मेरे अभी तक बच्चे नहीं हैं, लेकिन जब मैं करता हूं, तो मैं चाहता हूं कि वे दो चीजें सीखें:
- व्यक्तिगत वित्त
- मशीन लर्निंग
आप मानते हैं कि विलक्षणता निकट है या नहीं, इस बात से कोई इंकार नहीं है कि दुनिया डेटा पर चलती है। यह समझना कि डेटा को ज्ञान में कैसे बदला जाता है, इन दिनों उम्र के किसी भी व्यक्ति के लिए महत्वपूर्ण है - और इससे भी ज्यादा डेवलपर्स के लिए।
यह श्रृंखला का पहला लेख है जो मशीन लर्निंग (एमएल) को पूर्ण-स्टैक रूबी डेवलपर्स के लिए सुलभ बनाने का प्रयास करेगा। अपने निपटान में एमएल टूल्स को समझकर, आप अपने हितधारकों को बेहतर निर्णय लेने में मदद करने में सक्षम होंगे। भविष्य के लेख व्यक्तिगत तकनीकों और व्यावहारिक उदाहरणों पर ध्यान केंद्रित करेंगे, लेकिन इसमें, हम चरण निर्धारित कर रहे हैं - आपको एक नक्शा दिखा रहे हैं और एक पिन डाल रहे हैं जो कहता है कि "आप यहां हैं।"
विनम्र शुरुआत

आर्टिफिशियल इंटेलिजेंस (एआई) और मशीन लर्निंग कोई नई बात नहीं है। 1950 के दशक में वापस, आर्थर सैमुअल ने एक कंप्यूटर प्रोग्राम बनाया जो चेकर्स खेल सकता था। उन्होंने "अल्फा-बीटा प्रूनिंग" का उपयोग किया - एक सामान्य खोज एल्गोरिथम।
1960 के दशक में बहु-स्तरित तंत्रिका नेटवर्क और निकटतम-पड़ोसी एल्गोरिथम का आगमन हुआ, जिसका उपयोग गोदामों में इष्टतम पथ खोजने के लिए किया जाता है।
तो अगर AI इतना पुराना है, तो AI स्टार्टअप इतने ट्रेंडी क्यों हैं? मेरी राय में, इसके दो कारण हैं:
- कम्प्यूटिंग पावर (मूर का नियम देखें)
- इंटरनेट में प्रतिदिन जोड़े जाने वाले डेटा की मात्रा
दैनिक आधार पर बनाए जा रहे डेटा की मात्रा से संबंधित दो आँकड़े हैं जो हर बार जब मैं उनके बारे में सोचता हूँ तो मेरे होश उड़ जाते हैं:
- 2018 तक, हम हर दिन 2.5 क्विंटल बाइट डेटा का उत्पादन कर रहे हैं। इसमें कोई शक नहीं कि फोर्ब्स के इस लेख के प्रकाशित होने के बाद से ही यह संख्या बढ़ी है।
- केवल पिछले दो वर्षों में, दुनिया में 90% डेटा उत्पन्न किया गया था।
