कई विकल्प जो हम बनाते हैं वे संख्यात्मक संबंधों के इर्द-गिर्द घूमते हैं।
- हम कुछ खाद्य पदार्थ खाते हैं क्योंकि विज्ञान कहता है कि वे हमारे कोलेस्ट्रॉल को कम करते हैं
- हम अपनी शिक्षा को आगे बढ़ाते हैं क्योंकि हमारे वेतन में वृद्धि होने की संभावना है
- हम पड़ोस में एक घर खरीदते हैं जो हमें लगता है कि मूल्य में सबसे अधिक सराहना करने वाला है
हम इन निष्कर्षों पर कैसे आते हैं? सबसे अधिक संभावना है, किसी ने बड़ी मात्रा में डेटा एकत्र किया और निष्कर्ष निकालने के लिए इसका इस्तेमाल किया। एक सामान्य तकनीक रेखीय प्रतिगमन है, जो पर्यवेक्षित शिक्षण का एक रूप है। पर्यवेक्षित शिक्षण के बारे में अधिक जानकारी के लिए और इसके उदाहरणों के लिए कि इसका अक्सर क्या उपयोग किया जाता है, इस श्रृंखला का भाग 1 देखें।
रैखिक संबंध
जब दो मान — उन्हें x . कहें और y — एक रैखिक संबंध है, इसका मतलब है कि x changing बदलना 1 से हमेशा y . का कारण होगा एक निश्चित राशि से बदलने के लिए। उदाहरण देना आसान है:
- 10 पिज्जा की कीमत एक पिज्जा की कीमत से 10 गुना अधिक है।
- 10 फुट ऊंची दीवार को 5 फुट की दीवार की तुलना में दुगने रंग की जरूरत होती है
गणितीय रूप से, इस प्रकार के संबंध को एक रेखा के समीकरण का उपयोग करके वर्णित किया जाता है:
y = mx + b
गणित भयानक रूप से भ्रमित करने वाला हो सकता है, लेकिन कई बार यह मुझे जादू जैसा लगता है। जब मैंने पहली बार एक रेखा के समीकरण को सीखा, तो मुझे याद आया कि केवल एक सूत्र के साथ दूरी, ढलान और अन्य बिंदुओं की गणना करने में सक्षम होना कितना सुंदर था।
लेकिन आप यह सूत्र कैसे प्राप्त करते हैं, यदि आपके पास सभी डेटा बिंदु हैं? इसका उत्तर रैखिक प्रतिगमन है - एक बहुत ही लोकप्रिय मशीन लर्निंग टूल।
रैखिक प्रतिगमन का एक उदाहरण
इस पोस्ट में, हम यह पता लगाने जा रहे हैं कि क्या किसी गाने में बीट्स प्रति मिनट (बीपीएम) Spotify पर इसकी लोकप्रियता की भविष्यवाणी करता है।
रैखिक प्रतिगमन मॉडल दो चर के बीच संबंध को दर्शाता है। एक को "व्याख्यात्मक चर" कहा जाता है और दूसरे को "आश्रित चर" कहा जाता है।
हमारे उदाहरण में, हम देखना चाहते हैं कि क्या बीपीएम लोकप्रियता की "व्याख्या" कर सकता है। तो बीपीएम हमारा व्याख्यात्मक चर होगा। यह लोकप्रियता को आश्रित चर बनाता है।
जैसा कि आपने अनुमान लगाया है, मॉडल फॉर्म की सबसे अच्छी फिटिंग लाइन खोजने के लिए कम से कम वर्ग प्रतिगमन का उपयोग करेगा, y = mx + b ।
जबकि कई व्याख्यात्मक चर हो सकते हैं, इस उदाहरण के लिए हम सरल रैखिक प्रतिगमन का संचालन करेंगे जहां सिर्फ एक है।
Least-squares क्या?
