बड़े पैमाने पर उपयोगकर्ता वृद्धि के लिए रूबी ऑन रेल्स का विस्तार
<पी> आज हम कुछ रणनीतियों के बारे में जानेंगे जिनका उपयोग आप रूबी ऑन रेल्स एप्लिकेशन को एक विशाल उपयोगकर्ता आधार तक बढ़ाने के लिए कर सकते हैं। <पी> अनुप्रयोगों को बढ़ाने का एक स्पष्ट तरीका उन पर अधिक पैसा फेंकना है। और यह आश्चर्यजनक रूप से अच्छी तरह से काम करता है - कुछ और सर्वर जोड़ें, अपने डेटाबेस सर्वर को अपग्रेड करें, और देखते-ही-देखते, प्रदर्शन संबंधी बहुत सारी समस्याएं खत्म हो जाएंगी। ! <पी> But it is often also possible to scale applications without adding more servers. आज हम इसी पर चर्चा करेंगे। <पी> चलिए आगे बढ़ते हैं! अपने रेल एप्लिकेशन के लिए AppSignal का उपयोग करें
<पी> इससे पहले कि हम स्केलिंग और प्रदर्शन अनुकूलन में उतरें, आपको सबसे पहले यदि की पहचान करनी होगी you need to do this, what the bottlenecks are in your application, and what resources can be scaled. <पी> One easy way to do this is to use AppSignal's performance monitoring and metrics for Ruby. <पी> प्रदर्शन डैशबोर्ड आपको सटीक नियंत्रक क्रियाओं और पृष्ठभूमि नौकरियों को इंगित करने में मदद करता है जो औसतन धीमी हैं। <पी> उदाहरण के लिए, यहां बताया गया है कि ActiveRecord के लिए प्रदर्शन डैशबोर्ड कैसा दिख सकता है: <पी> 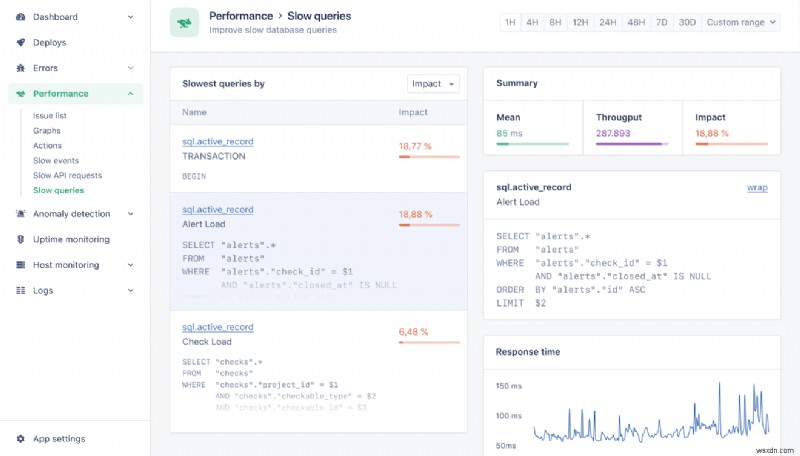 <पी> This gives a good starting point to any scaling journey — whether you decide to add more servers or optimize performance through code. <पी> Now let's move on to one of the simplest techniques you can use to scale your Rails app — caching.
<पी> This gives a good starting point to any scaling journey — whether you decide to add more servers or optimize performance through code. <पी> Now let's move on to one of the simplest techniques you can use to scale your Rails app — caching. रूबी ऑन रेल्स में कैशिंग
<पी> कैशिंग आपको एक ही चीज़ की बार-बार गणना करना बंद करने की अनुमति देता है। <पी> For example, let's say you run a social media platform and there's a very popular post. Caching can immediately help you regain all the CPU cycles you spend rendering that post for every user. और यह केवल उसका एक हिस्सा है कि कैशिंग आपको क्या करने में मदद कर सकती है। <पी> Let's look at all the possible resources that can be cached. कैशिंग दृश्य
<पी> Rendering views can sometimes be an expensive operation, especially when that view has a lot of data to be rendered. यहां तक कि जब ऑपरेशन महंगा न हो, तब भी पहले से रेंडर किए गए दृश्य का उपयोग करने से आपको एक ही दृश्य को लाखों बार रेंडर करने की तुलना में बहुत अधिक प्रदर्शन मिलेगा। <पी> रेल cache का उपयोग करके बॉक्स से बाहर इसका समर्थन करती है सहायक देखें. उदाहरण के लिए, सूची प्रस्तुत करते समय यह प्रत्येक पोस्ट को इस प्रकार कैश कर सकता है: <पी> इसके लिए, रेल स्वचालित रूप से प्रत्येक पोस्ट को एक विशिष्ट कुंजी के तहत कैश करती है जो टेम्पलेट की HTML सामग्री, पोस्ट आईडी और अपडेट टाइमस्टैम्प पर निर्भर करती है। <पी> To read more about this technique, check out the posts Fragment caching in Rails and Rails collection caching. <पी> हालाँकि, ध्यान रखने वाली एक बात यह है कि कैश कुंजियों में नेस्टेड टेम्पलेट सामग्री शामिल नहीं है। इसलिए यदि आप कैश कॉल को एक स्तर से अधिक गहराई तक नेस्ट कर रहे हैं, तो पुराने परिणाम हो सकते हैं। रेल्स में रूसी डॉल कैशिंग में इसके बारे में और पढ़ें। कैशिंग प्रतिक्रियाएँ