साथ में, इसका मतलब यह है कि (1) डेटा स्टोर करने और एल्गोरिदम चलाने के लिए आवश्यक हार्डवेयर अधिक किफायती होता जा रहा है और (2) एमएल मॉडल को प्रशिक्षित करने के लिए उपलब्ध डेटा की मात्रा पागल-तेज गति से बढ़ रही है।
हर दिन हम आर्टिफिशियल इंटेलिजेंस और मशीन लर्निंग की दुनिया के साथ बातचीत कर रहे हैं, प्रभावित हो रहे हैं और योगदान दे रहे हैं। उदाहरण के लिए, आप निम्नलिखित के लिए एल्गोरिदम को धन्यवाद (या दोष) दे सकते हैं:
- आपकी क्रेडिट लाइन
- बीमारी के निदान में सहायता करना
- शायद आपको नौकरी मिली या नहीं
- वर्तमान ट्रैफ़िक स्थितियों को देखते हुए आपको सबसे कुशल मार्ग खोजने में मदद करता है
- एलेक्सा समझती है कि आपका क्या मतलब है जब आप उसे बताते हैं कि आपको अभी-अभी छींक आई है
- Spotify आपका परिचय आपके नए पसंदीदा गीत से करा रहा है
मेरे काल्पनिक भविष्य के बच्चों का पालन-पोषण करने का कारण यह है:मैं चाहता हूं कि वे समझें कि उनका डिजिटल जीवन उनके "वास्तविक" जीवन को कैसे प्रभावित करता है, उनके डेटा गोपनीयता निर्णयों के निहितार्थ, और मशीन पर कब भरोसा करना चाहिए, इस बारे में अपनी राय कैसे बनाएं। बनाम जब उन्हें नहीं करना चाहिए।
इस पोस्ट के शेष भाग में, मैं उन तीन प्रकार के मशीन लर्निंग का अवलोकन देना चाहता हूं जिनका मैंने अध्ययन किया है:पर्यवेक्षित शिक्षण, अनुपयोगी शिक्षण और सुदृढीकरण सीखना। हम इस बारे में बात करेंगे कि प्रत्येक दृष्टिकोण को क्या विशिष्ट बनाता है और प्रत्येक समस्या को हल करने में विशेष रूप से अच्छा है।
पर्यवेक्षित शिक्षण
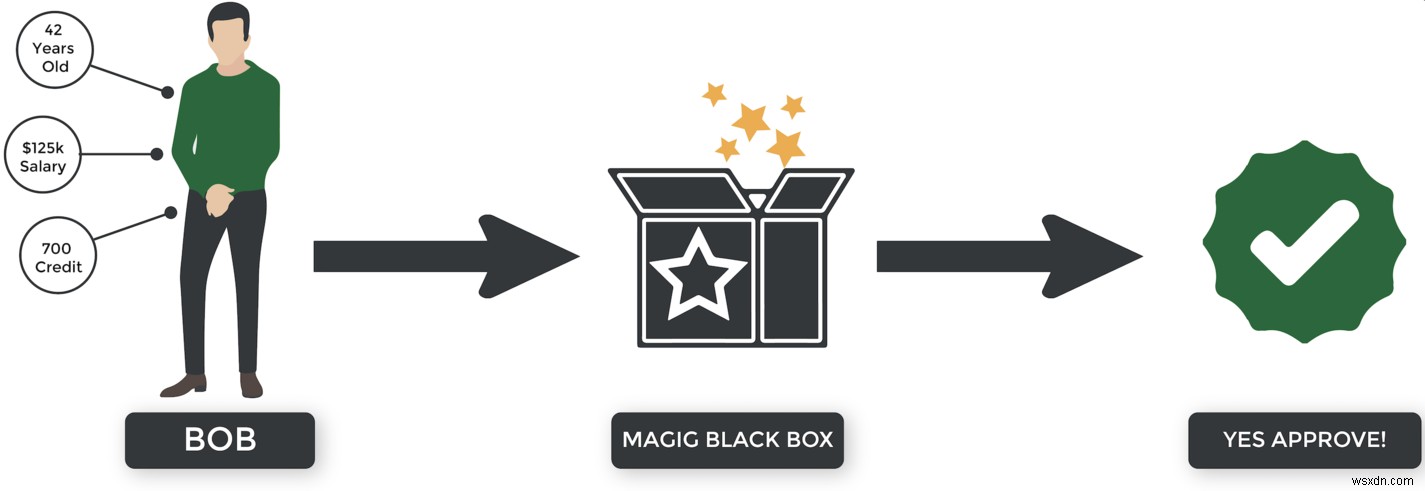
पर्यवेक्षित शिक्षण है ... ठीक है, मनुष्यों द्वारा पर्यवेक्षित। :) कल्पना कीजिए कि हम यह तय करने के लिए एक पर्यवेक्षित शिक्षण प्रणाली का निर्माण कर रहे हैं कि कौन बंधक के लिए स्वीकृत हो। यहां बताया गया है कि यह कैसे काम कर सकता है:
- बैंक एक डेटासेट संकलित करता है जो ग्राहक विशेषताओं (आयु, वेतन, आदि) को परिणामों (पुनर्भुगतान, डिफ़ॉल्ट, आदि) से मैप करता है।
- हम डेटा का उपयोग करके अपने सिस्टम को प्रशिक्षित करते हैं।
