हम क्या बना रहे हैं
<पी> इस लेख में, हम अत्यंत टिकाऊ एलएलएम स्ट्रीम का निर्माण कर रहे हैं जो आसानी से जीवित रहती हैं: - नेटवर्क आउटेज
- पेज रिफ्रेश
- वेबसाइट बंद करना
- लैपटॉप का ढक्कन बंद करना
<पी> बोनस:आप एक ही स्ट्रीम को एक ही समय में कई डिवाइस (जैसे फ़ोन और लैपटॉप) पर देख सकते हैं . <पी> इससे कोई फर्क नहीं पड़ता कि आप धारा को तोड़ने की कितनी कोशिश करते हैं, आपके डिस्कनेक्ट होने पर भी यह पृष्ठभूमि में जारी रहती है और जब आप वापस आते हैं तो यह सुचारू रूप से जारी रहती है। यह एक अविश्वसनीय है उपयोगकर्ता अनुभव. <पी> टिकाऊ एलएलएम स्ट्रीम डेमो 👇 प्रेरणा
<पी> AI के साथ निर्माण करते समय, वास्तविक समय में AI प्रतिक्रियाओं को स्ट्रीम करना सबसे अच्छा अभ्यास है। <पी> संपूर्ण प्रतिक्रिया की प्रतीक्षा करने के बजाय, आपका उपयोगकर्ता वास्तविक समय में सामग्री को उत्पन्न होते ही देखता है - जो यूएक्स के लिए आश्चर्यजनक है। वर्सेल द्वारा एआई एसडीके जैसे टूल ने इसे बेहद आसान बना दिया है: import { openai } from "@ai-sdk/openai";
import { streamText } from "ai";
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt: "Invent a new holiday and describe its traditions.",
});
<पी> वास्तविक समय एलएलएम स्ट्रीम को तकनीकी स्तर पर काम करने के लिए, आप एक क्लाइंट को एपीआई से कनेक्ट करते हैं और सर्वर सेंट इवेंट्स (एसएसई) जैसे प्रोटोकॉल का उपयोग करके डेटा स्ट्रीम करते हैं: <पी> 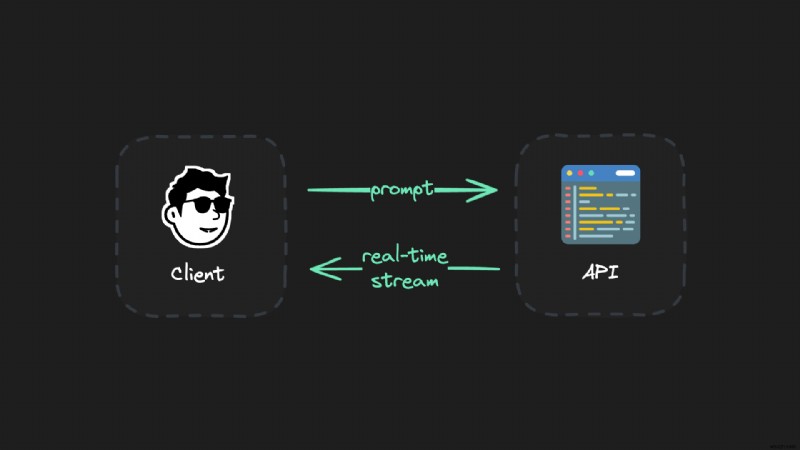 <पी> लेकिन:इस सेटअप में एक समस्या है। <पी> यदि स्ट्रीम के दौरान कुछ भी होता है, जैसे आपका इंटरनेट डिस्कनेक्ट होना, लैपटॉप का ढक्कन बंद होना, या नेटवर्क संबंधी दिक्कत, तो पूरी पीढ़ी नष्ट हो जाती है। आपको फिर से शुरुआत करने और पूरी पीढ़ी तक इंतजार करने की जरूरत है। यह विशेष रूप से लंबी पीढ़ियों के लिए कष्टप्रद है (उदाहरण के लिए O1 जैसे महंगे-से-चलने वाले मॉडल के साथ)। <पी>
<पी> लेकिन:इस सेटअप में एक समस्या है। <पी> यदि स्ट्रीम के दौरान कुछ भी होता है, जैसे आपका इंटरनेट डिस्कनेक्ट होना, लैपटॉप का ढक्कन बंद होना, या नेटवर्क संबंधी दिक्कत, तो पूरी पीढ़ी नष्ट हो जाती है। आपको फिर से शुरुआत करने और पूरी पीढ़ी तक इंतजार करने की जरूरत है। यह विशेष रूप से लंबी पीढ़ियों के लिए कष्टप्रद है (उदाहरण के लिए O1 जैसे महंगे-से-चलने वाले मॉडल के साथ)। <पी> 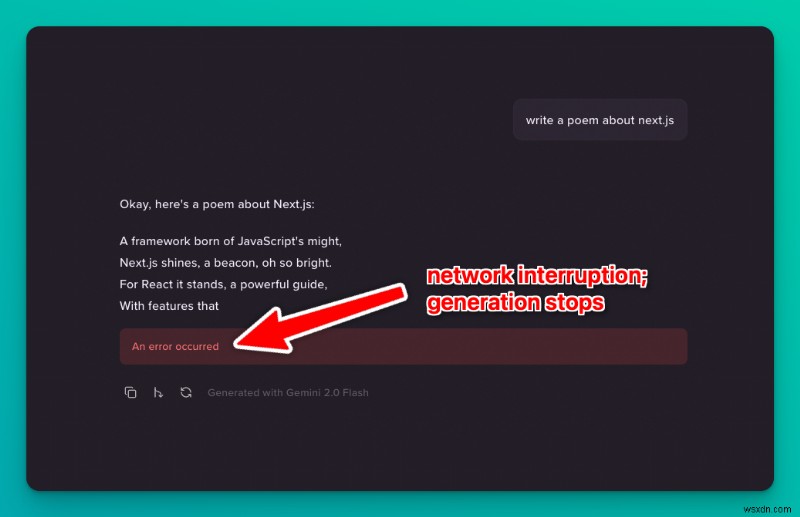 <पी> जाहिर है यह समस्या लोगों के रडार पर है। विश्वसनीय वास्तविक समय एलएलएम स्ट्रीमिंग की वास्तविक मांग है, और अधिक डेवलपर इसे काम करने के तरीकों के साथ प्रयोग कर रहे हैं: <पी>
