इस पोस्ट में, हम तंत्रिका नेटवर्क की मूल बातें सीखेंगे और रूबी का उपयोग करके हम उन्हें कैसे लागू कर सकते हैं! यदि आप आर्टिफिशियल इंटेलिजेंस और डीप लर्निंग में रुचि रखते हैं, लेकिन सुनिश्चित नहीं हैं कि शुरुआत कैसे करें, तो यह पोस्ट आपके लिए है! हम प्रमुख अवधारणाओं को उजागर करने के लिए एक सरल उदाहरण के माध्यम से चलेंगे। यह बहुत कम संभावना है कि आप कभी भी रूबी का उपयोग बहु-परत तंत्रिका नेटवर्क लिखने के लिए करेंगे, लेकिन सादगी और पठनीयता के लिए, यह समझने का एक शानदार तरीका है कि क्या हो रहा है। सबसे पहले, आइए एक कदम पीछे हटें और देखें कि हम यहां कैसे पहुंचे।
 मछनिया फिल्म का एक दृश्य। फ़ोटो क्रेडिट
मछनिया फिल्म का एक दृश्य। फ़ोटो क्रेडिट
Ex Machina 2014 में रिलीज़ हुई एक फिल्म थी। यदि आप Google पर शीर्षक देखते हैं, तो यह फिल्म की शैली को "ड्रामा / फंतासी" के रूप में वर्गीकृत करता है। और, जब मैंने पहली बार फिल्म देखी, तो यह विज्ञान कथा की तरह लग रही थी।
लेकिन, बहुत अधिक समय के लिए?
यदि आप रे कुर्ज़वील से पूछें, जो कि Google पर काम करने वाले एक जाने-माने भविष्यवादी हैं, तो 2029 वह वर्ष हो सकता है जब कृत्रिम बुद्धिमत्ता एक वैध ट्यूरिंग परीक्षण पास करेगी (जो यह देखने के लिए एक प्रयोग है कि क्या कोई मानव मशीन/कंप्यूटर और दूसरे मानव के बीच अंतर कर सकता है। ) उन्होंने यह भी भविष्यवाणी की है कि विलक्षणता (जब कंप्यूटर मानव बुद्धि से आगे निकल जाएंगे) 2045 तक उभरेंगे।
कुर्ज़वील को इतना आत्मविश्वासी क्यों बनाता है?
गहन शिक्षण का उद्भव
सीधे शब्दों में कहें, डीप लर्निंग मशीन लर्निंग का एक सबसेट है जो बड़ी मात्रा में डेटा से अंतर्दृष्टि निकालने के लिए तंत्रिका नेटवर्क का उपयोग करता है। डीप लर्निंग के वास्तविक-विश्व अनुप्रयोगों में निम्नलिखित शामिल हैं:- सेल्फ-ड्राइविंग कार- कैंसर का पता लगाना- वर्चुअल असिस्टेंट, जैसे सिरी और एलेक्सा - भूकंप जैसे चरम मौसम की घटनाओं की भविष्यवाणी करना
लेकिन, "तंत्रिका नेटवर्क" क्या है?
तंत्रिका नेटवर्क को उनका नाम न्यूरॉन्स से मिलता है, जो मस्तिष्क की कोशिकाएं हैं जो विद्युत और रासायनिक संकेतों के माध्यम से सूचना को संसाधित और प्रसारित करती हैं। मजेदार तथ्य:मानव मस्तिष्क 80+ बिलियन न्यूरॉन्स से बना है!
