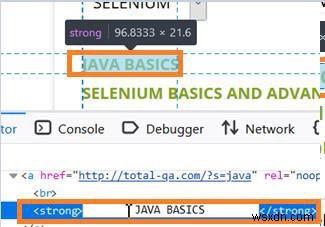
हम खोज टेक्स्टविथ या रिक्त स्थान वाले तत्वों की पहचान करने के लिए लोकेटर xpath का उपयोग कर सकते हैं। आइए सबसे पहले अनुगामी और अग्रणी रिक्त स्थान वाले वेब तत्व के html कोड की जाँच करें। नीचे दी गई छवि में, टैगनाम मजबूत के साथ जावा बेसिक्स टेक्स्ट में रिक्त स्थान हैं जैसा कि html कोड में दर्शाया गया है।
यदि किसी तत्व के टेक्स्ट में या किसी विशेषता के मूल्य में रिक्त स्थान हैं, तो ऐसे तत्व के लिए xpath बनाने के लिए हमें normalize-space फ़ंक्शन का उपयोग करना होगा। यह स्ट्रिंग से सभी अनुगामी और अग्रणी रिक्त स्थान को हटा देता है। यह स्ट्रिंग के भीतर मौजूद हर नए टैब या लाइनों को भी हटा देता है।
वाक्यविन्यास
//tagname[normalize-space(@attribute/ function) = 'value']
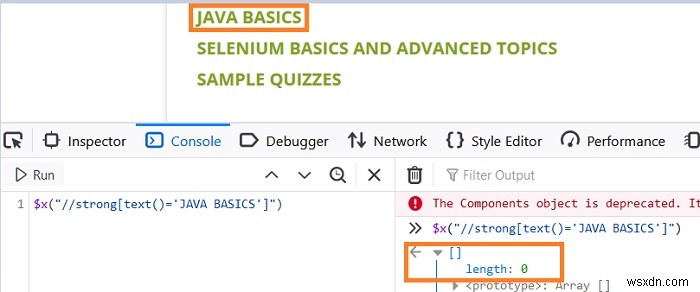
पृष्ठ पर प्रदर्शित होने वाले वेब तत्व जावा बेसिक्स के लिए, आइए एक xpath//strong[text()='JAVA BASICS'] (पाठ में रिक्त स्थान पर विचार किए बिना) बनाएं। यदि हम इसे कंसोल में एक्सप्रेशन - $x("//strong[text()='JAVABASICS']") के साथ सत्यापित करते हैं, तो हम पाएंगे कि कोई मेल खाने वाला तत्व नहीं है (लंबाई - 0 के साथ पहचाना गया)।
अब, हम normalize-space फ़ंक्शन का उपयोग करके xpath व्यंजक बनाते हैं। Thexpath एक्सप्रेशन होना चाहिए - //strong[normalize-space(text())='JAVA BASICS'].
आउटपुट
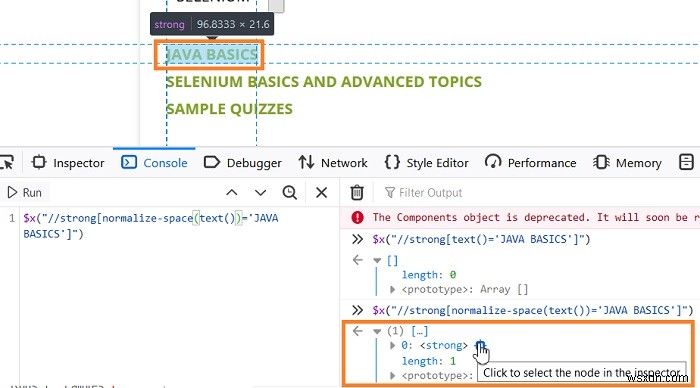
अगर हम इसे कंसोल में एक्सप्रेशन के साथ मान्य करते हैं - $x("//strong[normalizespace(text())='JAVA BASICS']"), तो हम पाएंगे कि एक मैचिंग एलिमेंट है (लंबाई -1 के साथ पहचाना गया)।
प्राप्त परिणाम पर मँडराने पर, हम पृष्ठ पर JAVA BASICS का पाठ हाइलाइट करते हुए पाएंगे।