<पी> जाहिर है यह समस्या लोगों के रडार पर है। विश्वसनीय वास्तविक समय एलएलएम स्ट्रीमिंग की वास्तविक मांग है, और अधिक डेवलपर इसे काम करने के तरीकों के साथ प्रयोग कर रहे हैं: <पी> 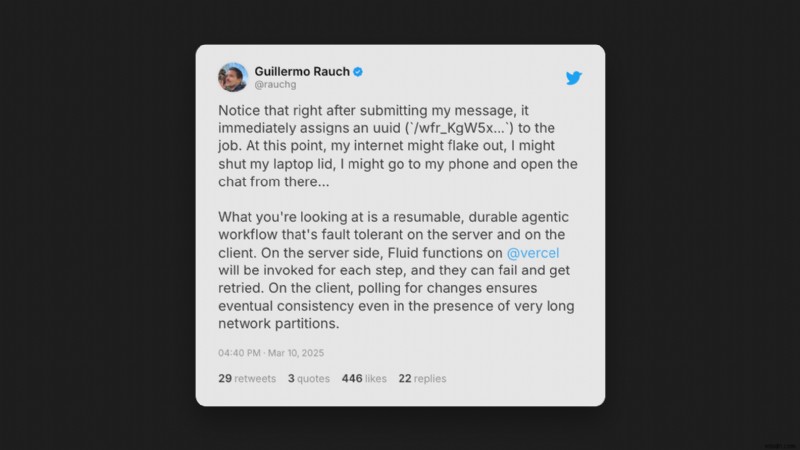
हाई-ड्यूरेबिलिटी एलएलएम स्ट्रीम का निर्माण
<पी> वास्तव में टिकाऊ, पुन:प्रारंभ करने योग्य एलएलएम स्ट्रीम बनाने का रहस्य ग्राहक को पीढ़ी के माहौल से अलग करना है। क्लाइंट कनेक्शन अस्थिर होते हैं और कई कारणों से डिस्कनेक्ट हो सकते हैं, जैसे लैपटॉप बंद करना, नेटवर्क समस्याएँ या पेज रीफ़्रेश करना। <पी> क्लाइंट और जेनरेशन प्रक्रियाओं को अलग-अलग रखने से जेनरेशन हमेशा निर्बाध रूप से जारी रहती है। ग्राहक किसी भी समय चालू पीढ़ी को बाधित किए बिना पुनः कनेक्ट कर सकते हैं। <पी> बुरा विचार:लगातार, सीधा संबंध: <पी> 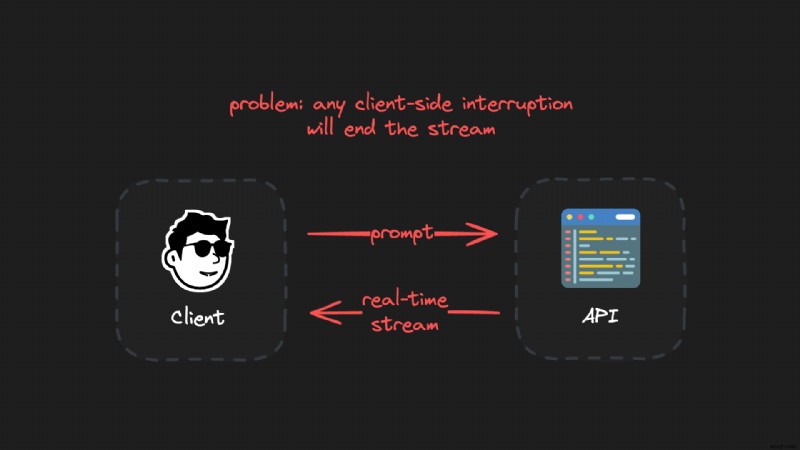 <पी> अच्छा विचार:बदली जाने योग्य, बाधित स्ट्रीम कनेक्शन: <पी>
<पी> अच्छा विचार:बदली जाने योग्य, बाधित स्ट्रीम कनेक्शन: <पी> 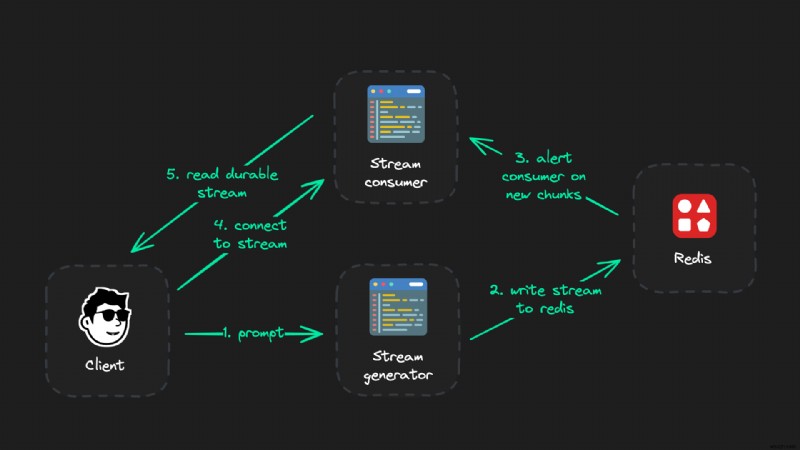 <पी> और हाँ - यह आर्किटेक्चर एक साधारण एआई स्ट्रीम के लिए काफी जटिल लग सकता है। हालाँकि, जैसा कि आप अभी कोड में देखेंगे, यह कोड की केवल कुछ पंक्तियाँ हैं और इसे लागू करने में कुछ मिनट लगते हैं।
<पी> और हाँ - यह आर्किटेक्चर एक साधारण एआई स्ट्रीम के लिए काफी जटिल लग सकता है। हालाँकि, जैसा कि आप अभी कोड में देखेंगे, यह कोड की केवल कुछ पंक्तियाँ हैं और इसे लागू करने में कुछ मिनट लगते हैं। टिकाऊ स्ट्रीम सेट करना
<पी> एक अत्यंत विश्वसनीय एलएलएम स्ट्रीम सेटअप के तीन भाग होते हैं: - ग्राहक (फ्रंटएंड)
- स्ट्रीम जनरेटर (एक एपीआई मार्ग)
- धारा उपभोक्ता (एक एपीआई रूट भी)
<पी> क्लाइंट से सीधे जुड़े सभी कनेक्शन किसी भी समय बाधित या रोके जा सकते हैं। एलएलएम आउटपुट स्ट्रीम (स्ट्रीम जनरेटर) उत्पन्न करने के लिए जिम्मेदार तर्क का टुकड़ा एक स्वतंत्र एपीआई होना चाहिए जिसका क्लाइंट से कभी भी सक्रिय कनेक्शन नहीं होता है। <पी> इसके बजाय, हम एक उपभोक्ता के माध्यम से क्लाइंट से जुड़ेंगे - जो सिर्फ रेडिस से डेटा पढ़ता है और अन्यथा बहुत "बेवकूफ" होता है। इसका एकमात्र उद्देश्य जनरेटर के आउटपुट को पढ़ना है और जब भी कोई ग्राहक इससे जुड़ता है तो वह सभी एलएलएम खंड प्रदान करना है जिन्हें ग्राहक ने अभी तक नहीं देखा है। बस इतना ही. <पी> त्वरित सारांश - प्रत्येक भाग क्या करता है: - ग्राहक: स्ट्रीम जनरेटर को ट्रिगर करता है (लेकिन कभी भी खुला कनेक्शन नहीं रखता है) और वास्तविक समय स्ट्रीम प्रस्तुत करता है
