एक कनवल्शनल न्यूरल नेटवर्क में आम तौर पर निम्नलिखित परतों का संयोजन होता है:कन्वेन्शनल लेयर्स, पूलिंग लेयर्स और डेंस लेयर्स।
और पढ़ें: TensorFlow क्या है और Keras कैसे तंत्रिका नेटवर्क बनाने के लिए TensorFlow के साथ काम करता है?
विशिष्ट प्रकार की समस्याओं, जैसे कि छवि पहचान के लिए अच्छे परिणाम देने के लिए दृढ़ तंत्रिका नेटवर्क का उपयोग किया गया है। इसे 'मॉडल' वर्ग में मौजूद 'अनुक्रमिक' पद्धति का उपयोग करके बनाया जा सकता है। 'ऐड' पद्धति का उपयोग करके इस दृढ़ नेटवर्क में परतें जोड़ी जा सकती हैं।
हम केरस अनुक्रमिक एपीआई का उपयोग करेंगे, जो एक अनुक्रमिक मॉडल बनाने में सहायक है जिसका उपयोग परतों के एक सादे ढेर के साथ काम करने के लिए किया जाता है, जहां हर परत में एक इनपुट टेंसर और एक आउटपुट टेंसर होता है।
हम नीचे दिए गए कोड को चलाने के लिए Google सहयोग का उपयोग कर रहे हैं। Google Colab या Colaboratory ब्राउज़र पर पायथन कोड चलाने में मदद करता है और इसके लिए शून्य कॉन्फ़िगरेशन और GPU (ग्राफ़िकल प्रोसेसिंग यूनिट) तक मुफ्त पहुंच की आवश्यकता होती है। जुपिटर नोटबुक के ऊपर कोलैबोरेटरी बनाई गई है।
print("Creating the convolutional base")
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
print("Description of arhcitecture is")
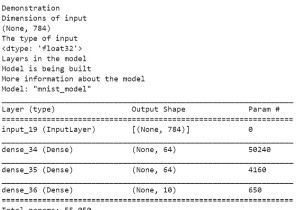
model.summary() कोड क्रेडिट:https://www.tensorflow.org/tutorials/images/cnn
आउटपुट
Creating the convolutional base Description of arhcitecture is Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 30, 30, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 15, 15, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 13, 13, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 4, 4, 64) 36928 ================================================================= Total params: 56,320 Trainable params: 56,320 Non-trainable params: 0
स्पष्टीकरण
-
उपरोक्त पंक्तियाँ एक सामान्य पैटर्न का उपयोग करके दृढ़ आधार को परिभाषित करने में मदद करती हैं।
-
यह पैटर्न Conv2D और MaxPooling2D परतों का एक स्टैक है।
-
इनपुट के रूप में, जो एक सीएनएन है, आकार के दसियों (image_height, image_width, color_channels) लेता है।
-
CNN को आकार (32, 32, 3) के इनपुट को संसाधित करने के लिए कॉन्फ़िगर किया गया है, जो कि CIFAR छवियों का प्रारूप है।
-
यह हमारी पहली परत के लिए input_shape तर्क पारित करके किया जा सकता है।
-
प्रत्येक Conv2D और MaxPooling2D परत का आउटपुट आकार (ऊंचाई, चौड़ाई, चैनल) का एक 3D टेंसर होता है।
-
जैसे-जैसे नेटवर्क गहरा होता जाता है, चौड़ाई और ऊंचाई के आयाम सिकुड़ते जाते हैं।
-
प्रत्येक Conv2D परत के लिए आउटपुट चैनलों की संख्या पहले तर्क (जैसे, 32 या 64) द्वारा नियंत्रित होती है।