आपने इसके बारे में सुना होगा। Google लोगों के वेबसाइटों के साथ इंटरैक्ट करने के तरीके को बदलने पर विचार कर रहा है। अधिक विशेष रूप से, लोग URL, मानव-पठनीय वेब पतों के साथ कैसे इंटरैक्ट करते हैं, जिसके द्वारा हम बड़े पैमाने पर उन वेबसाइटों को पहचानते और याद करते हैं जिन पर हम जाते हैं। कम से कम कहने के लिए इस प्रस्ताव के आस-पास लहर प्रभाव काफी दिलचस्प रहा है। और इसने मुझे सोचने पर मजबूर कर दिया।
एक, परिवर्तन के खिलाफ वास्तविक प्रतिक्रिया स्वयं परिवर्तन की तुलना में अधिक खुलासा करती है। दो, क्या वास्तव में URL को उनके वर्तमान स्वरूप से अधिक सार्थक और/या उपयोगी बनाने की कोशिश में कोई वास्तविक योग्यता है? उस अंत तक, आप इस लेख को पढ़ रहे हैं।
यूआरएल एक नज़र में
मनुष्य यादों को संख्याओं के बजाय शब्दों से जोड़ते हैं। संख्याओं की एक श्रृंखला की तुलना में पूरे वाक्यों या पैराग्राफों को याद रखना हमारे लिए बहुत आसान है। ऐसा इसलिए है क्योंकि हमारी भाषा ज्यादातर शब्दों से बनी है। हम संख्या के किसी भी क्रम के साथ संघर्ष करते हैं जो आठ या नौ अंकों से अधिक लंबा है। सरल कारण यह है कि अक्षरों के साथ, जानकारी की विशिष्टता अपेक्षाकृत कम है - 1001 और 1002 केवल एक अक्षर के अलावा हैं, इसलिए बोलने के लिए, लेकिन यह केवल अंतिम टुकड़ा है जो अंतर को अर्थ देता है। शब्दों के साथ, अपेक्षाकृत कम संयोजन हैं जो वर्णों और/या ध्वनियों के एक छोटे अनुक्रम से परे अस्पष्ट होंगे।
इसलिए, जैसे-जैसे वेब आया, मशीन व्याख्या के बजाय वेबसाइटों की पहचान करने के लिए शब्दों - स्ट्रिंग्स - का उपयोग करना अधिक तर्कसंगत हो गया। यह एक मज़ेदार चक्र है। हम शब्दों (कोड) को मशीनी भाषा में बदलते हैं, और फिर हम इसका उल्टा करते हैं ताकि लोग कंप्यूटर के साथ सार्थक तरीके से बातचीत कर सकें। संख्याओं का उपयोग करके वेब पर जाना मशीनी तरीका है। स्ट्रिंग्स मानव तरीका है।समस्या यह है - URL मानव और मशीनी भाषा के बीच का मिश्रित रूप है। एक तरफ, आपके पास मानवीय तत्व है, खुद का पता (जैसे dedoimedo.com), लेकिन बाकी सभी रिमोट सर्वर के लिए उपयोगकर्ता को वापस खोजने, खोजने और प्रस्तुत करने के लिए बहुत अधिक निर्देश हैं। यह एक समस्या पेश करता है कि लोग वेबसाइटों के साथ इस तरह से इंटरैक्ट करते हैं जो हमेशा सामान्य मानव मस्तिष्क के लिए समझ में नहीं आता है।