कंप्यूटिंग में, एक तंत्रिका नेटवर्क इस तरह दिखता है:
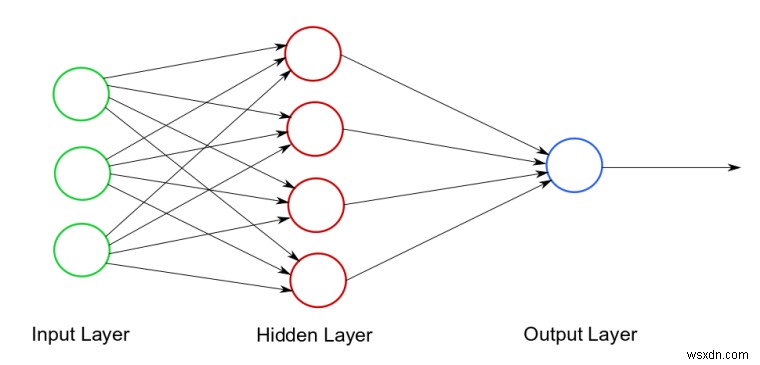 एक उदाहरण तंत्रिका नेटवर्क आरेख। फ़ोटो क्रेडिट
एक उदाहरण तंत्रिका नेटवर्क आरेख। फ़ोटो क्रेडिट
जैसा कि आप देख सकते हैं, तीन भाग हैं:1) इनपुट परत - प्रारंभिक डेटा 2) छिपी हुई परत (ओं) - एक तंत्रिका नेटवर्क में 1 (या अधिक) छिपी हुई परतें हो सकती हैं। यह वह जगह है जहाँ सभी गणना की जाती है! 3) आउटपुट लेयर -- अंतिम परिणाम/भविष्यवाणी
एक त्वरित इतिहास पाठ
तंत्रिका नेटवर्क नए नहीं हैं। वास्तव में, पहला प्रशिक्षित तंत्रिका नेटवर्क (परसेप्ट्रॉन) 1950 के दशक में कॉर्नेल विश्वविद्यालय में विकसित किया गया था। हालांकि, तंत्रिका नेटवर्क की प्रयोज्यता के आसपास बहुत निराशावाद था, मुख्यतः क्योंकि मूल मॉडल में केवल एक छिपी हुई परत होती थी। 1969 में प्रकाशित एक पुस्तक ने दिखाया कि काफी सरल गणनाओं के लिए परसेप्ट्रॉन का उपयोग करना अव्यावहारिक होगा।
तंत्रिका नेटवर्क के पुनरुत्थान को कंप्यूटर गेम के लिए जिम्मेदार ठहराया जा सकता है, जिसके लिए अब अत्यधिक उच्च शक्ति वाले ग्राफिक्स प्रोसेसिंग यूनिट (जीपीयू) की आवश्यकता होती है, जिसकी वास्तुकला एक तंत्रिका जाल के समान होती है। अंतर छिपी हुई परतों की संख्या है। एक के बजाय, आज प्रशिक्षित तंत्रिका नेटवर्क 10, 15, या 50+ परतों का उपयोग कर रहे हैं!
उदाहरण समय!
यह कैसे काम करता है यह समझने के लिए, आइए एक उदाहरण देखें। आपको ruby-fann . इंस्टॉल करना होगा रत्न अपना टर्मिनल खोलें और अपनी कार्यशील निर्देशिका में जाएँ। फिर, निम्नलिखित चलाएँ:
gem install ruby-fann
एक नई रूबी फ़ाइल बनाएँ (मैंने अपना नाम neural-net.rb रखा है )
इसके बाद, हम कागल के "छात्र शराब की खपत" डेटासेट का उपयोग करेंगे। आप द्वारा इसे यहां पर डाउनलोड किया जा सकता है। Google पत्रक (या अपनी पसंद के संपादक) में "student-mat.csv" फ़ाइल खोलें। इन्हें छोड़कर सभी कॉलम हटाएं:- Dalc (कार्यदिवस में शराब की खपत जहां 1 बहुत कम है और 5 बहुत अधिक है) - Walc (सप्ताहांत शराब की खपत जहां 1 बहुत कम है और 5 बहुत अधिक है) - G3 (0 और 20 के बीच अंतिम ग्रेड)
रूबी-फैन मणि काम करने के लिए हमें अपने अंतिम ग्रेड कॉलम को बाइनरी - या तो 0 या 1 - में बदलने की जरूरत है। इस उदाहरण के लिए, हम मानेंगे कि 10 से कम या उसके बराबर कुछ भी "0" है और 10 से बड़ा एक "1" है। आप किस प्रोग्राम का उपयोग कर रहे हैं, इस पर निर्भर करते हुए, आपको सेल के मान के आधार पर मान को स्वचालित रूप से 1 या 0 में बदलने के लिए सेल में एक सूत्र लिखने में सक्षम होना चाहिए। Google पत्रक में, यह कुछ इस तरह दिखता है:
=IF(C3 >= 10, 1, 0)
इस डेटा को एक .CSV फ़ाइल के रूप में सहेजें (मैंने अपना नाम students.csv . रखा है ) आपकी रूबी फ़ाइल के समान निर्देशिका में।
हमारे तंत्रिका नेटवर्क में निम्नलिखित परतें होंगी:- इनपुट परत:2 नोड्स (कार्यदिवस शराब की खपत और सप्ताहांत में शराब की खपत) - छिपी हुई परत:6 छिपी हुई नोड्स (यह शुरू करने के लिए कुछ हद तक मनमाना है; आप इसे बाद में परीक्षण के रूप में संशोधित कर सकते हैं) - आउटपुट परत:1 नोड (या तो 0 या 1)
सबसे पहले, हमें ruby-fann . की आवश्यकता होगी मणि, साथ ही अंतर्निर्मित csv पुस्तकालय। इसे अपने रूबी प्रोग्राम की पहली पंक्ति में जोड़ें:
require 'ruby-fann'
require 'csv'
इसके बाद, हमें अपने डेटा को अपनी CSV फ़ाइल से सरणियों में लोड करना होगा।
# Create two empty arrays. One will hold our independent varaibles (x_data), and the other will hold our dependent variable (y_data).
