प्रीफ़िक्स ट्री (जिसे ट्री भी कहा जाता है) एक डेटा संरचना है जो आपको एक शब्द सूची व्यवस्थित करने और एक विशिष्ट उपसर्ग से शुरू होने वाले शब्दों को जल्दी से खोजने में मदद करती है।
उदाहरण के लिए, आप अपने शब्दकोश में वे सभी शब्द पा सकते हैं जो "ca" से शुरू होते हैं, जैसे "बिल्ली" या "केप"।
इस तस्वीर को देखें:
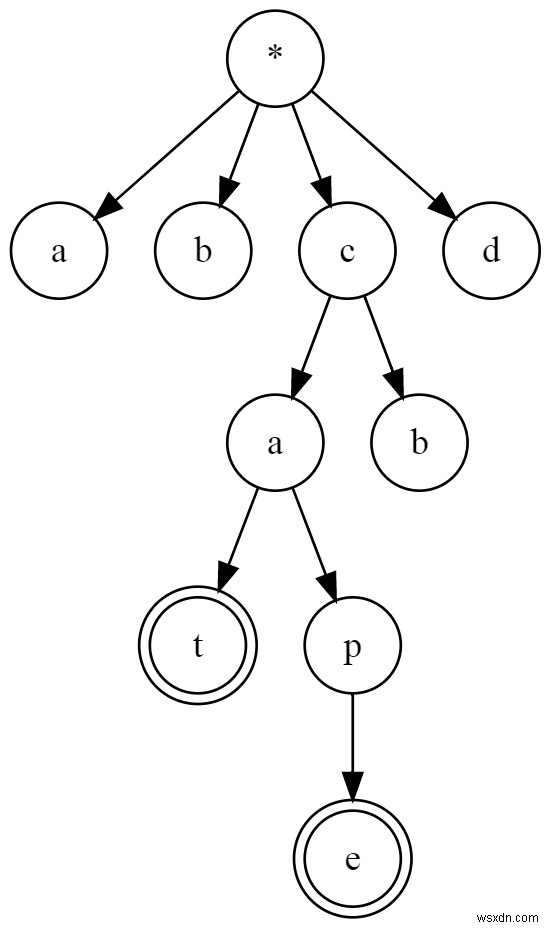
यह एक उपसर्ग वृक्ष है।
आप रूट से फॉलो कर सकते हैं (* ) एक चिह्नित नोड के लिए (जैसे e और t ) शब्दों को खोजने के लिए।
इस लेख में आप सीखेंगे कि रूबी में अपना खुद का उपसर्ग पेड़ कैसे लागू करें और समस्याओं को हल करने के लिए इसका उपयोग कैसे करें!
उपसर्ग ट्री कार्यान्वयन
रूबी में इसे लागू करने के लिए मैंने Node . का उपयोग करने का निर्णय लिया कुछ विशेषताओं के साथ वर्ग:
- मान (एक वर्ण)
- "शब्द" चर। एक सही / गलत मान जो आपको बताता है कि क्या यह एक मान्य शब्द है
- "अगला" सरणी। यह सभी वर्णों को संग्रहीत करता है (
Node. के रूप में) ऑब्जेक्ट) जो इसके बाद पेड़ में आते हैं
यह रहा कोड :
class Node
attr_reader :value, :next
attr_accessor :word
def initialize(value)
@value = value
@word = false
@next = []
end
end
अब हमें रूट नोड और इन नोड्स के साथ काम करने के तरीकों को होल्ड करने के लिए एक क्लास की आवश्यकता है।
आइए देखें Trie कक्षा:
class Trie
def initialize
@root = Node.new("*")
end
end
इस वर्ग के अंदर हमारे पास निम्नलिखित विधियाँ हैं:
def add_word(word)
letters = word.chars
base = @root
letters.each { |letter| base = add_character(letter, base.next) }
base.word = true
end
def find_word(word)
letters = word.chars
base = @root
word_found =
letters.all? { |letter| base = find_character(letter, base.next) }
yield word_found, base if block_given?