एक और समस्या है - URL में कोई एम्बेडेड जानकारी फ़िडेलिटी नहीं होती है। वास्तविक दुनिया में भौतिक पतों की तरह। यदि आप 17 ऑर्चर्ड ड्राइव पर जाते हैं, तो यह आपको यह नहीं बताता कि वह पता क्या है। यह एक कार्यालय हो सकता है, यह एक निजी आवास हो सकता है, यह एक डांस हॉल हो सकता है। सामग्री के बारे में भी कोई जानकारी नहीं है, जैसा कि आप वहां क्या पाएंगे - लोग, मलबे, एक बलि की वेदी, आदि।
उसी तरह, URL किसी भी तरह से गंतव्य (जिस साइट से आप जुड़ रहे हैं) को नहीं दर्शाते हैं। कभी-कभी, कुछ सहसंबंध हो सकता है, लेकिन कुल मिलाकर, यह तब तक अर्थपूर्ण नहीं है जब तक आप यह नहीं जानते कि साइट क्या है, और इसका क्या मतलब है। यह छोटी साइटों के साथ-साथ बड़ी कंपनियों के लिए भी सही है।
उदाहरण के लिए, Google वास्तव में आपको यह नहीं बताता कि यह एक खोज इंजन है। याहू आपको यह नहीं बताता कि यह एक सर्च इंजन है। बिंग का क्या अर्थ है? क्या अमेज़न एक नदी है, एक जंगल है या एक विशाल ऑनलाइन बाज़ार है? आप उपयोग और सामान्य प्रतिष्ठा के माध्यम से इन साइटों पर भरोसा करने लगे हैं, इसलिए नहीं कि URL जानकारी में कोई प्रोटो-वैल्यू है। लेकिन यह बेहतर, या बल्कि बदतर हो जाता है:
- साइट स्ट्रिंग और साइट उद्देश्य के बीच कोई संबंध नहीं है।
- साइट स्ट्रिंग और साइट के नाम (या इसके पीछे के व्यवसाय) के बीच कोई संबंध नहीं है।
- वेबसाइट पृष्ठ शीर्षक और साइट के नाम के बीच कोई संबंध नहीं है।
- साइट के उद्देश्य के बारे में कोई जानकारी नहीं।
इसके अलावा, जब आप किसी विशिष्ट पृष्ठ पर पहुँचते हैं, तो पृष्ठ शीर्षक, URL और सामग्री के बीच कोई संबंध नहीं हो सकता है। आप किसी साइट पर, एक पेज पर जा सकते हैं, जिसे किटन्स.एचटीएमएल कहा जाता है, लेकिन यह कारों के लिए बिल्ली के आकार के डिकल्स के बारे में हो सकता है, या वास्तव में छोटी फरी चीजों के बारे में हो सकता है। या पूरी तरह से कुछ और। और साइट को वास्तव में डैनी की दुकान कहा जा सकता है, और URL mysitenstuff.org जैसा कुछ हो सकता है।
