<पी> पैमाने के लिए वेब अनुप्रयोगों पर विचार करते समय पृष्ठभूमि कार्य मुख्य स्तंभों में से एक हैं। मूल विचार सरल है:एक ग्राहक आपके वेब एप्लिकेशन से अनुरोध करता है और उस अनुरोध को संभालने में, आपका ऐप कई समय-महंगे कार्य करता है। क्लाइंट को तेज़ी से प्रतिक्रिया देने की अनुमति देने के लिए, ऐप एक बैकग्राउंड जॉब को बैकग्राउंड प्रोसेसिंग सिस्टम में शामिल करता है। फिर पृष्ठभूमि प्रसंस्करण को गणना या I/O संचालन जैसे सभी भारी भार उठाने का काम सौंपा जाता है। अपने वेब एप्लिकेशन को स्केल करते समय पृष्ठभूमि नौकरियों पर प्रभावी ढंग से निर्भर होना सबसे महत्वपूर्ण बिल्डिंग ब्लॉक्स में से एक है। <पी> रेल डेवलपर्स के रूप में, हमारे पास चुनने के लिए कई शानदार लाइब्रेरी हैं, सभी अलग-अलग फायदे, नुकसान और यहां तक कि बैकएंड डेटाबेस के साथ हैं। ये लाइब्रेरी किसी भी भारी सामान को उतारना आसान बनाती हैं, जिससे हमारे एप्लिकेशन तेजी से प्रतिक्रिया दे सकते हैं और कम संसाधनों के साथ अधिक उपयोगकर्ताओं को सेवा प्रदान कर सकते हैं। <पी> हाल तक, हम हनीबेजर के अधिकांश पृष्ठभूमि प्रसंस्करण कार्यों को करने के लिए साइडकीक का उपयोग करते थे। यह हमारे द्वारा उपयोग किए जाने वाले भारी मात्रा में डेटा को संसाधित करने के लिए एक तेज़ उपयोगकर्ता अनुभव और एक मजबूत पाइपलाइन बनाए रखने में हमारी मदद करने में सहायक रहा है। साइडकीक हमारे लिए कहां कम पड़ जाता है?
<पी> अपनी विश्वसनीयता के बावजूद, रेडिस की कुछ सीमाएँ हैं। हाल तक, हम अपने सभी कार्य प्रसंस्करण के लिए साइडकीक का उपयोग करते थे, जिसमें हमारे त्रुटि-ट्रैकिंग एंडपॉइंट के लिए इनजेस्ट को संभालना भी शामिल था। त्रुटि ट्रैफ़िक अत्यधिक परिवर्तनशील है. हमारी कतारों में अक्सर नौकरियों की संख्या 10 गुना या 20 गुना होती है - जिसके परिणामस्वरूप बड़े पैमाने पर बैकलॉग होता है जब तक कि हमारी ऑटोस्केलिंग पर्याप्त श्रमिकों को इकट्ठा नहीं कर पाती। लेकिन बड़ी समस्या हमारे ElastiCache क्लस्टर में मेमोरी ख़त्म होने की थी। <पी> हमारे ElastiCache क्लस्टर के माध्यम से पर्याप्त जॉब ट्रैफ़िक चल रहा था, जिससे डाउनस्ट्रीम प्रोसेसिंग में किसी भी महत्वपूर्ण देरी से क्लस्टर की मेमोरी खत्म होने का जोखिम होगा। जबकि हम गैर-कतार डेटा संग्रहीत करने के लिए एक अलग क्लस्टर का उपयोग करते हैं, समय के साथ, हमारे पास प्राथमिक क्लस्टर में कुछ गैर-कतार डेटा भी दिखाई देते हैं, जो तब आउट-ऑफ-मेमोरी त्रुटियों के मामले में बेदखल हो सकते हैं। हालाँकि, अधिक गंभीर मुद्दा, क्लस्टर की मेमोरी खत्म होने पर नई नौकरियों को स्वीकार करने में सक्षम नहीं होना था। <पी> एक द्वितीयक मुद्दा यह है कि Redis/ElastiCache volatile-lru का उपयोग करता है डिफ़ॉल्ट रूप से बेदखली नीति. इसका परिणाम यह है कि उच्च मेमोरी उपयोग के समय, रेडिस टीटीएल सेट के साथ कम से कम हाल ही में उपयोग किए गए डेटा को हटा देगा। एक बिंदु पर, हनीबैगर में एक कार्यक्रम था जहां हमारी मेमोरी का उपयोग इतना अधिक था कि रेडिस ने अपना कैश साफ़ करना शुरू कर दिया, जबकि हमने ऐसा करने का इरादा नहीं किया था। सौभाग्य से, निकाला गया डेटा प्रतिलिपि प्रस्तुत करने योग्य था (इसलिए टीटीएल), इसलिए हमने कोई स्थायी डेटा नहीं खोया। <पी> फिर भी, इसने हमारे सामने एक प्रश्न छोड़ दिया है जिसका समाधान आवश्यक है - यदि इसी तरह की घटना घटती है और हम डेटा खोना शुरू कर देते हैं जिसे हम पुनर्निर्माण नहीं कर सकते तो क्या होगा? हम यह कैसे सुनिश्चित कर सकते हैं कि हम ग्राहक डेटा कभी न खोएं? ग्राहक त्रुटि डेटा को संभालना हमारे व्यवसाय का मूल है, इसलिए हमें एक ऐसी प्रणाली की आवश्यकता है जो डेटा हानि के प्रति लचीली हो। डेटा अंतर्ग्रहण के लिए काफ्का का उपयोग करना
