हम इंटरनेट और इसके ज्ञान के धन को हल्के में लेते हैं। वस्तुतः सब कुछ एक बटन के क्लिक पर 24 घंटे, सप्ताह में 7 दिन आसानी से उपलब्ध है। वह है - जब तक यह नहीं है। वेबसाइटें एक पल की सूचना के बिना पेट ऊपर जा सकती हैं, उनकी सामग्री हमेशा के लिए चली जाती है।
विभिन्न कारणों से इंटरनेट पर दिखाई देने वाली सामग्री को संग्रहित करना महत्वपूर्ण है। वेबसाइटों को सहेजना मानव संस्कृति को संरक्षित करने का एक तरीका है, ठीक उसी तरह जैसे हम पुस्तकों या कला के कार्यों की रक्षा और क्यूरेट करते हैं। क्यूरियोसिटी एक बड़ा चालक है - आखिरकार, बच्चे आज अपने बेतहाशा सपनों में एक पुराने जियोसिटीज वेब पेज की कल्पना नहीं कर सकते। सामान्य जिज्ञासा के अलावा, वेबसाइटों को सहेजना हमें महत्वपूर्ण जानकारी पर वापस जाने की अनुमति दे सकता है।
वेब पर मिली जानकारी को संदर्भित करना बहुत सुविधाजनक है। लेकिन क्या होता है जब वह लिंक सिर्फ 404 त्रुटि संदेश की ओर इशारा करता है? 2013 में हार्वर्ड के एक अध्ययन में पाया गया कि अमेरिका में सुप्रीम कोर्ट के फैसलों में संदर्भित 49% वेबसाइटें अब समाप्त हो चुकी थीं। हम इस तरह की महत्वपूर्ण जानकारी को वर्चुअल ईथर में गायब होने से कैसे रोक सकते हैं?
सौभाग्य से, द इंटरनेट आर्काइव के लोगों ने एक ऐसा टूल विकसित किया है जो वेबसाइटों को इंडेक्स और आर्काइव कर सकता है। वे इसे वेबैक मशीन कहते हैं, और यह 2001 से वेबसाइटों को संग्रहित कर रही है। आज तक, वेबैक मशीन ने 304 बिलियन से अधिक वेब पेज सहेजे हैं।
वेबसाइट को आर्काइव करने के कई कारण हैं। सौभाग्य से, द वेबैक मशीन इसे बहुत आसान बनाती है। यहां वे तरीके दिए गए हैं जिनसे आप अपनी सभी वेबपृष्ठ संग्रहण आवश्यकताओं के लिए The Wayback Machine का उपयोग कर सकते हैं।
कौन सी साइटें सूचीबद्ध हैं?
कई लोकप्रिय वेबसाइट स्वचालित रूप से वेबैक मशीन द्वारा संग्रहीत की जाती हैं। हालाँकि, आप वस्तुतः किसी भी पृष्ठ को मैन्युअल रूप से संग्रहीत करने के लिए वेबैक मशीन का उपयोग कर सकते हैं। वेबसाइटों को अक्सर छोड़ दिया जाता है या पूरी तरह से बदल दिया जाता है, इसलिए वेबैक मशीन एक वेबसाइट की डिजिटल "हार्ड कॉपी" रखकर इंटरनेट की संस्कृति को संरक्षित करने के तरीके के रूप में कार्य करती है। ध्यान रखें कि टेक्स्ट और इमेज बरकरार हैं; हालांकि, कुछ आउटबाउंड लिंक और एम्बेडेड आइटम (जैसे वीडियो) नहीं हैं।
यह ध्यान रखना महत्वपूर्ण है कि द वेबैक मशीन केवल सार्वजनिक साइटों को स्कैन और संग्रहीत करती है। इसका मतलब है कि पासवर्ड से सुरक्षित साइटों या निजी सर्वर पर स्थित साइटों को संग्रहीत नहीं किया जा सकता है। इसके अतिरिक्त, यदि कोई वेबसाइट खोज इंजनों को खोज परिणामों में शामिल करने से प्रतिबंधित करती है, तो वेबैक मशीन उसे संग्रहित नहीं कर पाएगी।
वेबैक मशीन का उपयोग कैसे करें
वेबसाइटों का संग्रह शुरू करने के लिए आप दो विधियों का उपयोग कर सकते हैं। सौभाग्य से, दोनों सुपर-आसान हैं और किसी विशेष जानकारी की आवश्यकता नहीं है। अपने कर्सर को अपने ब्राउज़र के एड्रेस बार में URL के सामने रखकर प्रारंभ करें। टाइप करें web.archive.org/save/ और एंटर दबाएं। आपकी स्क्रीन पर एक डायलॉग बॉक्स दिखाई देगा जो आपको सूचित करेगा कि वेबैक मशीन पेज को सेव कर रही है।