और यह और भी खराब हो जाता है। अभी के लिए, हमने केवल समीकरण के मानवीय तत्व पर चर्चा की है। फिर, मशीन का हिस्सा है। उपडोमेन। एम, www, www3 जैसे सामान। http, https, ftp जैसे प्रोटोकॉल। सीमांकक, उप-निर्देशिकाएँ। गैर-समान तरीका जिसके द्वारा साइटें अपने पृष्ठ प्रस्तुत करती हैं - दिनांक, यादृच्छिक संख्या, तार, आदि। फिर, आपके पास निर्देश भी होते हैं। एक पृष्ठ में URL स्ट्रिंग के अंत में &uid=1234567&ref=true जैसा कुछ जोड़ा हो सकता है, जिसका अर्थ उपयोगकर्ता के रूप में आपके लिए कुछ भी नहीं है, लेकिन यह वेब सर्वर और/या सामग्री को प्रस्तुत या पार्स करने वाले एप्लिकेशन को कुछ चीजें बताता है ।
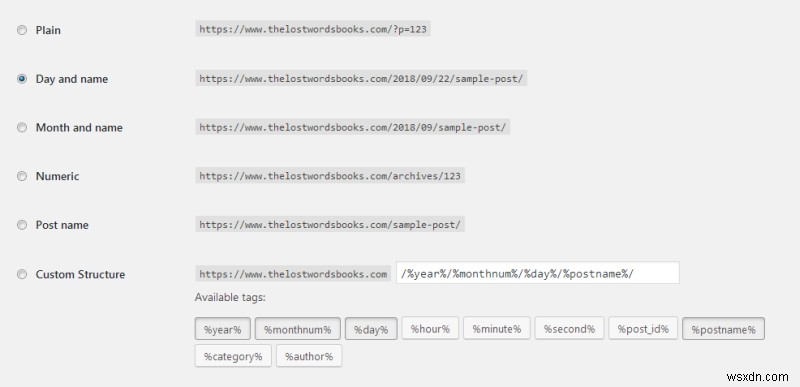
ये सभी URL विकल्प एक ही सामग्री के लिए हल होंगे, लेकिन वे सभी अलग-अलग दिखते और प्रस्तुत करते हैं।
अंत में, भरोसे का कोई उपाय नहीं है। जब तक वे किसी तरह से मान्य नहीं हो जाते, तब तक वेबसाइटें अपने मूल्य के बराबर होती हैं। प्रारंभ में, जैसे-जैसे ऑनलाइन शॉपिंग अधिक लोकप्रिय हुई, डिजिटल प्रमाणपत्रों की अवधारणा के बारे में आया, विश्वसनीय अधिकारियों ने एन्क्रिप्टेड और छेड़छाड़-सबूत बैज के पीछे विश्वसनीयता और सुरक्षा दोनों की पुष्टि की। सामुदायिक प्रयास और पेज रैंकिंग (कभी-कभी मालिकाना) डोमेन (साइटों) और उनकी सामग्री से जुड़े मूल्य के द्वितीयक उपाय बन गए, लेकिन अनिवार्य रूप से, यह किसी भी तरह से स्वयं URL में परिलक्षित नहीं होता है।
ऐसे में सवाल यह है कि क्या हमें बदलाव की जरूरत है? शायद। शायद नहीं। इंटरनेट काम करता है और ठीक है।
समाधान में ही उत्तर निहित है। लेकिन पहले, थोड़ा और दर्शनशास्त्र।जब आपने प्रस्ताव के बारे में सुना तो आपने क्या प्रतिक्रिया दी?
मैंने जो देखा है, यहां दो प्रमुख शिविर हैं। जो परिवर्तन का स्वागत करते हैं, यह महसूस करते हुए कि यह वेब को बेहतर बना देगा (बेहतर की मात्रा को परिभाषित करने की आवश्यकता है, अन्यथा यह सिर्फ खाली बात है)। और जो बदलाव का विरोध करते हैं। दूसरे समूहों को तीन में विभाजित किया जा सकता है:वे लोग जो परिवर्तन के लिए प्रतिरोधी हैं, वे जो तकनीकी योग्यता और कथित लाभों का विरोध करते हैं, और तीसरा समूह जो इस परिवर्तन का प्रस्ताव या नेतृत्व करने वाली लाभकारी कंपनी पर भरोसा नहीं करते हैं।
वास्तव में, यह एक बहुत बड़ा दार्शनिक प्रश्न है। क्या Google को इसका नेतृत्व करने की अनुमति दी जानी चाहिए?
