाना है ताकि यह सुनिश्चित किया जा सके कि डेटा का दिया गया सेट सही है और सिस्टम में अन्य सेट के साथ संगत है।
डेटा क्लीनिंग टूल कई प्रकार के होते हैं। एक अच्छा डेटा सफाई उपकरण आपके डेटाबेस को डुप्लिकेट डेटा, खराब प्रविष्टियों और गलत जानकारी से साफ़ करने में मदद करता है। इन उपकरणों को उपयोग किए जाने वाले वातावरण के आधार पर निम्न श्रेणियों में विभाजित किया जा सकता है:
- ऑफ़लाइन डेटा क्लीनिंग टूल
- क्लाउड आधारित डेटा क्लीनिंग टूल
- Salesforce डेटा के लिए डेटा क्लीनिंग टूल।
- पैटर्न, अनुपलब्ध मान, वर्ण सेट और अपने डेटा मानों की अन्य विशेषताओं का पता लगाएं।
- नाम और पता सत्यापन के साथ अपने संपर्क विवरण को साफ करें।
- फ़ज़ी लॉजिक और कॉन्फ़िगर करने योग्य वज़न और थ्रेसहोल्ड का उपयोग करके डुप्लिकेट का पता लगाएं। और अंत में इसका एक ही संस्करण बना रहे हैं।
- अपने स्वयं के सफाई नियम बनाएं और उन्हें कई उपयोग परिदृश्यों और लक्षित डेटाबेस में लिखें।
- सीमलेस इंटीग्रेशन
- डेटा डिस्कवरी और प्रोफाइलिंग
- डी-डुप्लीकेशन
- पता मानकीकरण
- डेटा परिवर्तन
- सफाई - दोषों के प्रकार को योग्य बनाता है, टिप्पणियों के साथ अशुद्ध डेटा के लॉग उत्पन्न करता है।
- डी-डुपिंग - ग्रुपिंग और क्लस्टरिंग, गलतबयानी की पहचान करना, जारी वृद्धिशील डी-डुपिंग।
- निगरानी - लेन-देन लॉग, मेल/एसएमएस द्वारा प्रक्रिया स्थिति चेतावनी, उपयोगकर्ता प्रमाणीकरण।
यह ब्लॉग आपको कुछ अच्छे ऑफ़लाइन डेटा क्लीनिंग टूल्स से परिचित कराएगा।
1. ड्रेक
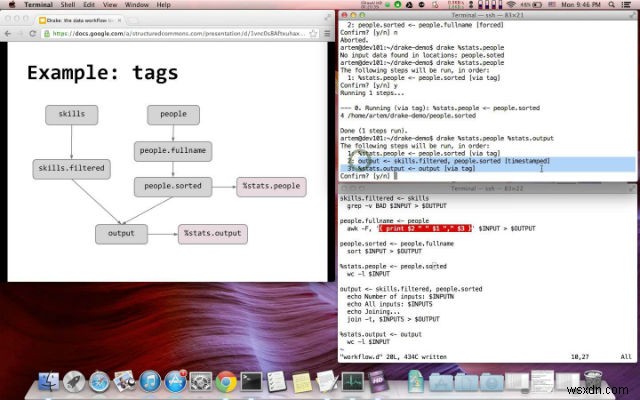
ड्रेक उपयोग में आसान, एक्स्टेंसिबल, टेक्स्ट-आधारित डेटा वर्कफ़्लो टूल है जो डेटा और इसकी निर्भरताओं के आसपास कमांड निष्पादन को व्यवस्थित करता है। डेटा प्रोसेसिंग चरणों को उनके इनपुट और आउटपुट के साथ परिभाषित किया गया है। यह स्वचालित रूप से निर्भरताओं को हल करता है और वर्कफ़्लो को नियंत्रित करने के लिए विकल्पों का समृद्ध सेट प्रदान करता है। यह कई इनपुट और आउटपुट को सपोर्ट करता है और इसमें HDFS सपोर्ट बिल्ट-इन है।
2. ओपनरिफाइन
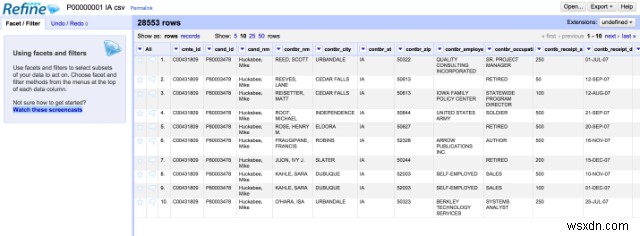
OpenRefine, जिसे पहले Google Refine कहा जाता था, गन्दा डेटा के साथ काम करने के लिए एक स्टैंडअलोन ओपन सोर्स शक्तिशाली डेस्कटॉप एप्लिकेशन है। यह डेटा रैंगलिंग फीचर यानी डेटा क्लीनअप और डेटा ट्रांसफॉर्मेशन को एक फॉर्मेट से दूसरे फॉर्मेट में पेश करता है। यह स्प्रेडशीट एप्लिकेशन के समान है, लेकिन डेटाबेस की तरह अधिक व्यवहार करता है।