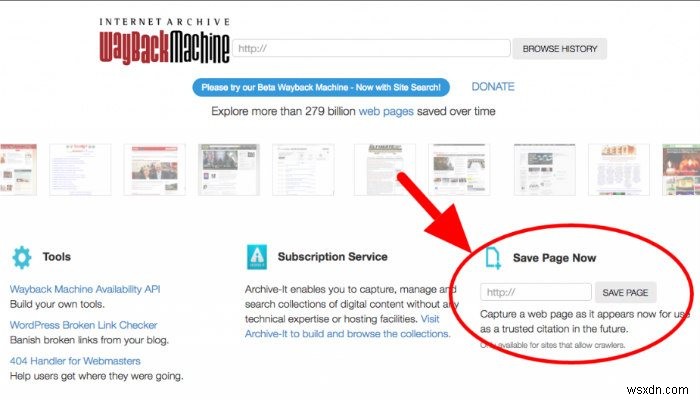
वेबपेज को आर्काइव करने का दूसरा तरीका वेबैक मशीन आर्काइव वेबसाइट का उपयोग करना है। सबसे पहले, उस वेबपेज पर नेविगेट करें जिसे आप सहेजना चाहते हैं और URL को कॉपी करें। इसके साथ, वेबैक मशीन संग्रह वेबसाइट पर जाएं। इस पेज के दाईं ओर आपको एक हेडर दिखाई देगा जिस पर लिखा होगा "अभी पेज सेव करें।" उस वेबपेज का URL पेस्ट करें जिसे आप टेक्स्ट बॉक्स में सहेजना चाहते हैं और "पेज सहेजें" बटन पर क्लिक करें।
आप चाहे कोई भी तरीका अपनाएं, नतीजा वही रहता है। ध्यान रखें कि पेज को सेव करने में कुछ समय लग सकता है, इसलिए धैर्य रखें और इसे अपना काम करने दें।
वेबैक मशीन ब्राउज़र एक्सटेंशन
वेबैक मशीन में Google क्रोम के लिए एक आधिकारिक ब्राउज़र एक्सटेंशन भी है। वेब पेजों को संग्रहित करने के लिए इसका उपयोग करना बहुत आसान है। बस उस पेज पर नेविगेट करें जिसे आप आर्काइव करना चाहते हैं, अपने टूलबार में वेबैक मशीन आइकन पर क्लिक करें और "अभी पेज सेव करें" पर क्लिक करें।
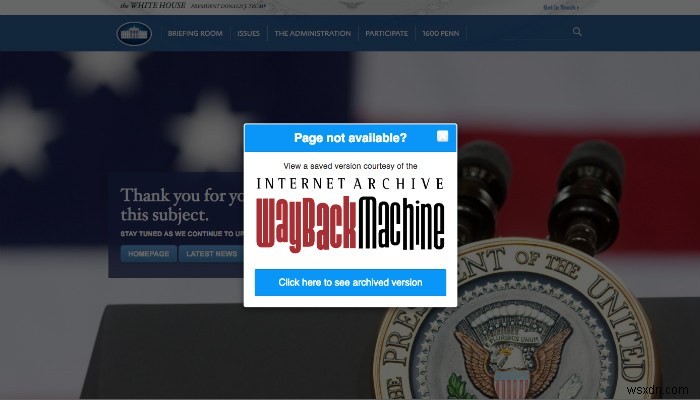
पृष्ठों को सहेजना और भी आसान बनाने के अलावा, ब्राउज़र एक्सटेंशन में एक और अच्छी चाल है टीएस आस्तीन। क्या आपने कभी केवल एक अस्पष्ट 404 त्रुटि संदेश का सामना करने के लिए किसी लिंक पर क्लिक किया है? चाहे वह आपके शोध पत्र के लिए एक मूल्यवान स्रोत हो या वास्तव में एक अच्छा नुस्खा हो, यह अविश्वसनीय रूप से निराशाजनक हो सकता है। वेबैक मशीन एक्सटेंशन स्थापित होने के साथ, वह निराशा राहत की सांस में बदल सकती है। जब आपका ब्राउज़र बंद हो जाता है, तो एक्सटेंशन यह देखने के लिए संग्रह को खोजेगा कि क्या वेबैक मशीन पर कोई सहेजी गई प्रति है। अगर वहाँ है, तो यह आपसे पूछेगा कि क्या आप उस पृष्ठ पर जाना चाहते हैं।
यदि आप क्रोम का उपयोग नहीं करते हैं, तो परेशान न हों। फ़ायरफ़ॉक्स के लिए एक वेबैक मशीन एक्सटेंशन उपलब्ध है; हालाँकि, यह अभी भी एक कार्य प्रगति पर है। इसके अतिरिक्त, सफारी उपयोगकर्ताओं के लिए भी एक एक्सटेंशन विकसित करने की योजना है।
संग्रह-यह
क्या आपके या आपके संगठन के पास ऐसी वेबसाइट है जिसे बार-बार अनुक्रमित और संग्रहीत करने की आवश्यकता है? यदि ऐसा है, तो उपरोक्त विधियों का उपयोग करके प्रत्येक व्यक्तिगत वेब पेज को मैन्युअल रूप से संग्रहीत करना अविश्वसनीय रूप से थकाऊ और महंगा हो सकता है। सौभाग्य से, इंटरनेट आर्काइव आर्काइव-इट नामक एक सेवा प्रदान करता है जो आपके लिए संग्रह प्रक्रिया को स्वचालित कर सकता है।
यह सेवा मुफ़्त नहीं है; हालांकि, यह उन लोगों के लिए आदर्श हो सकता है जो अपनी सामग्री को "इसे सेट करें और इसे भूल जाएं" मानसिकता के साथ बैक अप लेना चाहते हैं। बस यह निर्धारित करें कि आप किन पृष्ठों को सहेजना चाहेंगे और कितनी बार। यह सशुल्क सदस्यता उन लोगों के लिए एकदम सही है जो अपनी वेब सामग्री को नियमित रूप से सहेजना चाहते हैं।
क्या आप वेबैक मशीन का उपयोग करते हैं? यदि हां, तो क्या आप इसे विशुद्ध रूप से मनोरंजन के लिए देखते हैं या क्या आप इसे एक उपयोगी उपकरण पाते हैं? क्या वेब पर सामग्री का बैकअप लेने के अन्य तरीके हैं? हमें टिप्पणियों में बताएं!