<पी> दृश्यों/अंशों को कैशिंग करने के अलावा, आप GET की पूरी प्रतिक्रिया को कैश करना भी चुन सकते हैं अनुरोध. यह If-None-Match के माध्यम से समर्थित है और If-Modified-Since ब्राउज़रों द्वारा भेजे गए हेडर. <पी> जब एक If-None-Match header is present on the request, the server can return a 304 Not Modified यदि प्रतिक्रिया में कोई परिवर्तन नहीं है तो बिना सामग्री वाली प्रतिक्रिया। सर्वर-गणना Etag is compared with the value inside that header. <पी> इसी तरह, यदि If-Modified-Since हेडर If-None-Match के बिना मौजूद है , सर्वर 304 Not Modified लौटा सकता है बिना किसी सामग्री के प्रतिक्रिया (जब तक कि उस तिथि के बाद से प्रतिक्रिया नहीं बदली है)। <पी> रेल नियंत्रक क्रियाओं के अंदर ऐसा करने के आसान तरीके प्रदान करता है। आप बस लिख सकते हैं: <पी> रेल कैशिंग का समर्थन करने, आने वाले हेडर को संभालने और डेटा नहीं बदले जाने पर 304 के साथ प्रतिक्रिया देने के लिए सभी आवश्यक हेडर भेजेगी। जब तक चीजें नहीं बदलतीं, सर्वर पूर्ण दृश्यों को दोबारा प्रस्तुत करना छोड़ सकता है। You can read more about advanced configuration for this strategy in Client-side caching in Rails:conditional GET requests. कैशिंग मान
<पी> अंत में, कच्चे मूल्यों को कैश करना भी संभव है (कुछ भी जिसे कैश स्टोर में क्रमबद्ध किया जा सकता है)। This is usually useful to cache the results of resource-intensive or slow operations and avoid performing them again. <पी> इस कैशिंग से लाभान्वित होने वाले मूल्य की पहचान करना काफी हद तक एप्लिकेशन पर निर्भर करता है, लेकिन आमतौर पर, आपकी सबसे धीमी घटनाओं को देखने से आपको सही दिशा में मदद मिल सकती है। <पी> Finally, when you identify what to cache, the API that Rails provides for this is very simple to use: <पी> उपरोक्त कोड perform_the_slow_computation होगा only once and then cache the value under the cache_key_with_version कुंजी. अगली बार जब उसी कोड को कॉल किया जाएगा, तो रेल्स पहले जांच करेगी कि क्या हमारे पास पहले से ही कैश्ड वैल्यू है और perform_the_slow_computation को ट्रिगर करने के बजाय उसका उपयोग करेगी। फिर से. <पी> इस कैशिंग रणनीति का सबसे महत्वपूर्ण हिस्सा एक अच्छी कैश कुंजी की गणना करना है जो मूल्य की गणना में उपयोग किए गए सभी इनपुट पर निर्भर करता है। This is to ensure we don’t keep using a stale value. कैश स्टोर
<पी> अब जब हम जानते हैं कि क्या कैश करना है और कैश में चीजों को स्टोर करने के लिए रेल्स कौन सी तकनीकें प्रदान करता है, तो अगला तार्किक सवाल यह है - हम इस डेटा को कहां कैश करते हैं? रेल्स कई इन-बिल्ट कैश स्टोर एडाप्टर के साथ आती है। The most popular cache stores for production use cases are Redis and Memcached. कुछ अन्य विकल्प भी हैं - फ़ाइल स्टोर और मेमोरी स्टोर। A full discussion of these stores can be found in the post Rails' built-in cache stores:an overview. <पी> File and memory stores can be great for development use to get things up and running quickly. However, they are usually unsuitable for production, especially if you're working in a distributed setup with multiple servers. Redis और memcached दोनों उत्पादन उपयोग के लिए उपयुक्त हैं। Which one you use usually depends on the application. रूबी ऑन रेल्स में बैकग्राउंड वर्कर्स