यह रिलेशन डेटाबेस टेबल के समान डेटा पर काम करता है, यानी यह उन डेटा की पंक्तियों पर काम करता है जिनमें कॉलम के नीचे सेल होते हैं। एक OpenRefine प्रोजेक्ट एक टेबल है। उपयोगकर्ता विभिन्न फ़िल्टरिंग मानदंडों का उपयोग करके पंक्तियों का प्रदर्शन बदल सकते हैं। किसी डेटासेट पर किए गए सभी कार्य एक प्रोजेक्ट में संग्रहीत किए जाते हैं और दूसरे डेटासेट पर फिर से चलाए जा सकते हैं।
3. ट्राइफैक्टा रैंगलर
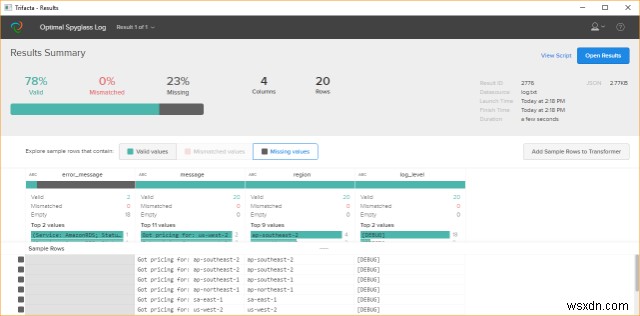
यह टूल डेटा रैंगलिंग प्रोसेस में हमारी मदद करता है। डेटा की तकरार को मोटे तौर पर डेटा को एक कच्चे रूप से दूसरे प्रारूप में मैन्युअल रूप से परिवर्तित करने या मैप करने की प्रक्रिया के रूप में परिभाषित किया जाता है जो अर्ध-स्वचालित उपकरणों की मदद से डेटा की अधिक सुविधाजनक खपत की अनुमति देता है।
रैंगलर नाटकीय रूप से सुधार करता है कि कैसे संगठन विविध डेटा से मूल्य प्राप्त करते हैं। ट्राइफेक्टा रैंगलर के साथ एक नया दृष्टिकोण लागू किया गया है कि कैसे विश्लेषक डेटा विज़ुअलाइज़ेशन, मशीन लर्निंग, मानव-कंप्यूटर इंटरैक्शन और डेटा प्रोसेसिंग में नवीनतम तकनीकों का लाभ उठाकर डेटा को उपयोगी बनाते हैं। उनका एक सरल उद्देश्य होता है कि वे डेटा को प्रारूपित करने में कम समय और डेटा का विश्लेषण करने में अधिक समय व्यतीत करें। यह विश्लेषण टूल के लिए डेटा तालिकाओं में अव्यवस्थित, वास्तविक-विश्व डेटा के इंटरैक्टिव परिवर्तन की अनुमति देता है।
4. डेटा क्लीनर
डेटा क्लीनर एक डेटा गुणवत्ता विश्लेषण अनुप्रयोग और डेटा गुणवत्ता समाधान के लिए एक समाधान मंच है। इसका कोर एक मजबूत प्रोफाइलिंग इंजन है, जो एक्स्टेंसिबल है और इस तरह डेटा क्लींजिंग, ट्रांसफॉर्मेशन, एनरिचमेंट, डीई डुप्लीकेशन, मैचिंग और मर्जिंग जोड़ता है। इसकी कुछ विशेषताएं नीचे दी गई हैं:
5. विनप्योर क्लीन एंड मैच
डेटा गुणवत्ता नियंत्रण किसी परियोजना या अभियान की समग्र सफलता के पीछे सबसे महत्वपूर्ण कारक है। यह एक डेटा क्लींजिंग और मैचिंग सुइट है, जिसे विशेष रूप से व्यवसाय या उपभोक्ता डेटा की सटीकता बढ़ाने के लिए डिज़ाइन किया गया है। यह एक पुरस्कार विजेता सॉफ्टवेयर सूट है, जो मेलिंग सूचियों, डेटाबेस, स्प्रेडशीट और सीआरएम की सफाई, सुधार और डुप्लीकेटिंग के लिए आदर्श है। इसका उपयोग एक्सेस, डीबेस, एसक्यूएल सर्वर और एक्सेल टेबल और टीएक्सटी फाइलों जैसे डेटाबेस के लिए किया जा सकता है।