आखिरकार, पिछले कुछ वर्षों में, कई लाभकारी कंपनियों ने अच्छे उत्पाद बनाए हैं जिनका हम आज बिना सोचे-समझे उपयोग करते हैं। शुरुआती हंगामे और बहस को लंबे समय तक भुला दिया जाता है। लेकिन इसमें पैसा शामिल था, यह एक मजबूत प्रेरक कारक था, और कंपनी की निचली रेखा को मजबूत करने के लिए चीजें की गईं। ऐसा किसी भी कंपनी के साथ अनिवार्य रूप से होगा जिसके पास अपने शेयरधारकों के प्रति जिम्मेदारी है, चाहे उसका नाम कुछ भी हो। मोबाइल की दुनिया और खोज क्षेत्र में अपने व्यापक प्रभाव के कारण Google के पास नेतृत्व की स्थिति है। लेकिन यह कोई भी कंपनी हो सकती है, और अंततः, अंतर्निहित कारक समान हैं। कुछ लोगों के लिए, यह सब मायने रखता है। यदि यह लाभ के लिए है, तो यह एक निष्पक्ष समाधान नहीं हो सकता है जो मानवता को लाभान्वित करे। हो सकता है, साइड इफेक्ट के रूप में, लेकिन प्राथमिक लक्ष्य के रूप में नहीं।
और यह वास्तव में पेचीदा है। प्रौद्योगिकी के साथ कुछ भी करने के बजाय प्रतिरोध वर्षों से Google का प्रतिबिंब है। लगता है, डू-नो-ईविल (कंपनी के मेनिफेस्ट से हटा दिया गया) से लेकर एक और रन-ऑफ-द-मिल बिग-बॉय-सूट कंपनी तक।
एक और उदाहरण जो मामले को मजबूत करता है, वह है एएमपी पर Google का आग्रह, इसकी अपनी मोबाइल-अनुकूलित परियोजना जो साधारण HTML को विशेष एएमपी निर्देशों में लपेटती है। जबकि पृष्ठ लोड करने की बात आती है तो इसकी कुछ योग्यता है और कुल मिलाकर, यह वास्तव में खराब है। यह उस समस्या की पुनरावृत्ति है जिसे हमने Internet Explorer 6 के साथ देखा था, जहाँ Microsoft नए निर्देशों की एक पूरी श्रृंखला के साथ आया था जो वेब मानकों का पालन नहीं करते थे, एक ब्राउज़र-विशिष्ट HTML/CSS अराजकता का निर्माण करते थे जो हाल ही में - आंशिक रूप से सुलझाया गया है।
जब मैंने 2006 में डेडोइमेडो की शुरुआत की, तो यह एक बड़ा मुद्दा था। उस समय लगभग हर साइट में उनके HTML में IE6/7/8 ओवरराइड थे। मैंने उन्हें लागू नहीं करने का फैसला किया और आगंतुकों या क्या नहीं, में संभावित दंड की परवाह किए बिना W3C विनिर्देशों पर टिके रहने का फैसला किया, क्योंकि एक सामान्य और मानकीकृत फैशन में डिजाइन करने का एकमात्र तरीका यह है कि महान टिम बर्नर्स-ली ने इसकी कल्पना कैसे की। इतिहास ने मुझे सही साबित कर दिया। आज भी, मैं सुनिश्चित करता हूं कि मेरे सभी पेजों में मान्य HTML और CSS हों, जो कुछ ऐसा है जो आप आजकल बाजार में बहुत कम देखते हैं। और यदि आप इस या उस ब्राउज़र के लिए विशेष ओवरराइड्स का उपयोग करते हैं, तो आप इंटरनेट को कम अच्छा बनाने में मदद कर रहे हैं।
मान्य एचटीएमएल, एक लुप्तप्राय प्रजाति।
अब, Google AMP के साथ HTML/CSS अनुपालन विचलन समस्या को फिर से बना रहा है। वेब को निष्पक्ष और निष्पक्ष, अंतरराष्ट्रीय मानकों के अनुरूप होना चाहिए। इसे कभी भी किसी भी कंपनी के अनुसार आकार नहीं देना चाहिए।
इसलिए, URL केवल बड़े निगमों के प्रति बढ़ते अविश्वास का एक उत्प्रेरक है, विशेष रूप से वे जो निजी डेटा के व्यवसाय में हैं। यही वह समस्या है जिसे पहले संबोधित करने की आवश्यकता है ताकि हम भावनाओं को प्रौद्योगिकी से अलग कर सकें। अन्यथा, भविष्य के सभी प्रस्ताव त्रुटिपूर्ण होंगे, क्योंकि वे तकनीकी जरूरतों के बजाय भावनात्मक जरूरतों को पूरा करने की कोशिश करेंगे।