<पी> अधिकांश अनुप्रयोगों को मेलर्स के लिए पृष्ठभूमि कार्यों, नियमित सफाई, या किसी अन्य समय लेने वाले ऑपरेशन की आवश्यकता होती है जिसके लिए उपयोगकर्ता की उपस्थिति की आवश्यकता नहीं होती है। संभावना है, आपके पास पहले से ही एक पृष्ठभूमि कार्यकर्ता स्थापित है। <पी> जब भी आप खुद को कुछ भी ऐसा करते हुए पाएं जिसे करने में नियंत्रक कार्रवाई के अंदर एक सेकंड से अधिक समय लगता है, तो देखें कि क्या आप इसके बजाय इसे पृष्ठभूमि कार्यकर्ता के पास ले जा सकते हैं। यह उपयोगकर्ता-सामना वाले ऑपरेशन से लेकर बड़ी तालिका के अंदर डेटा की खोज करने से लेकर एपीआई विधि तक हो सकता है जो बड़ी मात्रा में डेटा ग्रहण करता है। उदाहरण कार्यान्वयन
<पी> कस्टम जॉब चलाने के लिए, रेल्स एक्टिव जॉब फ्रेमवर्क प्रदान करता है। आइए देखें कि हम एक बहुत ही जटिल फ़िल्टरिंग तर्क को पृष्ठभूमि कार्य में स्थानांतरित करने के लिए इसका उपयोग कैसे कर सकते हैं। सबसे पहले, आइए अपना पृष्ठभूमि कार्य बनाएँ: <पी> हम इस कार्य को नियंत्रक से इस प्रकार चला सकते हैं: <पी> जब हम डेटा की गणना करने और परिणाम देने के लिए अपने काम की प्रतीक्षा करते हैं तो हमें अपने टेम्पलेट पर एक लोडिंग संकेतक प्रस्तुत करने की आवश्यकता होती है। <पी> लेकिन हम अपने काम से परिणाम कैसे प्राप्त कर सकते हैं? टर्बो इसे सचमुच आसान बनाता है। उदाहरण के लिए, दृश्य के अंदर, हम turbo_stream_from का उपयोग करके एक विशिष्ट अधिसूचना चैनल पर टर्बो-स्ट्रीम घटनाओं की सदस्यता ले सकते हैं। . <पी> इसका उपयोग करते हुए, आइए अपने टेम्पलेट लिखें: <पी> चूंकि डेटा को प्रारंभिक नियंत्रक कार्रवाई में परिभाषित नहीं किया गया है, हम केवल एक लोडिंग संकेतक प्रस्तुत करेंगे। आइए अब अपने काम से परिणाम दें: <पी> यहां महत्वपूर्ण भाग notify_completed है विधि. यह Turbo::StreamsChannel का उपयोग करता है, एक रिप्लेस इवेंट को [user, :huge_datasets] पर प्रसारित करता है। अधिसूचना स्ट्रीम जिसे हमने अपने दृष्टिकोण से सदस्यता ली है। <पी> हमारे नियंत्रक से पृष्ठभूमि नौकरियों में जटिल संचालन को स्थानांतरित करने के लिए हमें यही सब कुछ चाहिए। कार्यों को पृष्ठभूमि में ले जाने का मुख्य लाभ यह है कि पृष्ठभूमि कार्यकर्ताओं को वेब सर्वर से स्वतंत्र रूप से स्केल किया जा सकता है। यह वेब सर्वर साइड पर संसाधनों को काफी हद तक मुक्त कर देता है। उपयोगकर्ता के लिए, ऐसे इंटरफ़ेस अधिक प्रतिक्रियाशील महसूस होते हैं क्योंकि हम तुरंत प्रतिक्रिया दे सकते हैं और क्रमिक रूप से परिणाम दे सकते हैं। <पी> ध्यान दें :यदि आपको पृष्ठभूमि नौकरी कार्यकर्ता के बीच निर्णय लेने में सहायता की आवश्यकता है, तो विलंबित नौकरी बनाम साइडकीक पढ़ें:कौन सा बेहतर है? अपने रूबी ऑन रेल्स एप्लिकेशन में डेटाबेस को स्केल करना