रैखिक प्रतिगमन करने के कई तरीके हैं। उनमें से एक को "न्यूनतम-वर्ग" कहा जाता है। यह प्रत्येक डेटा बिंदु से रेखा तक लंबवत विचलन के वर्गों के योग को कम करके सर्वोत्तम फिटिंग लाइन की गणना करता है।
मुझे पता है कि यह भ्रमित करने वाला लगता है, लेकिन यह मूल रूप से सिर्फ इतना कह रहा है, "मुझे एक ऐसी लाइन बनाएं जो उक्त रेखा और डेटा बिंदुओं के बीच की जगह को कम से कम करे।"
वर्ग और योग का कारण यह है कि सकारात्मक और नकारात्मक मानों के बीच कोई रद्दीकरण नहीं है।
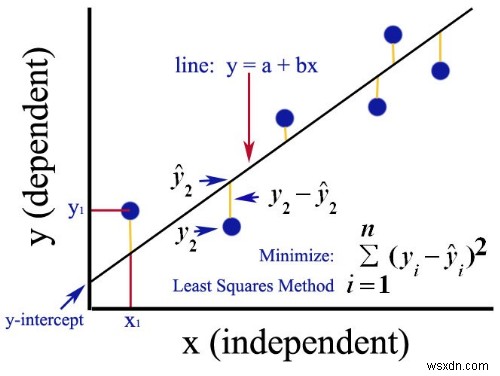
यहाँ एक छवि है जो मुझे Quora पर मिली है जो इसे समझाने का बहुत अच्छा काम करती है।
डेटासेट
हम कागल से इस डेटासेट का उपयोग करेंगे:https://www.kaggle.com/leonardopena/top50spotify2019 आप इसे CSV के रूप में डाउनलोड कर सकते हैं।
डेटासेट में 16 कॉलम हैं; हालांकि, हम केवल तीन की परवाह करते हैं - "ट्रैक नाम," "बीट्स प्रति मिनट," और "लोकप्रियता।" मशीन लर्निंग के सबसे महत्वपूर्ण चरणों में से एक आपके डेटा को ठीक से स्वरूपित करना है, जिसे अक्सर "मुंगिंग" कहा जाता है। आप उपरोक्त तीन स्तंभों को छोड़कर सभी डेटा हटा सकते हैं।
आपका सीएसवी इस तरह दिखना चाहिए: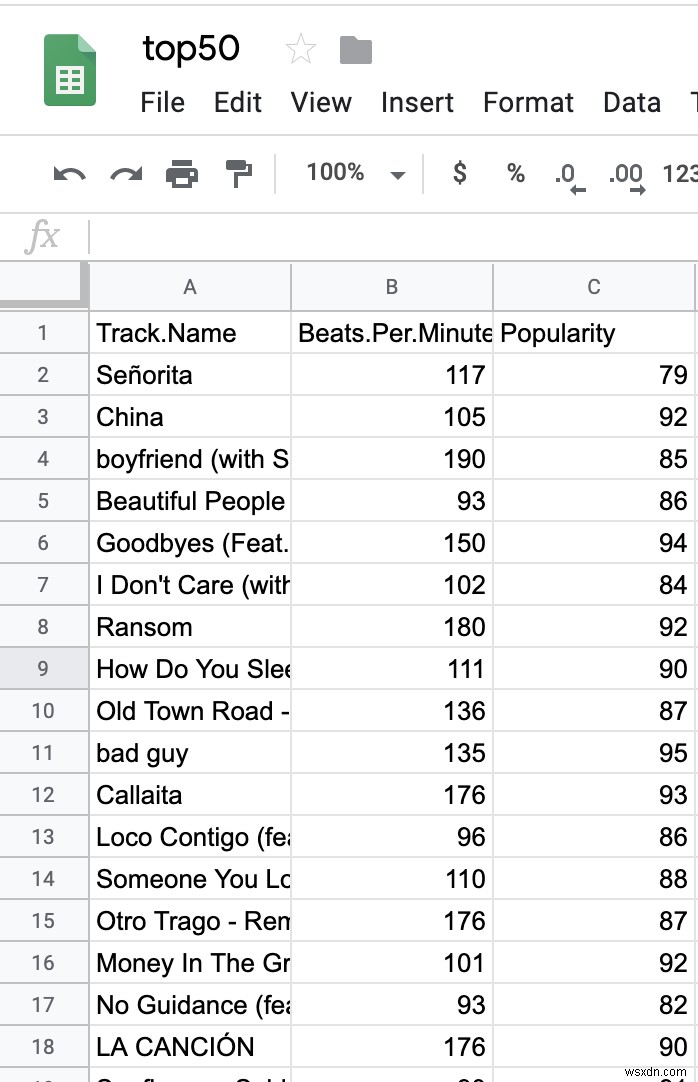
रूबी का उपयोग करके प्रतिगमन करना
इस उदाहरण में, हम ruby_linear_regression . का उपयोग करेंगे रत्न स्थापित करने के लिए, चलाएँ:
gem install ruby_linear_regression
ठीक है, हम कोडिंग शुरू करने के लिए तैयार हैं! एक नई रूबी फ़ाइल बनाएँ और इन्हें जोड़ें की आवश्यकता है:
require "ruby_linear_regression"
require "csv"
इसके बाद, हम अपना CSV डेटा पढ़ते हैं और #shift . पर कॉल करते हैं , शीर्ष लेख पंक्ति को त्यागने के लिए। वैकल्पिक रूप से, आप CSV फ़ाइल से केवल पहली पंक्ति को हटा सकते हैं।
csv = CSV.read("top50.csv")
csv.shift
आइए अपने एक्स-डेटा पॉइंट्स और वाई-डेटा पॉइंट्स को होल्ड करने के लिए दो खाली एरेज़ बनाएं।
x_data = []
y_data = []
...और हम .each . का उपयोग करके पुनरावृति करते हैं Beats Per Minute जोड़ने की विधि हमारे x सरणी और Popularity . के लिए डेटा हमारे y सरणी के लिए डेटा।
यदि आप यह देखने के लिए उत्सुक हैं कि वास्तव में यहाँ क्या हो रहा है, तो आप अपनी row . को लॉग करके प्रयोग कर सकते हैं या तो एक puts . के साथ या p . उदाहरण के लिए:puts row
csv.each do |row|
x_data.push( [row[1].to_i] )
y_data.push( row[2].to_i )
end
अब ruby_linear_regression . का उपयोग करने का समय आ गया है रत्न हम अपने प्रतिगमन मॉडल का एक नया उदाहरण बनाएंगे, अपना डेटा लोड करेंगे, और अपने मॉडल को प्रशिक्षित करेंगे:
linear_regression = RubyLinearRegression.new
linear_regression.load_training_data(x_data, y_data)
linear_regression.train_normal_equation
इसके बाद, हम माध्य वर्ग त्रुटि (MSE) - प्रेक्षित मानों और अनुमानित मानों के बीच अंतर का एक माप प्रिंट करेंगे। अंतर को चुकता किया जाता है ताकि नकारात्मक और सकारात्मक मान एक दूसरे को रद्द न करें। हम एमएसई को कम से कम करना चाहते हैं क्योंकि हम नहीं चाहते कि हमारे अनुमानित और वास्तविक मूल्यों के बीच की दूरी बड़ी हो।