- सिस्टम आवेदक की विशेषताओं के आधार पर भविष्य के परिणामों का अनुमान लगाने के लिए जो सीखता है उसका उपयोग करता है।
- यदि एल्गोरिथम सही अनुमान लगाता है, तो हम उसे बताते हैं, "बहुत बढ़िया! आप सही कह रहे हैं।" लेकिन अगर यह गलत है, तो हम इसे कहते हैं, "नहीं, आप गलत हैं। कृपया सुधार करें और पुनः प्रयास करें।"
इस उदाहरण को "वर्गीकरण" समस्या माना जाता है क्योंकि एल्गोरिथम का आउटपुट एक श्रेणी है - इस मामले में, स्वीकृत या स्वीकृत नहीं है। वर्गीकरण समस्याओं के अन्य उदाहरणों में यह तय करना शामिल है कि क्या नहीं:
- एक व्यक्ति को कोई बीमारी है
- एक्स-रे में हड्डी टूट गई है
- एक ई-मेल स्पैम है
यदि आप एमएल वर्गीकरण एल्गोरिदम के पीछे के गणित के बारे में अधिक जानने के लिए उत्सुक हैं, तो Google इनमें से कोई भी:भोले बेयस क्लासिफायर, सपोर्ट वेक्टर मशीन, लॉजिस्टिक रिग्रेशन, न्यूरल नेटवर्क, रैंडम फ़ॉरेस्ट।
"हां/नहीं" परिणाम देने वाली वर्गीकरण समस्याओं के अलावा, पर्यवेक्षित शिक्षण का उपयोग प्रतिगमन समस्याओं को हल करने के लिए भी किया जा सकता है - यहां, हम निरंतर पैमाने पर एक भविष्यवाणी करते हैं, उदाहरण के लिए:
- किसी स्टॉक का भविष्य मूल्य
- न्यू इंग्लैंड पैट्रियट्स के सुपर बाउल जीतने की संभावना
- औसत वेतन जो एक कंपनी को एक उम्मीदवार को स्वीकार करने के लिए देने की आवश्यकता होती है
पर्यवेक्षित प्रतिगमन समस्याओं के लिए उपयोग किए जाने वाले एल्गोरिदम के उदाहरणों में रैखिक प्रतिगमन, गैर-रेखीय प्रतिगमन और बायेसियन रैखिक प्रतिगमन शामिल हैं।
अनसुपरवाइज्ड लर्निंग
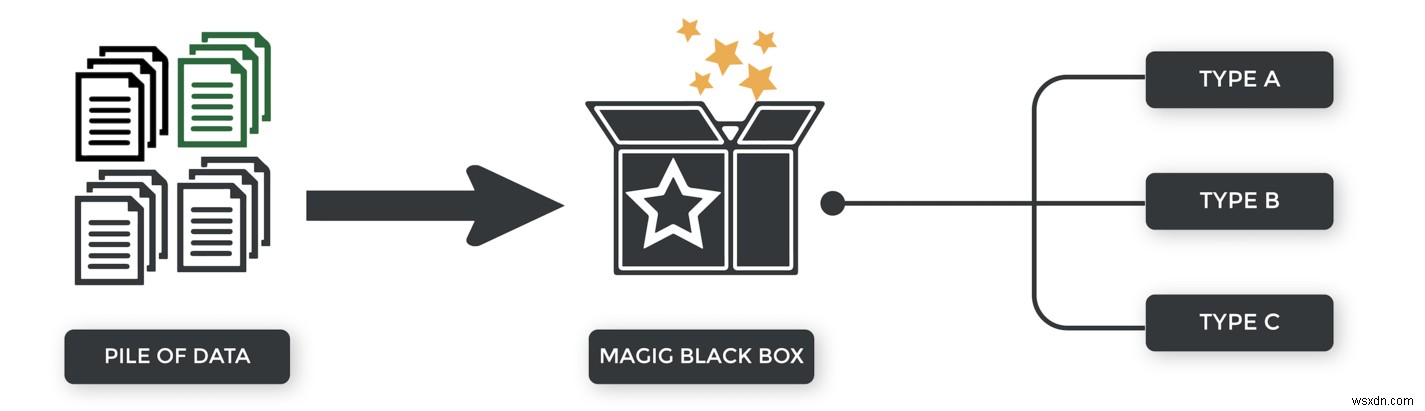
हमारे पर्यवेक्षित शिक्षण उदाहरण के साथ, हमने वर्गीकरण श्रेणियों को पूर्वनिर्धारित किया है। बंधक आवेदक को या तो स्वीकृत या अस्वीकार कर दिया गया था।
पर्यवेक्षित शिक्षण के साथ, हम श्रेणियां प्रदान नहीं करते हैं। वे हमारे लिए उपलब्ध नहीं हैं। एल्गोरिथ्म को अपने निष्कर्ष के साथ आना चाहिए।
हम एक अनुपयोगी दृष्टिकोण का उपयोग क्यों करना चाहेंगे?