मेरे पास इसका कोई समाधान नहीं है - केवल Google ही Google को बदल सकता है। अगर वे चाहते हैं, बिल्कुल।
चीजें बदलती हैं
हमें यह नहीं भूलना चाहिए। परोपकारी विचार जीवन की गति में बह जाते हैं, उनकी प्रारंभिक अवधारणाओं के विकृत संस्करण बन जाते हैं। यह कभी-कभी जानबूझकर डिजाइन के माध्यम से होता है, और कभी-कभी दुर्घटना से, लाखों छोटे निर्णयों और बाधाओं के माध्यम से होता है जिन्हें पहले से देखा या नियोजित नहीं किया जा सकता था। आपके द्वारा उपयोग किए जा रहे किसी भी उत्पाद के बारे में सोचें। पांच या दस साल पहले की स्थिति को देखें, अगर वह इतनी दूर तक अस्तित्व में थी। क्या आप कोई बदलाव देखते हैं? क्या आपको यह पसंद है? और फिर याद रखें कि एक व्यक्ति के रूप में आप भी बदल गए हैं, और आज आप दुनिया को जिस तरह से देखते हैं, वह बिल्कुल वैसा नहीं है जैसा आप कुछ साल पहले महसूस करते थे।
Google का समाधान - या किसी का भी - दुनिया में सबसे अच्छी बात हो सकती है। अब से सत्रह या बीस साल बाद, यह एक तरह से बदल सकता है जिसकी भविष्यवाणी करना असंभव है, भले ही दुनिया में सबसे अच्छे इरादे और सभी गहन शिक्षाएं हों। इसमें कोई दुर्भावना नहीं होनी चाहिए। चीजों को कैसे किया जाता है, बस धीरे-धीरे रेंगना, लोगों को आदत हो रही है और वे नए मानदंडों को पुरानी परंपराओं के रूप में स्वीकार कर रहे हैं, और आगे बढ़ रहे हैं, जब तक कि मूल चीज़ को लंबे समय तक भुला नहीं दिया जाता।
वहीं बड़ी समस्या है। आज सहमत प्रस्ताव जो भी हो, भले ही Google का समाधान सटीक हो, किसी भी कंपनी को निजी, मालिकाना कार्यान्वयन करने से रोकने के लिए कुछ भी नहीं है, जिसमें स्वयं Google भी शामिल है। या कोई प्रतियोगी।
इंटरनेट का निजीकरण वास्तव में पहले से ही हो रहा है। इंटरनेट छोटा हो रहा है। सबसे पहले, आप अपनी अधिकांश जानकारी दलालों - खोज इंजन, समाचार पोर्टलों के माध्यम से ले रहे हैं। जब तक यह लोकप्रिय खोज साइटों पर सूचीबद्ध न हो, और तब भी, सूची में उच्च स्तर पर हो, तब तक आपको शायद ही कभी नई सामग्री मिलेगी। मोबाइल पर यह और भी बुरा है। लोग शायद ही अब और ब्राउज़ करते हैं। वे ऐप का उपयोग करते हैं, जो एकल, केंद्रीकृत स्टोर द्वारा प्रदान किया जाता है।
जरा देखिए कि एक विशिष्ट स्मार्टफोन या स्मार्ट टीवी क्या है - क्यूरेटेड और फ़िल्टर की गई सामग्री के साथ एक कसकर नियंत्रित मंच। जब आप एक फ़ोन ऐप लॉन्च करते हैं, तो आपको पता नहीं होता है कि यह बैकग्राउंड में क्या कर रहा है या यह किन URL से कनेक्ट हो रहा है। या तो आप प्लेटफ़ॉर्म पर भरोसा करते हैं कि वह जो कहता है वह करेगा, या आप उसका उपयोग नहीं करते हैं, जो कठिन होता जा रहा है कि रोजमर्रा की जिंदगी में कितनी दखल देने वाली और आवश्यक तकनीक बन गई है। और यह केवल दस या पन्द्रह वर्षों में हुआ, जब इंटरनेट वास्तव में फलफूल रहा था? कल्पना कीजिए कि बीस या पचास वर्षों में क्या होगा।
मानव अधिकार के रूप में इंटरनेट
इंटरनेट, बोलने के लिए, पहले से ही मानव अधिकारों की सार्वभौम घोषणा में जोड़ा गया है। लेकिन वह कहीं भी पर्याप्त नहीं है।