- स्ट्रीम जनरेटर: वास्तविक समय में एलएलएम आउटपुट उत्पन्न करता है और रेडिस
पर प्रकाशित करता है - स्ट्रीम उपभोक्ता: जनरेटर की स्ट्रीम को पढ़ता है और क्लाइंट को टुकड़ों को भेजता है
<पी> जनरेटर केवल एलएलएम स्ट्रीम को पढ़ने और उसे वास्तविक समय में रेडिस पर प्रकाशित करने के लिए जिम्मेदार है। हमें क्लाइंट से स्ट्रीम उपभोक्ता के लिए एक प्रतिस्थापन योग्य कनेक्शन मिलता है जिसे समाप्त किया जा सकता है, पुनः जोड़ा जा सकता है, आदि-स्ट्रीम जनरेटर को कुछ भी प्रभावित नहीं करता है। कोड उदाहरण
<पी> इस अनुभाग में, हम कोड पर एक नज़र डालेंगे। सिद्धांतों को बहुत स्पष्ट करने के लिए, हम अंत में वास्तविक, पूर्ण उत्पादन कोड कार्यान्वयन को देखेंगे। <पी> फिलहाल, यदि हम संपूर्ण कोड फ़ाइलों के बजाय मुख्य स्निपेट और उनके उद्देश्य पर नज़र डालें तो कोड को समझना बहुत आसान है। 1. ग्राहक
<पी> ग्राहक की केवल 3 जिम्मेदारियाँ हैं: - सत्र आईडी जनरेट करना
- जनरेटर चालू करना
- जेनरेशन स्ट्रीम प्रस्तुत करना
<पी> आइए प्रत्येक को देखें: क्लाइंट:सत्र आईडी जनरेट करना
<पी> जब कोई क्लाइंट किसी स्ट्रीम से जुड़ता है या दोबारा जुड़ता है, तो हम वे सभी संदेश भेजना चाहते हैं जो क्लाइंट ने अभी तक नहीं देखे हैं। इसका मतलब है कि एक सक्रिय स्ट्रीम के दौरान, प्रत्येक संदेश में केवल वही सटीक डेल्टा होता है जिसे क्लाइंट को देखना चाहिए, न कि संपूर्ण स्ट्रीम। <पी> पुन:कनेक्ट करते समय, वर्तमान पीढ़ी बिंदु तक की पूरी स्ट्रीम भेज दी जाती है और भविष्य की सभी घटनाओं की सदस्यता बिना किसी छूटे हिस्से के बिल्कुल निर्बाध होती है। <पी> कैसे? <पी> रेडिस स्ट्रीम, वास्तविक समय के डेटा को कुशलतापूर्वक संग्रहीत करने और पुनर्प्राप्त करने का एक तरीका है, इसमें उपभोक्ता समूहों के माध्यम से अभी तक नहीं देखी गई कार्यक्षमता अंतर्निहित है। केवल एक चीज जो हमें करने की ज़रूरत है:सुनिश्चित करें कि प्रत्येक ग्राहक के पास एक अद्वितीय सत्र हो - जिसका अर्थ है कि हम प्रत्येक पीढ़ी को एक अद्वितीय आईडी प्रदान करते हैं। <पी> स्ट्रीम उपभोक्ता को देखते समय हम उपभोक्ता समूहों के बारे में अधिक जानेंगे। वे इस तरह दिखते हैं: await redis.xgroup("redis-key", {