x_data = []
y_data = []
# Iterate through our CSV data and add elements to applicable arrays.
# Note that if we don't add the .to_f and .to_i, our arrays would have strings, and the ruby-fann library would not be happy.
CSV.foreach("students.csv", headers: false) do |row|
x_data.push([row[0].to_f, row[1].to_f])
y_data.push(row[2].to_i)
end
इसके बाद, हमें अपने डेटा को प्रशिक्षण और परीक्षण डेटा में विभाजित करने की आवश्यकता है। एक 80/20 विभाजन बहुत आम है, जहां आपके डेटा का 20% परीक्षण के लिए और 80% प्रशिक्षण के लिए उपयोग किया जाता है। यहां "प्रशिक्षण," का अर्थ है कि मॉडल इस डेटा के आधार पर सीखेगा, और फिर हम अपने "परीक्षण" डेटा का उपयोग यह देखने के लिए करेंगे कि मॉडल कितनी अच्छी तरह परिणामों की भविष्यवाणी करता है।
# Divide data into a training set and test set.
testing_percentage = 20.0
# Take the number of total elements and multiply by the test percentage.
testing_size = x_data.size * (testing_percentage/100.to_f)
# Start at the beginning and end at the testing_size - 1 since arrays are 0-indexed.
x_test_data = x_data[0 .. (testing_size-1)]
y_test_data = y_data[0 .. (testing_size-1)]
# Pick up where we left off until the end of the dataset.
x_train_data = x_data[testing_size .. x_data.size]
y_train_data = y_data[testing_size .. y_data.size]
ठंडा! हमारे पास जाने के लिए हमारा डेटा तैयार है। अगला जादू आता है!
# Set up the training data model.
train = RubyFann::TrainData.new(:inputs=> x_train_data, :desired_outputs=>y_train_data)
हम RubyFann::TrainData ऑब्जेक्ट का उपयोग करते हैं, और हमारे x_train_data, में पास करते हैं जो हमारा कार्यदिवस और सप्ताहांत में शराब का सेवन है, और हमारा y_train_data, जो अंतिम पाठ्यक्रम ग्रेड के आधार पर 0 या 1 है।
अब, हमारे वास्तविक तंत्रिका नेटवर्क मॉडल को छिपे हुए न्यूरॉन्स की संख्या के साथ सेट करें, जिसकी हमने पहले चर्चा की थी।
# Set up the model and train using training data.
model = RubyFann::Standard.new(
num_inputs: 2,
hidden_neurons: [6],
num_outputs: 1 );
ठीक है, प्रशिक्षण का समय!
model.train_on_data(train, 1000, 10, 0.01)
यहाँ, हम train . में गुजरते हैं वेरिएबल जो हमने पहले बनाया था। 1000 max_epochs की संख्या का प्रतिनिधित्व करता है, 10 रिपोर्ट के बीच त्रुटियों की संख्या का प्रतिनिधित्व करता है, और 0.1 हमारी वांछित माध्य-वर्ग त्रुटि है। एक युग तब होता है जब संपूर्ण डेटासेट तंत्रिका नेटवर्क से होकर गुजरता है। माध्य-वर्ग त्रुटि वह है जिसे हम कम करने का प्रयास कर रहे हैं। इसका क्या अर्थ है, इसके बारे में आप यहां अधिक पढ़ सकते हैं।
इसके बाद, हम यह जानना चाहते हैं कि हमारे परीक्षण डेटा के लिए वास्तविक परिणामों के साथ मॉडल की भविष्यवाणी की तुलना करके हमारे मॉडल ने कितना अच्छा प्रदर्शन किया। हम इस कोड का उपयोग करके इसे पूरा कर सकते हैं:
predicted = []