1) कभी-कभी हम श्रेणियों को पहले से नहीं जानते हैं। इंटरनेट पर तैरता अधिकांश डेटा असंरचित है - यानी, लेबल की कमी है।
2) दूसरी बार, हम नहीं जानते कि हम क्या खोज रहे हैं, इसलिए हम एल्गोरिदम को पैटर्न/सुविधाओं को खोजने के लिए कह सकते हैं जो वर्गीकरण के लिए उपयोगी हो सकते हैं।
<ब्लॉकक्वॉट>मशीन लर्निंग के साथ असंरचित डेटा को संभालने का एक और तरीका यह है कि मनुष्य इसे देखें और इसे मैन्युअल रूप से लेबल करें। बहुत सी कंपनियां हैं जो डेटा को मैन्युअल रूप से वर्गीकृत करने के लिए श्रमिकों को काम पर रखती हैं:डेटा लेबल करना।
अनपर्यवेक्षित शिक्षण के दृष्टिकोण
बिना पर्यवेक्षित शिक्षण में आमतौर पर उपयोग की जाने वाली दो तकनीकें हैं एसोसिएशन और क्लस्टरिंग ।
एसोसिएशन: कल्पना कीजिए कि आप अमेज़न हैं। आपके पास बहुत सारे ग्राहक डेटा, खरीद इतिहास आदि हैं। बिना निगरानी के सीखने का उपयोग करके, आप ग्राहकों को "खरीदारों के प्रकार" में विभाजित कर सकते हैं - शायद यह पता लगाना कि जो लोग गुलाबी छतरियां खरीदते हैं, वे भी माचा चाय खरीदने की अधिक संभावना रखते हैं।
क्लस्टरिंग: क्लस्टरिंग आपके डेटा को देखता है और इसे निर्दिष्ट समूहों या समूहों में विभाजित करता है। उदाहरण के लिए, हो सकता है कि आपके पास आवास डेटा का एक समूह हो और आप यह देखना चाहते हों कि क्या कोई ऐसी विशेषताएं हैं (संभवतः अपराध डेटा?) जो यह अनुमान लगा सकती हैं कि घर किस पड़ोस में है। या, पाठ वर्गीकरण के लिए कोसाइन समानता जैसी तकनीकों का उपयोग किया जा सकता है ( उदाहरण के लिए, क्या यह लेख टेनिस, कुकिंग या स्पेस के बारे में है?)
यदि आप विशिष्ट अनुपयोगी शिक्षण तकनीकों के बारे में अधिक जानने में रुचि रखते हैं, तो Google खोज k- साधन क्लस्टरिंग, कोसाइन समानता, श्रेणीबद्ध क्लस्टरिंग, और k-निकटतम-पड़ोसी क्लस्टरिंग।
सुदृढीकरण सीखना

मशीन लर्निंग का यह सबसेट आमतौर पर खेलों में उपयोग किया जाता है क्योंकि यह लक्ष्य-उन्मुख एल्गोरिदम का उपयोग करता है। पर्यवेक्षित शिक्षण के विपरीत, प्रत्येक निर्णय स्वतंत्र नहीं होता है - वर्तमान इनपुट को देखते हुए, एल्गोरिथम एक निर्णय लेता है और अगला इनपुट इस निर्णय पर निर्भर करता है .
जैसे मैं अपने कुत्ते को सिर पर थपथपाता हूं जब वह दरवाजे की घंटी बजने पर लगातार भौंकना बंद कर देता है या जब वह चुप नहीं होता है तो उसे अपने केनेल में डाल देता है, लक्ष्य-अनुकूलन निर्णय लेने पर सुदृढीकरण एल्गोरिदम को पुरस्कृत किया जाता है (उदाहरण के लिए, स्कोरिंग स्कोरिंग अंकों की अधिकतम संख्या) और खराब होने पर दंडित किया जाता है।
सुदृढीकरण सीखने के एल्गोरिदम के लिए स्पष्ट अनुप्रयोगों में शामिल हैं:
- शतरंज और गो जैसे खेल (यदि आपने इसे पहले से नहीं देखा है, तो मैं नेटफ्लिक्स पर अल्फागो वृत्तचित्र की अत्यधिक अनुशंसा करता हूं।)
- रोबोटिक्स (वांछित कार्यों को पूरा करने के लिए बॉट सिखाना)
- स्वायत्त वाहन
- रोबो-सलाहकार जो शेयर बाजार को मात देने के लिए प्रशिक्षित हैं
यदि आप सुदृढीकरण सीखने के पीछे एल्गोरिदम के बारे में अधिक जानने में रुचि रखते हैं, तो Google खोज क्यू-लर्निंग, स्टेट-एक्शन-रिवार्ड-स्टेट-एक्शन (एसएआरएसए), डीक्यूएन, और एसिंक्रोनस एडवांटेज एक्टर क्रिटिक।
निष्कर्ष
मुझे उम्मीद है कि इन उदाहरणों से आपको मशीन सीखने की तकनीकों पर एक समझ हासिल करने में मदद मिली है और आज हम जिस पागल दुनिया में रहते हैं उसे प्रभावित करने के लिए प्रत्येक का उपयोग कैसे किया जाता है। जबकि मैं कभी-कभी खुद को उस सब से अभिभूत पाता हूं जो सीखने के लिए है, कहीं से शुरू करना कुछ न करने से बेहतर है, और याद रखें कि इसमें से बहुत कुछ वास्तव में बिल्कुल नया नहीं है - हम इसके बारे में अधिक सुन रहे हैं क्योंकि डेटा अधिक उपलब्ध हो जाता है और प्रसंस्करण होता है बिजली सस्ती।