type: "CREATE",
group: "my-group-name",
id: "0",
});
<पी> किस क्लाइंट ने किस स्ट्रीम को किस बिंदु तक देखा है और कौन से टुकड़े गायब हैं, इसका पूरा तर्क पूरी तरह से रेडिस स्ट्रीम द्वारा नियंत्रित किया जाता है गारंटीशुदा परिशुद्धता के साथ। हमें कभी भी खोया हुआ एलएलएम खंड नहीं मिलता है और हम हमेशा वही डेटा भेजते हैं जिसकी ग्राहक को आवश्यकता होती है। <पी> ग्राहक को अभी केवल एक ही काम करना है:प्रत्येक पीढ़ी के लिए एक आईडी निर्दिष्ट करना। हम बस nanoid का उपयोग करते हैं : import { customAlphabet } from "nanoid"
const nanoid = customAlphabet("0123456789", 6);
क्लाइंट:जनरेशन स्ट्रीम को ट्रिगर करना
<पी> जनरेशन इंजन के साथ क्लाइंट का अब तक का एकमात्र इंटरेक्शन इसे ट्रिगर करना है। हालाँकि, तकनीकी रूप से, आप कहीं और से भी पीढ़ी को ट्रिगर कर सकते हैं (उदाहरण के लिए CRON नौकरियां, स्वचालित पाइपलाइन)। <पी> अपने सरलतम रूप में, यह जेनरेशन एपीआई रूट के लिए केवल एक फ़ेच कॉल है: // 👇 trigger stream generator
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId }),
});
क्लाइंट:जनरेशन स्ट्रीम पढ़ना
<पी> पीढ़ी को ट्रिगर करने के बाद, जनरेटर एलएलएम आउटपुट को एक केंद्रीकृत रेडिस स्टोर में स्ट्रीम करना शुरू कर देता है-क्लाइंट से पूरी तरह से अलग। आइए जनरेशन स्ट्रीम को पढ़ने के लिए स्ट्रीम उपभोक्ता से जुड़ें: // 👇 connect to stream consumer
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
});
<पी> बस इतना ही! <पी> वे ग्राहक की तीन जिम्मेदारियाँ हैं। बेशक, हम आईडी जनरेशन के लिए कस्टम हुक, अतिरिक्त विश्वसनीयता के लिए रिएक्ट-क्वेरी और बहुत कुछ के साथ बहुत अधिक प्रशंसक बन सकते हैं - हम इसे बाद में संपूर्ण कोड उदाहरणों में प्राप्त करेंगे। 2. स्ट्रीम जेनरेटर
<पी> स्ट्रीम जनरेटर एक एलएलएम स्ट्रीम खोलता है और प्रत्येक खंड को रेडिस स्ट्रीम में लिखता है। यह वास्तविक समय के अपडेट के लिए नए डेटा के बारे में स्ट्रीम उपभोक्ता को सचेत करने के लिए लिखे गए प्रत्येक खंड के लिए एक संदेश प्रकाशित करता है। <पी> नोट:फिर, यह जानबूझकर एक पूर्ण कोड उदाहरण नहीं है। हम अंत में पूर्ण कोड प्राप्त करेंगे-यह अवधारणा को समझने के लिए है। import { streamText } from "ai"
import { redis } from "@/utils"
const result = await new Promise(
async (resolve, reject) => {
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
// ...