puts "Trained model with the following cost fit #{linear_regression.compute_cost}"
अंत में, आइए भविष्यवाणी करने के लिए कंप्यूटर हमारे मॉडल का उपयोग करें। विशेष रूप से, 250 बीपीएम वाला गाना कितना लोकप्रिय होगा? prediction_data . में अलग-अलग मानों के साथ बेझिझक खेलें सरणी।
prediction_data = [250]
predicted_popularity = linear_regression.predict(prediction_data)
puts "Predicted popularity: #{predicted_popularity.round}"
परिणाम
आइए प्रोग्राम को अपने कंसोल में चलाएं और देखें कि हमें क्या मिलता है!
➜ ~ ruby spotify_regression.rb
Trained model with the following cost fit 9.504882197447587
Predicted popularity: 91
ठंडा! आइए "250" को "50" में बदलें और देखें कि हमारा मॉडल क्या भविष्यवाणी करता है।
➜ ~ ruby spotify_regression.rb
Trained model with the following cost fit 9.504882197447587
Predicted popularity: 86
ऐसा प्रतीत होता है कि प्रति मिनट अधिक बीट्स वाले गाने अधिक लोकप्रिय हैं।
संपूर्ण कार्यक्रम
यहाँ मेरी पूरी फ़ाइल कैसी दिखती है:
require 'csv'
require 'ruby_linear_regression'
x_data = []
y_data = []
csv = CSV.read("top50.csv")
csv.shift
# Load data from CSV file into two arrays -- one for independent variables X (x_data) and one for the dependent variable y (y_data)
# Row[0] = title
# Row[1] = BPM
# Row[2] = Popularity
csv.each do |row|
x_data.push( [row[1].to_i] )
y_data.push( row[2].to_i )
end
# Create regression model
linear_regression = RubyLinearRegression.new
# Load training data
linear_regression.load_training_data(x_data, y_data)
# Train the model using the normal equation
linear_regression.train_normal_equation
# Output the cost
puts "Trained model with the following cost fit #{linear_regression.compute_cost}"
# Predict the popularity of a song with 250 BPM
prediction_data = [250]
predicted_popularity = linear_regression.predict(prediction_data)
puts "Predicted popularity: #{predicted_popularity.round}"
अगले चरण
यह एक बहुत ही सरल उदाहरण है, लेकिन फिर भी, आपने अपना पहला रैखिक प्रतिगमन चलाया है, जो मशीन सीखने के लिए उपयोग की जाने वाली एक महत्वपूर्ण तकनीक है। यदि आप और अधिक के लिए तरस रहे हैं, तो यहां कुछ अन्य चीजें हैं जो आप आगे कर सकते हैं:- रूबी रत्न के लिए स्रोत कोड देखें जिसका उपयोग हम हुड के नीचे हो रहे गणित को देखने के लिए कर रहे थे - मूल डेटा सेट पर वापस जाएं और कोशिश करें मॉडल में अतिरिक्त चर जोड़ना और यह देखने के लिए कि क्या यह हमारे एमएसई को कम कर सकता है, एक बहु-चर रैखिक प्रतिगमन चलाएँ। उदाहरण के लिए, शायद "वैलेंस" (गीत कितना सकारात्मक है) भी लोकप्रियता में एक भूमिका निभाता है। - ग्रेडिएंट डिसेंट मॉडल आज़माएं, जिसे ruby_linear_regression का इस्तेमाल करके भी चलाया जा सकता है रत्न