<पी> काफ्का एक वितरित इवेंट पाइपलाइन है जो स्केलेबिलिटी और लचीलापन दोनों प्रदान करती है। इनसाइट्स के हमारे हालिया लॉन्च के साथ, हमने अपने इवेंट डेटा को संसाधित करने के लिए काफ्का को बुनियादी ढांचे के रूप में खड़ा करने का काफी अनुभव प्राप्त किया। उसके बाद, हम अपने त्रुटि अंतर्ग्रहण डेटा को संसाधित करने के लिए उसी प्रौद्योगिकी स्टैक का उपयोग करना चाहते थे। हमारा लक्ष्य काफ्का का उपयोग करके बेहतर विस्तारशीलता और अधिक किफायती लागत के साथ अनावश्यक भंडारण प्राप्त करना है। <पी> चूँकि हम इनसाइट्स के लिए अपना स्वयं का AWS MSK क्लस्टर चला रहे थे, हमारे पास पहले से ही बुनियादी ढाँचा और ऑटोस्केलिंग सेटअप था। इसका मतलब यह था कि हमें "बस" कुछ विषय सेट करने थे और कुछ उपभोक्ता बनाने थे जो हमारे साइडकीक कार्यकर्ताओं के समान कोड चलाते थे। यह अवधारणा बहुत सरल थी जिससे हमें अपने काफ्का उपभोक्ताओं की फाइन-ट्यूनिंग पर अधिक ध्यान केंद्रित करने का मौका मिला। साइडकीक से कराफ्का की ओर पलायन
<पी> हनीबैगर की वास्तुकला एक राजसी मोनोलिथ के रूप में की गई है, और काराफ्का हमें उसी वास्तुकला को बनाए रखने में मदद करता है। हम अपने कुछ इनसाइट डेटा को संसाधित करने के लिए पहले से ही कराफ्का का उपयोग कर रहे हैं, इसलिए कुछ नए उपभोक्ताओं को जोड़ना एक सरल कार्य था। <पी> कराफ्का और साइडकीक के बीच मुख्य अंतर यह है कि नौकरियां कैसे प्राप्त की जाती हैं। कराफ़्का के साथ, नौकरियों को एक ही उपभोक्ता दौर में एक साथ बैच और संसाधित किया जाता है। उपभोक्ता में, हम संदेशों की श्रृंखला पर पुनरावृति कर सकते हैं और साइडकीक वर्कर को इनलाइन चला सकते हैं: class NoticeConsumer < ApplicationConsumer
def consume
messages.each do |message|
NoticeWorker.new.perform(message.payload)
end
end
end
<पी> हमें एक और अंतर पर विचार करना था कि त्रुटि प्रबंधन कैसे काम करता है। साइडकीक के साथ, चूंकि प्रत्येक कार्य परमाणु है, एक कार्यकर्ता पुनः प्रयास और विफलता कॉलबैक के माध्यम से अपनी त्रुटि को संभालता है। काफ्का के बैचिंग व्यवहार के साथ, त्रुटियों से निपटने के लिए अधिक विकल्प हैं। सबसे विशेष रूप से, कराफ़्का डेड लेटर क्यू नामक एक तंत्र प्रदान करता है। यह आपको बैच या व्यक्तिगत आधार पर त्रुटि प्रबंधन निर्दिष्ट करने की अनुमति देता है। dead_letter_queue(
topic: "ingestion.errors.dead",
max_retries: 5,
independent: true
)
<पी> जब भी कराफ्का उपभोक्ता को किसी व्यक्तिगत संदेश को संसाधित करने में विफलता का सामना करना पड़ता है, तो वह 5 बार पुन:संसाधित करने का प्रयास करेगा। यदि यह 5वें प्रयास में विफल रहता है, तो संदेश निर्दिष्ट विषय पर भेजा जाएगा। independent: true विकल्प उपभोक्ता को बताता है कि पूरे बैच के बजाय केवल विफल संदेश को DLQ पर भेजने की आवश्यकता है। काराफ्का की निगरानी और स्केलिंग