}),
})
for await (const chunk of textStream) {
if (chunk) {
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
}
// 👇 write chunk to redis stream
await redis.xadd(streamKey, "*", chunkMessage)
// 👇 alert consumer that there's a new chunk
await redis.publish(streamKey, { type: MessageType.CHUNK })
}
}
}
)
3. स्ट्रीम उपभोक्ता
<पी> स्ट्रीम उपभोक्ता रेडिस से जुड़ता है और रेडिस पब/सब के माध्यम से नए चंक अलर्ट सुनता है। प्रत्येक ग्राहक को अपने देखे और अनदेखे संदेशों को ट्रैक करने के लिए अपना स्वयं का उपभोक्ता समूह मिलता है। <पी> ध्यान दें:प्रकाशन वास्तविक खंड को स्थानांतरित नहीं करता है, यह केवल सचेत करता है कि स्ट्रीम में एक नया खंड उपलब्ध है। <पी> जब कोई नया हिस्सा उपलब्ध होता है, तो स्ट्रीम उपभोक्ता एपीआई इसे स्ट्रीम से पढ़ता है और सभी कनेक्टेड क्लाइंट्स को अग्रेषित करता है। रेडिस उपभोक्ता समूह इस बात पर नज़र रखते हैं कि प्रत्येक ग्राहक ने क्या देखा है ताकि यह गारंटी दी जा सके कि कोई डुप्लिकेट या गुम हुए टुकड़े स्थानांतरित न हों। <पी> कोर स्ट्रीम उपभोक्ता इस तरह दिखता है: const streamKey = `llm:stream:${sessionId}`;
const groupName = `sse-group-${nanoid()}`;
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
});
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
// 👇 built-in Redis stream functionality: only send unseen messages
">",
)) as StreamData[];
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0];
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields);
const validatedMessage = validateMessage(rawObj);
if (validatedMessage) {
controller.enqueue(json(validatedMessage));
}
}
}
};
// 👇 initial read
await readStreamMessages();
const subscription = redis.subscribe(streamKey);
subscription.on("message", async () => {
// 👇 read every time a new chunk is written to stream
await readStreamMessages();
});
<पी> नोट:हम प्रत्येक कनेक्शन पर एक उपभोक्ता समूह बना रहे हैं। यह इतनी अच्छी तरह से काम करता है क्योंकि रेडिस इस ऑपरेशन को निष्क्रियता से संभालता है, उदाहरण के लिए। यदि समूह पहले से मौजूद है तो कुछ नहीं होगा। पूर्ण कोड
SessionID जनरेशन
<पी> अब तक, हमने ग्राहकों के कार्यों, स्ट्रीम जनरेटर और स्ट्रीम उपभोक्ता को व्यक्तिगत रूप से समझने के लिए कोड के अलग-अलग टुकड़ों को देखा है। अब, आइए पूर्ण कार्यान्वयन को देखकर देखें कि ये टुकड़े एक साथ कैसे फिट होते हैं। <पी> आरंभ करने के लिए, केवल nanoid() का उपयोग करने की तुलना में sessionId बनाना अधिक लचीला होना चाहिए . आख़िरकार, यदि वेबसाइट ताज़ा हो जाए या बंद हो जाए तो क्या होगा? पुन:कनेक्ट करने पर, यदि हम इसे कहीं संग्रहीत नहीं करते हैं तो हम जेनरेट की गई सेशन आईडी खो देंगे - इसे तब तक बनाए रखने की आवश्यकता है जब तक पीढ़ी चलती है। <पी> सौभाग्य से localStorage इसके लिए बिल्कुल उपयुक्त है: import { customAlphabet } from "nanoid";
import { useRouter } from "next/navigation";
import { useCallback, useEffect, useState } from "react";
export const useLLMSession = () => {
const [sessionId, setSessionId] = useState<string>("");
const router = useRouter();
const nanoid = customAlphabet("0123456789", 6);
const updateUrlWithSessionId = useCallback(
(id: string) => {
const url = new URL(window.location.href);
url.searchParams.set("sessionId", id);
router.replace(url.toString(), { scroll: false });
},
[router],
);
useEffect(() => {
const urlParams = new URLSearchParams(window.location.search);
const urlSessionId = urlParams.get("sessionId");
const storedSessionId = localStorage.getItem("llm-session-id");
if (urlSessionId) {
localStorage.setItem("llm-session-id", urlSessionId);
setSessionId(urlSessionId);
} else if (storedSessionId) {
setSessionId(storedSessionId);
updateUrlWithSessionId(storedSessionId);
} else {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
}
// eslint-disable-next-line react-hooks/exhaustive-deps
}, []);
const clearSessionId = useCallback(() => {
localStorage.removeItem("llm-session-id");
setSessionId("");
const url = new URL(window.location.href);
url.searchParams.delete("sessionId");
router.replace(url.toString(), { scroll: false });
}, [router]);
const regenerateSessionId = () => {
const newSessionId = nanoid();
localStorage.setItem("llm-session-id", newSessionId);
setSessionId(newSessionId);
updateUrlWithSessionId(newSessionId);
return newSessionId;
};
return {
sessionId,
regenerateSessionId,
clearSessionId,
};
};
ग्राहक
<पी> हमने क्लाइंट के दो सबसे महत्वपूर्ण भाग पहले ही देख लिए हैं:एक स्ट्रीम शुरू करना और एक स्ट्रीम से कनेक्ट करना। एक बार जब हमें अपने एपीआई से पुष्टि मिल जाती है कि जनरेटर चल रहा है, तो हम प्रतिक्रिया-क्वेरी refetch का उपयोग करके स्ट्रीम से जुड़ते हैं। हमारी कनेक्शन क्वेरी शुरू करने के लिए उपयोगिता। <पी> यहां बताया गया है कि सभी टुकड़े एक साथ कैसे फिट होते हैं: ऐप/पेज.tsx"use client"
import { useLLMSession } from "@/use-llm-session"
import { useMutation, useQuery } from "@tanstack/react-query"
import { FormEvent, useRef, useState, useEffect } from "react"
import {
MessageType,
validateMessage,
type ChunkMessage,
type MetadataMessage,
StreamStatus,
} from "@/lib/message-schema"
// precondition = stream is ready to read
class PreconditionFailedError extends Error {