हमारे पास पहले से ही इंटरनेट टास्क फोर्स है। हमारे पास मानक हैं। हमारे पास गोपनीयता कानून भी हैं, अधिकतर राष्ट्रीय। लेकिन कोई सुपर-सरकारी निकाय नहीं है जो व्यक्तिगत स्तर तक वेब की तटस्थता में डिजिटल स्वतंत्रता और निजी पार्टियों द्वारा गैर-हस्तक्षेप की गारंटी देता है। यह बहुत संभव है कि ऐसा कभी न हो, क्योंकि पाई जाने के लिए बहुत बड़ा और रसीला है।
यदि आप मुझसे पूछें, तो वास्तव में यह सुनिश्चित करने का एकमात्र तरीका है कि वेब के कुछ हिस्से वास्तव में अछूत हैं, उन्हें डिजिटल जिनेवा-जैसे सम्मेलन में स्थापित करना है। यह भोला और आदर्शवादी लगता है, लेकिन फिर, आज, आप पर दया है जो कोई भी आपके इंटरनेट को नियंत्रित करता है और वे इसे आपको कैसे देने का निर्णय लेते हैं।
मेरा प्रस्ताव
ठीक है, अंत में, तकनीकी अंश।
वैसे भी, यूआरएल संरचना काफी हद तक है:मशीन | मानव | मशीन।
ड्राइविंग कारक हैं:तटस्थता, सुरक्षा, अखंडता, उपयोग में आसानी। डिजिटल प्रमाणपत्रों द्वारा सुरक्षा और अखंडता को पहले ही अपेक्षाकृत अच्छी तरह से हल कर लिया गया है - लेकिन उनमें सुधार किया जा सकता है। तटस्थता URL स्ट्रिंग के मानवीय भाग में सन्निहित है, और उपयोग में आसानी पहले और अंतिम भाग में निहित है।
मशीन पार्ट 1
जैसा कि आप जानते हैं, आधुनिक ब्राउज़र पहले से ही https:// और/या www पते के हिस्सों को न दिखाते हुए मशीन के हिस्से को वेब एड्रेस स्ट्रिंग के मानव भाग से अलग करने की कोशिश कर रहे हैं, क्योंकि ये ब्राउज़र शायद ही कभी प्रोटोकॉल के अलावा सेवा करते हैं एचटीटीपी या एचटीटीपी. यह बहुत बुरा नहीं है। हालाँकि, सिक्योर-नॉट सिक्योर कॉन्सेप्ट पर्याप्त स्पष्ट नहीं है। यह चिंताजनक और सुकून देने वाला है लेकिन सही कारणों से नहीं - हम इसके बारे में मानव भाग अनुभाग में बात करेंगे।
HTTP:// या HTTPS:// का मतलब 99% लोगों के लिए कुछ भी नहीं है। यदि आप URL स्ट्रिंग को अन्य एप्लिकेशन को सौंपते हैं तो वे उपयोगी होते हैं, ताकि वे कनेक्ट करने के लिए सही प्रोटोकॉल का उपयोग कर सकें। इसके अलावा, हमारे यहां वास्तव में अतिरेक है। प्रमाणपत्र पहले से ही कनेक्शन सुरक्षा सुनिश्चित करने का काम कर रहे हैं।
इसका उत्तर यह है कि या तो उपसर्ग (मशीन भाग 1) को पूरी तरह से हटा दिया जाए और केवल प्रमाणपत्रों का उपयोग किया जाए, या प्रतीकात्मक कारणों से, उपसर्ग को वेब जैसी किसी चीज़ से बदल दिया जाए - वास्तविक सीमांकक और जो अलग से जांच नहीं करता है। यह संभावित रूप से अन्य गैर-वेब प्रोटोकॉल के भविष्य के कार्यान्वयन के लिए एक स्थान खोल सकता है, जैसे आभासी वास्तविकता, शुद्ध-मीडिया स्ट्रीमिंग, चैट, और आगे। और साथ ही कॉन्फ़िग, क्रोम आदि जैसे ब्राउज़र-विशिष्ट आंतरिक पेजों के अनुरूप रहें।
इंसान का हिस्सा
मानवीय भाग को अनिवार्य रूप से उल्लंघन किया जाना चाहिए - साइट पृष्ठ का पता जो भी हो, उसे रहना चाहिए और इसे हमेशा उपयोगकर्ता को बिना किसी आपत्ति के दिखाया जाना चाहिए। डोमेन नाम, उद्देश्य, तर्क, दिनांक और शीर्षक से मेल खाने वाले अच्छे URL प्रथाओं के लिए दिशानिर्देश होने चाहिए, जो कुछ सर्वर करते हैं। लेकिन यह भौतिक पतों की तरह ही है। We don't get to choose how streets are named, or how the home address is formed, and there are so many options worldwide. Same here.