<पी> जैसा कि यह पता चला है, कराफ्का उपभोक्ताओं की निगरानी और स्केलिंग काफी जटिल है। ऐसी कई चीज़ें हैं जिन्हें आप AWS/MSK और Karafka दोनों से ट्रैक कर सकते हैं, और कई नॉब जिन्हें आप अपने सिस्टम को ट्यून करने के लिए घुमा सकते हैं। आपका कोड क्या कर रहा है, डेटा प्रवाह का व्यवहार, इस पर सावधानीपूर्वक ध्यान देने की आवश्यकता है। <पी> AWS क्लाउडवॉच के साथ हम बहुत सी चीज़ों पर नज़र रखते हैं, लेकिन यहां कुछ काफ्का-विशिष्ट मेट्रिक्स हैं जिन पर हम नज़र डालते हैं: - SumOffsetLag — किसी निर्दिष्ट विषय और उपभोक्ता समूह के लिए, यह सभी विभाजनों में सभी ऑफसेट अंतराल का योग है।
- अनुमानित MaxTimeLag — एक निर्दिष्ट विषय और उपभोक्ता समूह के लिए, यह अनुमानित है वर्तमान ऑफसेट के सभी विभाजनों को समझने में कितना समय लगेगा।
<पी> काराफ़्का कुछ बेहतरीन उपकरण भी प्रदान करता है, लेकिन आपको इस डेटा को प्रकाशित करना होगा और इसे स्वयं संग्रहीत करना होगा: - processing_lag * - यह मान संदेशों के प्रत्येक उपभोग किए गए बैच के लिए उपलब्ध है। यह आपको बताता है कि काफ्का को काफ्का से संदेश लेने और उसे संसाधित करने में कितना समय लगा।
- खपत_लैग * - यह मान processing_lag के समान है सिवाय इसके कि यह वह समय है जब बैच का अंतिम संदेश काफ्का प्रणाली में प्रवेश करता है, जब तक कि आपका उपभोक्ता इसे संसाधित करना शुरू नहीं कर देता।
- अवधि * - यह वह समय है जो उपभोक्ता को संदेशों के पूरे बैच को संसाधित करने में लगता है।
<पी> जैसा कि यह पता चला है, साइडकीक प्रक्रियाओं को स्केल करना कराफ्का उपभोक्ता प्रक्रियाओं को स्केल करने से बहुत अलग है। साइडकीक के समानांतरीकरण को बढ़ाते समय, आप उन सभी प्रक्रियाओं को जोड़ सकते हैं जिन्हें आपका रेडिस इंस्टेंस संभाल सकता है। काफ्का के साथ, आपके विषय में प्रति विभाजन अधिकतम 1 प्रक्रिया होनी अनिवार्य है। एक सामान्य नियम के रूप में, आप अपनी योजना से अधिक विभाजन करना चाहेंगे क्योंकि एक काफ्का उपभोक्ता को 1 से अधिक विभाजन सौंपे जा सकते हैं। <पी> याद रखने वाली एक और बात यह है कि काफ्का उपभोक्ताओं को बढ़ाना और घटाना एक बहुत लंबा ऑपरेशन हो सकता है। उपभोक्ता समूह में उपभोक्ताओं को जोड़ने और हटाने के लिए समूह को स्वयं को पुनर्संतुलित करने की आवश्यकता होती है। इसका अर्थ है आवश्यकतानुसार विभाजनों को पुनः निर्दिष्ट करना। पुन:असाइनमेंट के दौरान, उपभोक्ता संदेशों को संसाधित करना बंद कर देते हैं। हालाँकि आप sticky-cooperative से इस समस्या को कुछ हद तक कम कर सकते हैं असाइनमेंट, यदि आप संभव हो तो संसाधनों का अत्यधिक प्रावधान करके पुनर्संतुलन से बचना चाहते हैं। <पी> हम वर्तमान में SumOffsetLag की निगरानी कर रहे हैं हमारे स्केलिंग मेट्रिक्स में से एक के रूप में। ध्यान देने योग्य एक महत्वपूर्ण बात यह है कि पुनर्संतुलन के दौरान, यह मीट्रिक रिपोर्ट नहीं की जाती है। तो जैसा कि आप कल्पना कर सकते हैं, पुनर्संतुलन अवधि के दौरान, पुनर्संतुलन समाप्त होने तक यह मीट्रिक काफी बढ़ जाएगी। यह एक और कारण है कि स्केलिंग को न्यूनतम रखना महत्वपूर्ण है। हनीबैगर में कराफ्का के लिए आगे क्या है?