constructor(message: string) {
super(message)
this.name = "PreconditionFailedError"
}
}
export default function Home() {
const { sessionId, regenerateSessionId, clearSessionId } = useLLMSession()
const [prompt, setPrompt] = useState("")
const [status, setStatus] = useState<
"idle" | "loading" | "streaming" | "completed" | "error"
>("idle")
const [response, setResponse] = useState("")
const [chunkCount, setChunkCount] = useState(0)
const controller = useRef<AbortController | null>(null)
const responseRef = useRef<HTMLDivElement>(null)
const isInitialRequest = useRef(true)
// keep generation in viewport
useEffect(() => {
if (responseRef.current) {
responseRef.current.scrollTop = responseRef.current.scrollHeight
}
}, [response])
// start generator
const { mutate, error, isIdle } = useMutation({
mutationFn: async (newSessionId: string) => {
controller.current?.abort()
isInitialRequest.current = false
await fetch("/api/llm-stream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ prompt, sessionId: newSessionId }),
})
},
onSuccess: () => {
setStatus("streaming")
refetch()
},
})
// connect to running stream
const { refetch } = useQuery({
queryKey: ["stream", sessionId],
queryFn: async () => {
if (!sessionId) return null
setResponse("")
setChunkCount(0)
const abortController = new AbortController()
controller.current = abortController
const res = await fetch(`/api/check-stream?sessionId=${sessionId}`, {
headers: { "Content-Type": "text/event-stream" },
signal: controller.current.signal,
})
if (res.status === 412) {
// stream is not yet ready, retry connection
throw new PreconditionFailedError("Stream not ready yet")
}
if (!res.body) return null
const reader = res.body.pipeThrough(new TextDecoderStream()).getReader()
let streamContent = ""
while (true) {
const { value, done } = await reader.read()
if (done) break
if (value) {
const messages = value.split("\n\n").filter(Boolean)
for (const message of messages) {
if (message.startsWith("data: ")) {
const data = message.slice(6)
try {
const parsedData = JSON.parse(data)
const validatedMessage = validateMessage(parsedData)
if (!validatedMessage) continue
switch (validatedMessage.type) {
case MessageType.CHUNK:
const chunkMessage = validatedMessage as ChunkMessage
streamContent += chunkMessage.content
setResponse((prev) => prev + chunkMessage.content)
setChunkCount((prev) => prev + 1)
break
case MessageType.METADATA:
const metadataMessage = validatedMessage as MetadataMessage
if (metadataMessage.status === StreamStatus.COMPLETED) {
setStatus("completed")
}
break
case MessageType.ERROR:
setStatus("error")
break
}
} catch (e) {
console.error("Failed to parse message:", e)
}
}
}
}
}
return streamContent
},
refetchOnWindowFocus: false,
refetchOnMount: false,
retry(failureCount, error) {
if (isInitialRequest.current === true) return false
if (error instanceof PreconditionFailedError) {
return failureCount < 10
}
return false
},
})
const handleSubmit = async (e: FormEvent) => {
e.preventDefault()
setStatus("loading")
const newSessionId = regenerateSessionId()
mutate(newSessionId)
}
const handleReset = () => {
controller.current?.abort()
clearSessionId()
setPrompt("")
setResponse("")
setChunkCount(0)
setStatus("idle")
}
return (
<main className="flex min-h-screen flex-col items-center justify-between p-12 sm:p-24">
<div className="z-10 max-w-5xl w-full items-center justify-between font-mono text-sm">
<h1 className="text-4xl tracking-tight font-bold mb-8 text-center">
Resumable LLM Stream
</h1>
<form onSubmit={handleSubmit} className="mb-8">
<div className="mb-4">
<label htmlFor="prompt" className="block text-sm font-medium mb-2">
Enter your prompt:
</label>
<textarea
autoFocus
id="prompt"
value={prompt}
onChange={(e) => setPrompt(e.target.value)}
className="w-full p-2 border border-zinc-700 rounded-md min-h-[100px] focus:outline-none focus:ring-2 focus:ring-blue-500 focus:border-transparent transition-all duration-200"
placeholder="Ask the AI something..."
disabled={status === "loading" || status === "streaming"}
/>
</div>
<div className="flex gap-4">
<button
type="submit"
disabled={status === "loading" || status === "streaming"}
className="px-4 py-2 bg-blue-600 text-white rounded-md hover:bg-blue-700 disabled:bg-gray-400"
>
{status === "loading"
? "Starting..."
: status === "streaming"
? "Streaming..."
: "Generate Response"}
</button>
<button
type="button"
onClick={handleReset}
className="px-4 py-2 bg-zinc-600 text-white rounded-md hover:bg-zinc-700"
>
Reset
</button>
</div>
</form>
<div className="mt-8">
<h2 className="text-xl tracking-tight font-semibold mb-2">
Response:
</h2>
{status === "error" ? (
<div className="p-4 bg-red-100 border border-red-300 rounded-md text-red-800">
<p className="font-bold">Error:</p>
<p>{error?.message}</p>
</div>
) : status === "idle" && !response ? (
<p className="text-gray-500">
Enter a prompt and click "Generate Response" to see the AI's
response.