6. TIBCO स्पष्टता
TIBCO Clarity एक डेटा तैयारी टूल है जो आपको सॉफ़्टवेयर-ए-ए-सर्विस के रूप में वेब से ऑन-डिमांड सॉफ़्टवेयर सेवाएँ प्रदान करता है। इसका उपयोग अलग-अलग स्रोतों से एकत्रित कच्चे डेटा को खोजने, प्रोफाइल करने, शुद्ध करने और मानकीकृत करने के लिए किया जा सकता है और सटीक विश्लेषण और बुद्धिमान निर्णय लेने के लिए अच्छी गुणवत्ता वाला डेटा प्रदान करता है। रॉ डेटा को मैनेज करने के लिए TIBCO क्लैरिटी की विशेषताएं:
7. डेटा सीढ़ी
डेटा लैडर कंपनी एक डेटा गुणवत्ता वाली सॉफ्टवेयर कंपनी है, जिसका उद्देश्य व्यावसायिक उपयोगकर्ताओं को डेटा मिलान, प्रोफाइलिंग, डी-डुप्लीकेशन और संवर्धन उपकरणों के माध्यम से अपने डेटा का अधिकतम लाभ उठाने में मदद करना है। . डेटा मैच एंटरप्राइज सूट एक अत्यधिक दृश्य डेस्कटॉप डेटा सफाई अनुप्रयोग है जिसे विशेष रूप से ग्राहक को हल करने और डेटा गुणवत्ता के मुद्दों से संपर्क करने के लिए डिज़ाइन किया गया है। डेटा मैच एंटरप्राइज़ में ध्वन्यात्मक, फ़ज़ी, मिस्कीड और संक्षिप्त विविधताओं का पता लगाने के लिए कई मालिकाना और मानक एल्गोरिदम शामिल हैं
डेटा डुप्लीकेशन सॉफ़्टवेयर डेटा गुणवत्ता, सफाई, मिलान और डी-डुप्लीकेशन सॉफ़्टवेयर के लिए एक उपयोग में आसान सॉफ़्टवेयर सुइट में संपूर्ण समाधान प्रदान करता है।
8. स्टार डीक्यू प्रो
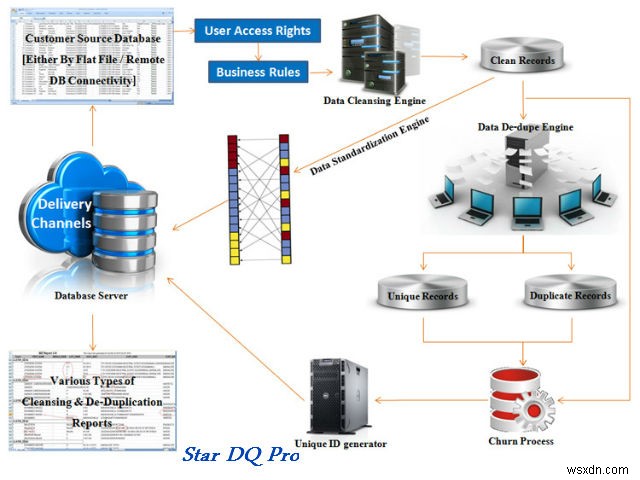
सुनिश्चित करें कि आपका डेटा सटीक, वास्तविक और अप-टू-डेट है। यह सटीकता, पूर्णता, निरंतरता, समय-सीमा, विशिष्टता और वैधता जैसी डेटा गुणवत्ता की प्रमुख आवश्यकताओं को संबोधित करता है। इसके द्वारा दी जाने वाली विशेषताएं हैं
डेटा की सफाई विशेष रूप से बहुत महत्वपूर्ण है जब बड़ी मात्रा में डेटा संग्रहीत किया जाता है। गंदे डेटा पर सुधारात्मक कार्रवाई का लक्ष्य किसी भी त्रुटि को यथासंभव महत्वहीन बनाना है। जब तक डेटा की सफाई नियमित रूप से नहीं की जाती है, तब तक गलतियाँ जमा हो सकती हैं और कार्य की दक्षता कम हो सकती है। बिग डेटा पर अगले ब्लॉग में, मैं सेल्सफोर्स डेटाबेस के लिए क्लाउड आधारित डेटा क्लींजिंग टूल और टूल्स की सूची बनाऊंगा।