This is part of what we are - and changing this language also breaks communication. There is no universal piece of objective information in a domain name, page title or similar. It's all down to what we want to write, and so, trying to tame this into submission is the wrong way forward.
But what about trust, integrity, spoofing?
If you mistype a site name, you could land on a wrong page. Or people ignore security warnings and give their credentials out on fake domains. Are there ways to work around these without breaking the human communication?
Well, certificates help - but they won't stop you going to a digitally signed site that is serving bogus content. Nor can they stop you from giving out your personal data. But on its own, technology CANNOT stop human stupidity or ignorance. It can be mitigated, but the unholy obsession with security degrades the user experience and breaks the Internet. So what to do?
I believe it is better to compromise on security than on user experience. The benefits outweigh the costs. There is crime out there, but largely, there's no breakdown of society and no anarchy. Because if we compromise on freedom for the sake of security, well, you know where this leads.
All that said, if the question is how to guarantee human users can differentiate between legitimate and fake sources supposedly serving identical content, beyond what we already have, then the answer lies in another question. If you give out two seemingly identical pages to a user, what is the one piece that separates them? The immediate answer is:URL. But if the user is not paying attention to the URL, what then?
The answer to that question could be a whitelist mechanism. In other words, if a user tries to input information on a page that is not recognized (in some way) as a known (read good) source, the browser could prompt the user with something like:You're currently on a page XYZ and about to fill in personal information, is this what you expect?
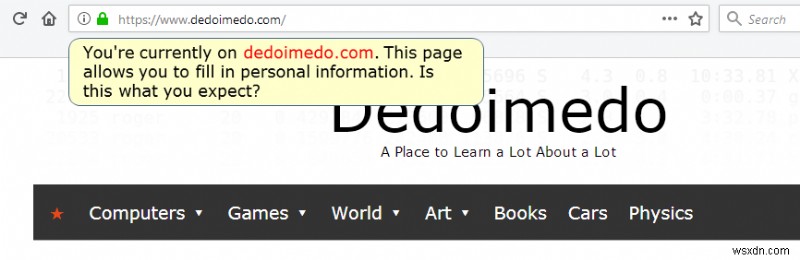
Crude illustration/mockup of what could be used to warn users when they are about to provide personal information on websites that are not "whitelisted" in some way.
People might still proceed and give away their data, but hey, nothing stops people from electrocuting themselves with toaster ovens in a bath tub, either. It is NOT about changing the URL - it's about helping people understand they are at the RIGHT address. In a way that does not break the user experience.
Now, let's talk about the machine string some more, shall we.
Machine part 2
The second part needs to be standardized. Today, servers and applications parse, mangle and structure URLs any which way they want. You can add all sorts of qualifies and key pair values, and end up with things like video autoplay, shopping cart contents, pre-filled forms, and more. In a way, this is lazy, convenient coding.
The standardization needs to be neutral - not dependent on how the browser or the site wants to present its information, because it's part of the problem today (including phishing and whatnot). I think that websites need to be forced to present a simple URL structure to the user that responds in a valid way.