</p>
) : (
<div
ref={responseRef}
className="flex flex-col h-96 overflow-y-auto p-4 bg-zinc-900 text-zinc-200 border border-zinc-800 rounded-md whitespace-pre-wrap [&::-webkit-scrollbar]:w-2 [&::-webkit-scrollbar-thumb]:bg-zinc-700 [&::-webkit-scrollbar-track]:bg-zinc-800"
>
<div>{response || "Loading..."}</div>
</div>
)}
{(status === "streaming" || status === "completed") && (
<div className="mt-2 text-sm text-gray-500">
<p>Session ID: {sessionId}</p>
<p>Status: {status}</p>
<p>Chunks received: {chunkCount}</p>
<p>
Connection: {status === "streaming" ? "Active SSE" : "Closed"}
</p>
</div>
)}
</div>
</div>
</main>
)
}
स्ट्रीम जेनरेटर
<पी> यहां स्ट्रीम जनरेटर के लिए संपूर्ण कोड है। यदि एलएलएम पीढ़ी किसी भी बिंदु पर विफल हो जाती है, तो अधिकतम विश्वसनीयता के लिए अपस्टैश वर्कफ़्लो का उपयोग करके इसे स्वचालित रूप से पुनः प्रयास किया जाता है: api/llm-stream/route.tsimport {
MessageType,
StreamStatus,
type ChunkMessage,
type MetadataMessage,
} from "@/lib/message-schema";
import { redis } from "@/utils";
import { openai } from "@ai-sdk/openai";
import { serve } from "@upstash/workflow/nextjs";
import { streamText } from "ai";
interface LLMStreamResponse {
success: boolean;
sessionId: string;
totalChunks: number;
fullContent: string;
}
export const { POST } = serve(async (context) => {
const { prompt, sessionId } = context.requestPayload as {
prompt?: string;
sessionId?: string;
};
if (!prompt || !sessionId) {
throw new Error("Prompt and sessionId are required");
}
const streamKey = `llm:stream:${sessionId}`;
await context.run("mark-stream-start", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.STARTED,
completedAt: new Date().toISOString(),
totalChunks: 0,
fullContent: "",
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
const res = await context.run("generate-llm-response", async () => {
const result = await new Promise<LLMStreamResponse>(
async (resolve, reject) => {
let fullContent = "";
let chunkIndex = 0;
const { textStream } = streamText({
model: openai("gpt-4o"),
prompt,
onError: (err) => reject(err),
onFinish: async () => {
resolve({
success: true,
sessionId,
totalChunks: chunkIndex,
fullContent,
});
},
});
for await (const chunk of textStream) {
if (chunk) {
fullContent += chunk;
chunkIndex++;
const chunkMessage: ChunkMessage = {
type: MessageType.CHUNK,
content: chunk,
};
await redis.xadd(streamKey, "*", chunkMessage);
await redis.publish(streamKey, { type: MessageType.CHUNK });
}
}
},
);
return result;
});
await context.run("mark-stream-end", async () => {
const metadataMessage: MetadataMessage = {
type: MessageType.METADATA,
status: StreamStatus.COMPLETED,
completedAt: new Date().toISOString(),
totalChunks: res.totalChunks,
fullContent: res.fullContent,
};
await redis.xadd(streamKey, "*", metadataMessage);
await redis.publish(streamKey, { type: MessageType.METADATA });
});
});
<पी> संपूर्ण प्रकार-सुरक्षा के लिए, मैंने सभी संदेश स्कीमा को zod: में भी लिखा है message-schema.tsimport { z } from "zod";
export const MessageType = {
CHUNK: "chunk",
METADATA: "metadata",
EVENT: "event",
ERROR: "error",
} as const;
export const StreamStatus = {
STARTED: "started",
STREAMING: "streaming",
COMPLETED: "completed",
ERROR: "error",
} as const;
export const baseMessageSchema = z.object({
type: z.enum([
MessageType.CHUNK,
MessageType.METADATA,
MessageType.EVENT,
MessageType.ERROR,
]),
});
export const chunkMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.CHUNK),
content: z.string(),
});
export const metadataMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.METADATA),
status: z.enum([
StreamStatus.STARTED,
StreamStatus.STREAMING,
StreamStatus.COMPLETED,
StreamStatus.ERROR,
]),
completedAt: z.string().optional(),
totalChunks: z.number().optional(),
fullContent: z.string().optional(),
error: z.string().optional(),
});
export const eventMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.EVENT),
});
export const errorMessageSchema = baseMessageSchema.extend({
type: z.literal(MessageType.ERROR),
error: z.string(),
});
export const messageSchema = z.discriminatedUnion("type", [
chunkMessageSchema,
metadataMessageSchema,
eventMessageSchema,
errorMessageSchema,
]);
export type Message = z.infer<typeof messageSchema>;
export type ChunkMessage = z.infer<typeof chunkMessageSchema>;
export type MetadataMessage = z.infer<typeof metadataMessageSchema>;