<पी> अंतिम स्केलेबल संसाधन जिस पर हम इस पोस्ट में चर्चा करेंगे वह डेटाबेस है। डेटाबेस अधिकांश अनुप्रयोगों का मूल होता है। जैसे-जैसे डेटा और उस डेटा तक पहुंचने वाले सर्वरों की संख्या बढ़ती है, डेटाबेस को लोड महसूस होने लगता है। <पी> डेटाबेस को स्केल करने का सबसे आसान तरीका डेटाबेस सर्वर में अधिक प्रोसेसिंग पावर और मेमोरी जोड़ना है। वेब सर्वर को स्केल करने के विपरीत, डेटाबेस के साथ ऐसा करना आमतौर पर बहुत धीमा ऑपरेशन है, खासकर यदि आपके पास उच्च भंडारण है। <पी> डेटाबेस को स्केल करने का दूसरा विकल्प एकाधिक डेटाबेस का उपयोग करके या अपने डेटाबेस को साझा करके क्षैतिज रूप से स्केल करना है। इसके बारे में अधिक जानकारी के लिए सक्रिय रिकॉर्ड वाले एकाधिक डेटाबेस देखें। <पी> इसके बजाय, हम PostgreSQL को देखकर आपके डेटाबेस के प्रदर्शन को अनुकूलित करने पर ध्यान केंद्रित करेंगे। PostgreSQL में समय लेने वाली क्वेरीज़ ढूंढें
<पी> सबसे पहले, हमें अपने सबसे अधिक समय लेने वाले प्रश्नों की पहचान करने की आवश्यकता है। जिस तरह से हम ऐसा कर सकते हैं वह pg_stat_statements को क्वेरी करना है तालिका जिसमें सर्वर पर निष्पादित सभी SQL कथनों के आंकड़े शामिल हैं। आइए देखें कि हम उच्चतम रन टाइम वाली शीर्ष 100 क्वेरीज़ कैसे ढूंढ सकते हैं: <पी> यह क्वेरी, कॉल की संख्या और इन क्वेरीज़ का औसत रन टाइम लौटाएगा। उन लोगों को ढूंढने का प्रयास करें जिनके बारे में आपको लगता है कि वे तेज़ हो सकते हैं और विश्लेषण करें कि वे धीमे क्यों थे। <पी> आप EXPLAIN भी चला सकते हैं या EXPLAIN ANALYZE क्रमशः क्वेरी योजना और वास्तविक निष्पादन विवरण देखने के लिए क्वेरी पर। <पी> परिणामों में ध्यान देने योग्य सबसे महत्वपूर्ण चीज़ों में से एक है Seq Scan , जो इंगित करता है कि पोस्टग्रेज को क्वेरी चलाने के लिए क्रमिक रूप से सभी रिकॉर्ड से गुजरना होगा। यदि ऐसा होता है, तो आपके द्वारा फ़िल्टर किए गए कॉलम में एक इंडेक्स जोड़कर उस अनुक्रमिक स्कैन को बायपास करने का प्रयास करें। सर्वाधिक अनुक्रमिक स्कैन वाली तालिकाएँ
<पी> एक और उपयोगी क्वेरी जो मुझे चलाना पसंद है वह है किसी तालिका के विरुद्ध चलाए गए अनुक्रमिक स्कैन की कुल संख्या ज्ञात करना: <पी> यदि आपको इस परिणाम से एक बहुत बड़ी तालिका (पंक्तियों की अधिक संख्या के साथ) और उच्च गिनती मान दिखाई देती है, तो आपको समस्या है। उस तालिका के विरुद्ध सभी प्रश्नों की जांच करने का प्रयास करें, उन प्रश्नों को ढूंढें जो अनुक्रमिक स्कैन चला सकते हैं, और उसे कम करने के लिए सूचकांक जोड़ें। सूचकांक उपयोग
<पी> आप इस क्वेरी को चलाकर सूचकांक उपयोग के बारे में आंकड़े भी पा सकते हैं: <पी> यह प्रत्येक तालिका के लिए सूचकांक उपयोग का प्रतिशत लौटाता है। कम संख्या का मतलब है कि आप उस तालिका में कुछ अनुक्रमणिकाएँ खो रहे हैं। समाप्ति
<पी> इस पोस्ट में, हमने कैशिंग और बैकग्राउंड वर्कर्स सहित आपके रूबी ऑन रेल्स एप्लिकेशन को स्केल करने के लिए कई रणनीतियों की खोज की। हमने आपके PostgreSQL डेटाबेस के प्रदर्शन को अनुकूलित करने पर भी ध्यान दिया। <पी> रेल आपके एप्लिकेशन में प्रदर्शन अनुकूलन की कई परतें जोड़ना वास्तव में आसान बनाती है। <पी> स्केलेबिलिटी के साथ सबसे महत्वपूर्ण विचार किसी एप्लिकेशन में बाधाओं की पहचान करना है, इससे पहले कि हम उन पर कार्रवाई कर सकें। एक अच्छा प्रदर्शन निगरानी उपकरण मदद कर सकता है। यदि आपको इसकी आवश्यकता है, तो रूबी के लिए ऐपसिग्नल देखें। <पी> हैप्पी कोडिंग! <पी> पी.एस. यदि आप प्रेस से हटते ही रूबी मैजिक पोस्ट पढ़ना चाहते हैं, तो हमारे रूबी मैजिक न्यूज़लेटर की सदस्यता लें और एक भी पोस्ट न चूकें!