The answer is:URL language. The same way browsers parse HTML and CSS, there could be a URL standard for the machine part. This could be a relatively small dictionary, and it would include somewhat STILL human-readable keys like (just a small subset of possible examples):
- unique-user-identifier - this would be a value that maps to an individual browser/user.
- javascript-status - if the client supports or runs Javascript.
- media-autoplay - whether media should play.
- media-timestamp - playback position for media.
- page - navigation element.
- Other similar keys.
And the rest would be ignored by the browser - provided all browsers adhere to the international standards and offer the same behavior and responses. Yes, the same way if you invent a new CSS class or HTML directive, and it does not exist and/or hasn't been properly declared, it gets ignored. The same way the remote application should ignore non-existent standard keys.
There must be special keys (flags), like dev=1 or debug=1 that would force the browser to interpret all provided machine parts and forward them to the server, which would also allow site devs/owners to troubleshoot their applications and offer full backward compatibility to everything we have on the market today. But then, the user could be prompted if such a combo is spotted in the URL address:
This site wants to run in dev mode. Do you want to allow it?
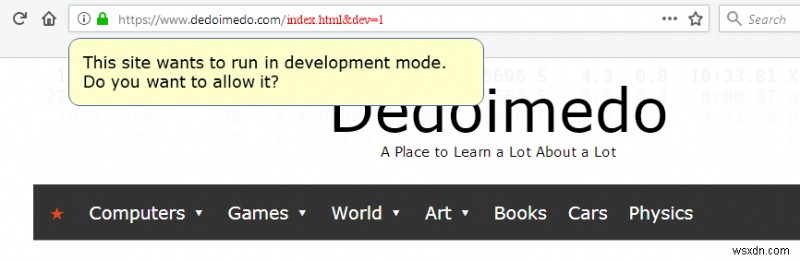
Crude illustration/mockup of what a standardized URL construct might be, with dev/debug flags.
This might enhance security too. Theoretically, the browsers could allow the user to block tracking via URL and not just on loaded pages. For instance, lots of email invitations and such come with a whole load of tracking, embedded in the URL. Privacy-conscious browsers could strip those away - or ask the user.
The URL is convenient for passing information to the application - but there's no real reason for this. When you click Buy on Amazon or PayPal, you don't see what happens. When you read Gmail, you don't see what happens. Buttons hide functionality, and it is not reflected in the URL.
To sum it up:the machine-part of the URL would contain a limited dictionary of standardized keys that would allow the information to be passed this way, but the rest would be ignored unless special flags like dev or debug are used, with the option to prompt the user. Enhanced security, enhanced privacy.
If ever defined, standardized and adopted, this will take time - an industry-wide effort. Now, is there a way to ignore forty years of legacy and existing implementations? The answer is, no bloody way. A change to the URL structure is something that will take decades. If you think IPv4 to IPv6 is complex, the URL journey will be even longer.
Finally, Quis custodiet ipsos custodes? Back to square one.
निष्कर्ष
The URL change is not important on its own - it is, but the technical part is relatively easy. The bigger issue is that, at the moment, people still have a fairly unrestricted access to the Web, largely due to the nerdy nature of the human-readable Web addresses. The URL is one of the old pieces of the Internet, and as such, it is mostly unfiltered and without abstractions. Once that goes away, we truly lose control of information. The world becomes a walled garden.
Google's general call to action makes sense, from the technical perspective, but the change could accidentally lead to something far bigger. Something sinister. Something sad. The death of the Internet as we know it. The ugly, cumbersome URL was invented in an age of innocence and exploration. As confusing as it is, it's the one piece that does not really belong to anyone. Any future change must preserve that neutrality.
If I were Google, I wouldn't worry about the URL. I would focus on why people don't want Google to be the arbiter of their Internet. Understand why people oppose you, regardless of the technical detail. Because, in the end, it's not about the URL. It's about freedom. Once that piece clicks into place, the technical solution will be trivial.
Food for thought.
चीयर्स।