export type EventMessage = z.infer<typeof eventMessageSchema>;
export type ErrorMessage = z.infer<typeof errorMessageSchema>;
export const validateMessage = (data: unknown): Message | null => {
const result = messageSchema.safeParse(data);
return result.success ? result.data : null;
};
स्ट्रीम उपभोक्ता
<पी> अंत में, आइए पूर्ण स्ट्रीम उपभोक्ता कार्यान्वयन पर एक नज़र डालें। यह प्रतिस्थापन योग्य कनेक्शन है जो क्लाइंट के कनेक्ट होने पर सभी अनदेखे हिस्सों को स्वचालित रूप से भेजता है: api/check-stream/route.tsimport { redis } from "@/utils"
import { nanoid } from "nanoid"
import { NextRequest, NextResponse } from "next/server"
import {
validateMessage,
MessageType,
type ErrorMessage,
} from "@/lib/message-schema"
export const dynamic = "force-dynamic"
export const maxDuration = 60
export const runtime = "nodejs"
type StreamField = string
type StreamMessage = [string, StreamField[]]
type StreamData = [string, StreamMessage[]]
const arrToObj = (arr: StreamField[]) => {
const obj: Record<string, string> = {}
for (let i = 0; i < arr.length; i += 2) {
obj[arr[i]] = arr[i + 1]
}
return obj
}
const json = (data: Record<string, unknown>) => {
return new TextEncoder().encode(`data: ${JSON.stringify(data)}\n\n`)
}
export async function GET(req: NextRequest) {
const { searchParams } = new URL(req.url)
const sessionId = searchParams.get("sessionId")
if (!sessionId) {
return NextResponse.json(
{ error: "Stream key is required" },
{ status: 400 }
)
}
const streamKey = `llm:stream:${sessionId}`
const groupName = `sse-group-${nanoid()}`
const keyExists = await redis.exists(streamKey)
if (!keyExists) {
return NextResponse.json(
{ error: "Stream does not (yet) exist" },
{ status: 412 }
)
}
try {
await redis.xgroup(streamKey, {
type: "CREATE",
group: groupName,
id: "0",
})
} catch (_err) {}
const response = new Response(
new ReadableStream({
async start(controller) {
const readStreamMessages = async () => {
const chunks = (await redis.xreadgroup(
groupName,
`consumer-1`,
streamKey,
">"
)) as StreamData[]
if (chunks?.length > 0) {
const [_streamKey, messages] = chunks[0]
for (const [_messageId, fields] of messages) {
const rawObj = arrToObj(fields)
const validatedMessage = validateMessage(rawObj)
if (validatedMessage) {
controller.enqueue(json(validatedMessage))
}
}
}
}
await readStreamMessages()
const subscription = redis.subscribe(streamKey)
subscription.on("message", async () => {
await readStreamMessages()
})
subscription.on("error", (error) => {
console.error(`SSE subscription error on ${streamKey}:`, error)
const errorMessage: ErrorMessage = {
type: MessageType.ERROR,
error: error.message,
}
controller.enqueue(json(errorMessage))
controller.close()
})
req.signal.addEventListener("abort", () => {
console.log("Client disconnected, cleaning up subscription")
subscription.unsubscribe()
controller.close()
})
},
}),
{
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
},
}
)
return response
}
त्वरित सारांश और अंतिम शब्द
<पी> हमने अभी-अभी एक बेहद मजबूत एलएलएम स्ट्रीम बनाई है जो नेटवर्क रुकावटों, पेज रिफ्रेश और यहां तक कि पूर्ण डिस्कनेक्शन को भी संभाल सकती है। हमने यह किया: - <पी> डिलीवरी से वियुग्मित पीढ़ी: एलएलएम जेनरेशन को क्लाइंट कनेक्शन से अलग करके, क्लाइंट की समस्याओं की परवाह किए बिना कंटेंट जेनरेशन जारी रहता है।
- <पी> रेडिस स्ट्रीम का उपयोग करके लगातार भंडारण: हम एलएलएम प्रतिक्रिया के प्रत्येक भाग को उत्पन्न होने पर संग्रहीत करने के लिए एक सतत संदेश ब्रोकर के रूप में रेडिस स्ट्रीम का उपयोग कर रहे हैं।
- <पी> रेडिस पब/सब के साथ वास्तविक समय अपडेट: हमने नए खंड उपलब्ध होने पर स्ट्रीम उपभोक्ताओं को सूचित करने के लिए रेडिस पब/सब का उपयोग करके एक अधिसूचना प्रणाली बनाई है।
- <पी> स्वचालित पुनः कनेक्शन: क्लाइंट किसी भी समय पुनः कनेक्ट हो सकता है और स्वचालित रूप से सभी सामग्री प्राप्त कर सकता है, डुप्लिकेट या गायब खंडों के बिना इसकी गारंटी है। इसमें डिस्कनेक्ट के दौरान उत्पन्न सामग्री शामिल है।
- <पी> सत्र प्रबंधन: हमने एक सत्र प्रणाली बनाई है जो उपयोगकर्ताओं को एक ही समय में कई उपकरणों पर स्ट्रीम देखने की अनुमति देती है।
<पी> मूल बात यह है कि अब हम अपने उपयोगकर्ताओं को एक असाधारण उपयोगकर्ता अनुभव (यूएक्स) प्रदान कर रहे हैं। मैं वास्तव में इस दृष्टिकोण की अनुशंसा करता हूं, खासकर यदि आप एलएलएम चैट सेवा जैसा कुछ बना रहे हैं। <पी> पढ़ने के लिए शुभकामनाएँ! यदि आपके पास कोई प्रतिक्रिया है या आप अपस्टैश पर अतिथि लेखक बनना चाहते हैं, तो josh@upstash.com पर संपर्क करें 🙌