समस्या का विवरण - ग्लू जॉब चलाने के लिए पायथन में boto3 लाइब्रेरी का उपयोग करें। उदाहरण के लिए, कार्य run_s3_file_job चलाएँ।
इस समस्या को हल करने के लिए दृष्टिकोण/एल्गोरिदम
चरण 1 - अपवादों को संभालने के लिए boto3 और botocore अपवाद आयात करें।
चरण 2 -job_name अनिवार्य पैरामीटर है जबकि तर्क फ़ंक्शन में वैकल्पिक पैरामीटर है। कुछ नौकरियां चलाने के लिए तर्क लेती हैं। उस स्थिति में, तर्कों को तानाशाही के रूप में पारित किया जा सकता है।
उदाहरण के लिए:तर्क ={'arguments1' ='value1', 'arguments2' ='value2'}
अगर नौकरी तर्क नहीं लेती है, तो बस job_name पास करें।
चरण 3 - boto3 लाइब्रेरी का उपयोग करके AWS सत्र बनाएं। सुनिश्चित करें कि डिफ़ॉल्ट प्रोफ़ाइल में क्षेत्र_नाम का उल्लेख किया गया है। यदि इसका उल्लेख नहीं है, तो सत्र बनाते समय स्पष्ट रूप से क्षेत्र_नाम पास करें।
चरण 4 - गोंद के लिए AWS क्लाइंट बनाएं।
चरण 5 - अब start_job_run फ़ंक्शन का उपयोग करें और यदि आवश्यक हो तो JobName और तर्कों को पास करें।
चरण 6 - जॉब शुरू होने के बाद, यह जॉब के मेटाडेटा के साथ job_run_id प्रदान करता है।
चरण 7 - कार्य की जाँच करते समय कुछ गलत होने पर सामान्य अपवाद को संभालें।
उदाहरण
मौजूदा ग्लू जॉब चलाने के लिए निम्न कोड का उपयोग करें -
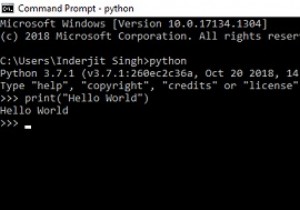
import boto3
from botocore.exceptions import ClientError
def run_glue_job(job_name, arguments = {}):
session = boto3.session.Session()
glue_client = session.client('glue')
try:
job_run_id = glue_client.start_job_run(JobName=job_name, Arguments=arguments)
return job_run_id
except ClientError as e:
raise Exception( "boto3 client error in run_glue_job: " + e.__str__())
except Exception as e:
raise Exception( "Unexpected error in run_glue_job: " + e.__str__())
print(run_glue_job("run_s3_file_job")) आउटपुट
{'JobRunId':
'jr_5f8136286322ce5b7d0387e28df6742abc6f5e6892751431692ffd717f45fc00',
'ResponseMetadata': {'RequestId': '36c48542-a060-468b-83ccb067a540bc3c', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Sat, 13
Feb 2021 13:36:50 GMT', 'content-type': 'application/x-amz-json-1.1',
'content-length': '82', 'connection': 'keep-alive', 'x-amzn-requestid':
'36c48542-a060-468b-83cc-b067a540bc3c'}, 'RetryAttempts': 0}}