<पी> हम एक महीने से अधिक समय से अपना काफ्का/कराफ्का कार्यान्वयन 100% पर चला रहे हैं और यह कहना सुरक्षित है कि हम काफी संतुष्ट हैं। फिर भी, यह जानना बहुत अच्छा है कि जरूरत पड़ने पर हम हमेशा एक बटन दबाकर साइडकीक पर वापस आ सकते हैं। जब इनमें से किसी भी सिस्टम पर रखरखाव कार्य की आवश्यकता होती है तो यह हमें और भी अधिक लचीलापन प्रदान करता है। <पी> साइडकीक से कराफ्का की ओर प्रवास की प्रक्रिया में, हमने काफ्का और कराफ्का के साथ काम करने के बारे में भी बहुत कुछ सीखा। यदि आपने हनीबेजर रत्न के नवीनतम संस्करण को अपडेट नहीं किया है, तो आपको इसे देखना चाहिए! मैंने कराफ़्का प्लगइन में कुछ नई सुविधाएँ जोड़ीं। जब आपके पास इनसाइट्स सक्षम होगी, तो हमारा रत्न आपको आपके काफ्का सिस्टम के समग्र स्वास्थ्य पर बेहतर दृष्टिकोण देने के लिए कुछ महत्वपूर्ण आँकड़ों को ट्रैक करना शुरू कर देगा। <पी> इसके अलावा, अब हमारे पास इनसाइट्स कराक्फा डैशबोर्ड है जो आपको इस डेटा को देखने में मदद करेगा और आपको यह बेहतर समझ देगा कि आपके काफ्का उपभोक्ता कैसे व्यवहार कर रहे हैं। कराफ़्का डैशबोर्ड को प्लगइन के लिए मेट्रिक्स को सक्षम करने की आवश्यकता है। ऐसा करने के लिए अपने honeybadger.yml में निम्नलिखित कॉन्फ़िगरेशन जोड़ें : karafka:
insights:
metrics: true
<पी> डैशबोर्ड कैसा दिखता है इसका एक नमूना यहां दिया गया है: <पी> 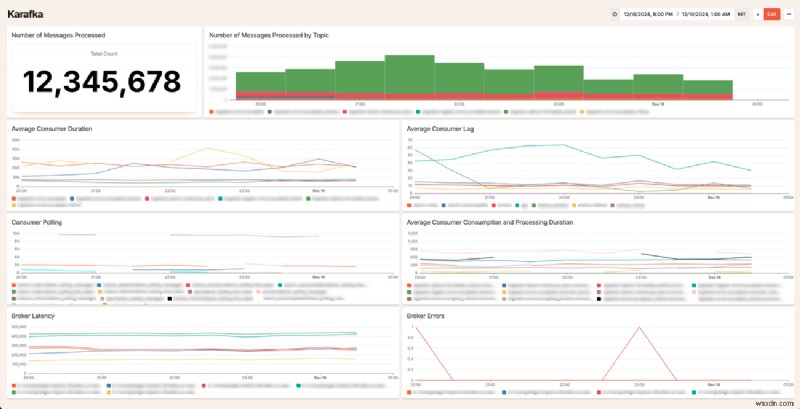 <पी> हम यह देखने के लिए उत्साहित हैं कि हमारे ग्राहक अपने स्वयं के काफ्का सिस्टम को बेहतर बनाने के लिए इस डेटा का उपयोग कैसे करते हैं। यदि आपके पास इस बारे में कोई प्रश्न है कि हम साइडकीक से काराफ्का की ओर कैसे चले गए, या हम आम तौर पर काफ्का का उपयोग कैसे करते हैं, तो बेझिझक हमसे संपर्क करें!
<पी> हम यह देखने के लिए उत्साहित हैं कि हमारे ग्राहक अपने स्वयं के काफ्का सिस्टम को बेहतर बनाने के लिए इस डेटा का उपयोग कैसे करते हैं। यदि आपके पास इस बारे में कोई प्रश्न है कि हम साइडकीक से काराफ्का की ओर कैसे चले गए, या हम आम तौर पर काफ्का का उपयोग कैसे करते हैं, तो बेझिझक हमसे संपर्क करें!