# Iterate over our x_test_data, run our model on each one, and add it to our predicted array.
x_test_data.each do |params|
predicted.push( model.run(params).map{ |e| e.round } )
end
# Compare the predicted results with the actual results.
correct = predicted.collect.with_index { |e,i| (e == y_test_data[i]) ? 1 : 0 }.inject{ |sum,e| sum+e }
# Print out the accuracy rate.
puts "Accuracy: #{((correct.to_f / testing_size) * 100).round(2)}% - test set of size #{testing_percentage}%"
आइए अपना कार्यक्रम चलाएं और देखें कि क्या होता है!
ruby neural-net.rb
आपको युगों के लिए बहुत सारे आउटपुट देखने चाहिए, लेकिन सबसे नीचे, आपको कुछ इस तरह देखना चाहिए:
Accuracy: 56.82% - test set of size 20.0%
उफ़, यह बहुत अच्छा नहीं है! लेकिन, आइए अपने स्वयं के डेटा बिंदुओं के साथ आते हैं और मॉडल चलाते हैं।
prediction = model.run( [1, 1] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction.map{ |e| e.round }}"
prediction_two = model.run( [5, 4] )
# Round the output to get the prediction.
puts "Algorithm predicted class: #{prediction_two.map{ |e| e.round }}"
यहां, हमारे पास दो उदाहरण हैं। पहले के लिए, हम अपने कार्यदिवस और सप्ताहांत शराब की खपत के लिए 1s में गुजर रहे हैं। अगर मैं सट्टेबाजी करने वाला व्यक्ति होता, तो मुझे लगता कि इस छात्र का अंतिम ग्रेड 10 से ऊपर होगा (अर्थात, 1)। दूसरा उदाहरण शराब की खपत के लिए उच्च मूल्यों (5 और 4) में गुजरता है, इसलिए मुझे लगता है कि इस छात्र का अंतिम ग्रेड 10 के बराबर या उससे कम होगा (यानी, 0.) आइए अपना कार्यक्रम फिर से चलाएं और देखें कि क्या होता है!
आपका आउटपुट कुछ इस तरह दिखना चाहिए:
Algorithm predicted class: [1]
Algorithm predicted class: [0]
हमारा मॉडल वह करता प्रतीत होता है जो हम स्पेक्ट्रम के निचले या उच्च छोर पर संख्याओं के लिए अपेक्षा करते हैं। लेकिन, यह तब संघर्ष करता है जब संख्याएं विपरीत होती हैं (विभिन्न संयोजनों को आज़माने के लिए स्वतंत्र महसूस करें - 1 और 5, या 2 और 3 उदाहरण के रूप में) या बीच में। हम अपने एपोच डेटा से यह भी देख सकते हैं कि, जबकि त्रुटि कम होती है, यह बहुत अधिक (मध्य -20%) बनी रहती है। इसका मतलब यह है कि शराब की खपत और पाठ्यक्रम ग्रेड के बीच कोई संबंध नहीं हो सकता है। मैं आपको कागल के मूल डेटासेट के साथ खेलने के लिए प्रोत्साहित करता हूं - क्या अन्य स्वतंत्र चर हैं जिनका उपयोग हम पाठ्यक्रम के परिणामों की भविष्यवाणी करने के लिए कर सकते हैं?
रैप-अप
बहुत सारी पेचीदगियां हैं (ज्यादातर गणित के संबंध में) जो यह सब काम करने के लिए हुड के नीचे होती हैं। यदि आप उत्सुक हैं और अधिक जानना चाहते हैं, तो मैं अत्यधिक अनुशंसा करता हूं कि आप FANN पर दस्तावेज़ देखें या ruby-fann के लिए स्रोत कोड देखें। रत्न मैं नेटफ्लिक्स पर "अल्फागो" डॉक्यूमेंट्री की जांच करने की भी सलाह देता हूं - इसका आनंद लेने के लिए बहुत अधिक तकनीकी ज्ञान की आवश्यकता नहीं होती है और यह एक महान, वास्तविक जीवन का उदाहरण देता है कि कंप्यूटर क्या हासिल कर सकता है, इसकी सीमा को कितनी गहरी शिक्षा दे रही है।
क्या कुर्ज़वील अपनी भविष्यवाणी के साथ सही होंगे? केवल समय ही बताएगा!