base
end
दोनों विधियां किसी दिए गए शब्द को वर्णों की एक सरणी में विभाजित करती हैं (chars . का उपयोग करके विधि)।
फिर हम जड़ से शुरू होने वाले पेड़ को नेविगेट करते हैं और या तो एक चरित्र ढूंढते हैं या इसे जोड़ते हैं।
यहां सहायक तरीके दिए गए हैं (Trie . के अंदर भी) कक्षा):
def add_character(character, trie)
trie.find { |n| n.value == character } || add_node(character, trie)
end
def find_character(character, trie)
trie.find { |n| n.value == character }
end
def add_node(character, trie)
Node.new(character).tap { |new_node| trie << new_node }
end
एक चरित्र जोड़ने के लिए हम जांचते हैं कि क्या यह पहले से मौजूद है (find . का उपयोग करके) तरीका)। अगर ऐसा होता है तो हम नोड वापस कर देते हैं।
अन्यथा हम इसे बनाते हैं और नया नोड लौटाते हैं।
फिर हमारे पास include? . भी है विधि:
def include?(word)
find_word(word) { |found, base| return found && base.word }
end
अब हम अपनी नई डेटा संरचना का उपयोग शुरू करने के लिए तैयार हैं और देखें कि हम इसके साथ क्या कर सकते हैं 🙂
उपयोग और उदाहरण ट्राई करें
आइए अपने पेड़ में कुछ शब्द जोड़कर शुरू करें:
trie = Trie.new
trie.add_word("cat")
trie.add_word("cap")
trie.add_word("cape")
trie.add_word("camp")
आप जांच सकते हैं कि पेड़ में कोई शब्द इस तरह शामिल है या नहीं:
p trie.include?("cape")
# true
p trie.include?("ca")
# false
तो इस डेटा संरचना के कुछ उपयोग क्या हैं?
- शब्दों का खेल सुलझाना
- वर्तनी जांच
- स्वतः पूर्ण
अपने पेड़ में लोड करने के लिए आपको एक अच्छे शब्दकोश की आवश्यकता होगी।
मुझे ये मिले हैं जो आपके लिए उपयोगी हो सकते हैं:
- https://raw.githubusercontent.com/first20hours/google-10000-english/master/20k.txt
- https://raw.githubusercontent.com/dwyl/english-words/master/words_alpha.txt
उपसर्ग शब्द ढूँढना
इसलिए कोड उदाहरण में मैंने आपको add . को लागू करने से पहले दिखाया था &find संचालन।
लेकिन हम एक find_words_starting_with . भी चाहते हैं विधि।
हम इसे "डेप्थ फर्स्ट सर्च" (डीएफएस) एल्गोरिथम का उपयोग करके कर सकते हैं। जिस शब्द को हम देख रहे हैं उस पर नज़र रखने के लिए हमें एक तरीके की भी आवश्यकता है।
याद रखें कि हमारे नोड्स में केवल एक ही वर्ण होता है, इसलिए हमें पेड़ पर चलकर वास्तविक स्ट्रिंग्स को फिर से बनाना होगा।
यहां एक तरीका दिया गया है जो यह सब करता है :
def find_words_starting_with(prefix)
stack = []
words = []
prefix_stack = []
stack << find_word(prefix)
prefix_stack << prefix.chars.take(prefix.size-1)
return [] unless stack.first
until stack.empty?
node = stack.pop
prefix_stack.pop and next if node == :guard_node
prefix_stack << node.value
stack << :guard_node
words << prefix_stack.join if node.word
node.next.each { |n| stack << n }
end
words
end
हम यहां दो स्टैक का उपयोग करते हैं, एक बिना विज़िट किए गए नोड्स का ट्रैक रखने के लिए (stack ) और दूसरा वर्तमान स्ट्रिंग का ट्रैक रखने के लिए (prefix_stack )।
हम तब तक लूप करते हैं जब तक हम सभी नोड्स का दौरा नहीं कर लेते हैं और नोड का मान prefix_stack में जोड़ देते हैं . प्रत्येक नोड में केवल एक वर्ण का मान होता है, इसलिए हमें एक शब्द बनाने के लिए इन वर्णों को एकत्रित करने की आवश्यकता होती है।
:guard_node प्रतीक को prefix_stack में जोड़ा जाता है इसलिए हम जानते हैं कि हम कब पीछे हट रहे हैं। हमें अपने स्ट्रिंग बफर (prefix_stack . से वर्णों को हटाने के लिए इसकी आवश्यकता है ) सही समय पर।
फिर अगर node.word सच है इसका मतलब है कि हमें एक पूरा शब्द मिल गया है और हम इसे अपने शब्दों की सूची में जोड़ देते हैं।
इस पद्धति का उपयोग करने का उदाहरण :
t.find_words_starting_with("cap")
# ["cap", "cape"]
यदि कोई शब्द नहीं मिलता है तो आपको एक खाली सरणी मिलेगी:
t.find_words_starting_with("b")
# []
इस पद्धति का उपयोग स्वत:पूर्ण सुविधा को लागू करने के लिए किया जा सकता है।
सारांश
आपने प्रीफ़िक्स ट्री (जिसे ट्रीज़ भी कहा जाता है) के बारे में सीखा, एक डेटा संरचना जिसका उपयोग शब्दों की सूची को ट्री में व्यवस्थित करने के लिए किया जाता है। कोई शब्द मान्य है या नहीं, यह जांचने के लिए और समान उपसर्ग साझा करने वाले शब्दों को खोजने के लिए आप इस ट्री से शीघ्रता से पूछताछ कर सकते हैं।
इस पोस्ट को शेयर करना न भूलें ताकि और लोग सीख सकें!