<पी> एक्सेल बुनियादी मशीन सीखने के कार्यों के लिए आश्चर्यजनक रूप से शक्तिशाली उपकरण है। हालाँकि यह एक मशीन लर्निंग प्लेटफ़ॉर्म नहीं है, लेकिन इसका उपयोग अंतर्निहित फ़ंक्शंस और सॉल्वर का उपयोग करके रैखिक और लॉजिस्टिक रिग्रेशन जैसी मूलभूत एमएल अवधारणाओं को प्रदर्शित करने के लिए प्रभावी ढंग से किया जा सकता है। <पी> इस ट्यूटोरियल में, हम दिखाएंगे कि सॉल्वर और सूत्रों का उपयोग करके एक्सेल में हल्के मशीन लर्निंग मॉडल कैसे बनाएं।
- रैखिक प्रतिगमन: निरंतर मूल्यों (बिक्री राजस्व, घर की कीमतें, परीक्षण स्कोर, आदि) की भविष्यवाणी करें।
- लॉजिस्टिक रिग्रेशन: हां/नहीं परिणामों की भविष्यवाणी करें (ग्राहक की खरीदारी, ऋण चूक, चिकित्सा निदान, पास/असफल, आदि)।
- Microsoft Excel (2016 या उसके बाद अनुशंसित)।
- सॉल्वर ऐड-इन सक्षम करें।
- फ़ाइल पर जाएं टैब>> विकल्प चुनें>> ऐड-इन्स चुनें>> एक्सेल ऐड-इन्स चुनें .
- जाएं क्लिक करें .
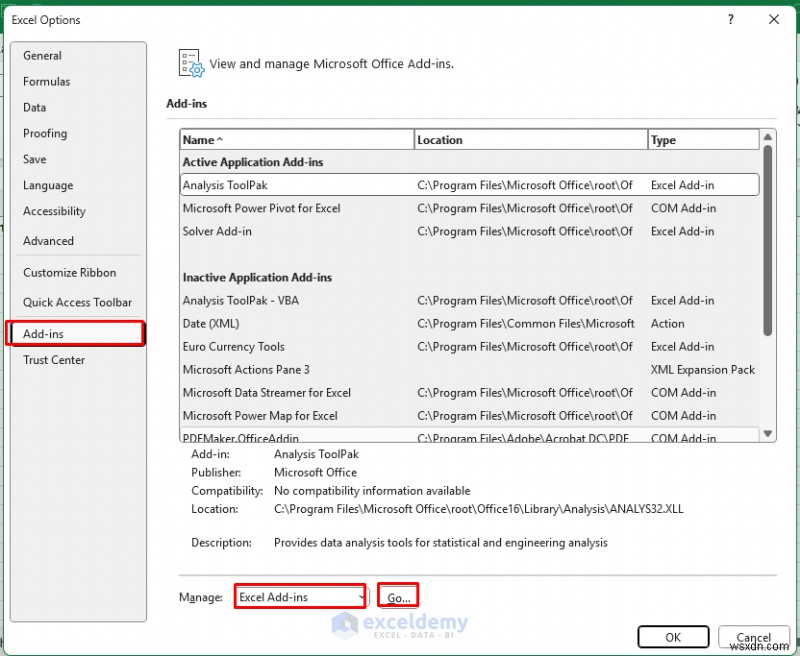
- सॉल्वर ऐड-इन चुनें .
- ठीक क्लिक करें .
- प्रतिगमन अवधारणाओं की बुनियादी समझ।
भाग 1:रैखिक प्रतिगमन मॉडल
<पी> रैखिक प्रतिगमन डेटा बिंदुओं के माध्यम से निरंतर संख्यात्मक मानों की भविष्यवाणी करने के लिए सबसे अच्छी सीधी रेखा ढूंढता है। हम एक सरल व्यावसायिक परिदृश्य का मॉडल तैयार करेंगे जहां विज्ञापन व्यय (X) बिक्री राजस्व (Y) की भविष्यवाणी करता है। प्रत्येक डेटा बिंदु एक महीने के व्यावसायिक डेटा का प्रतिनिधित्व करता है।चरण 1:नमूना डेटा सेट करना
<पी> एक यथार्थवादी डेटासेट बनाएं जो इनपुट (विज्ञापन खर्च हजारों में) और आउटपुट (बिक्री राजस्व हजारों में) के बीच एक स्पष्ट रैखिक संबंध दिखाता है। <पी>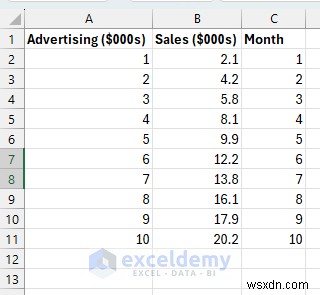 <पी> प्रत्येक पंक्ति एक महीने का व्यावसायिक डेटा है। जैसे-जैसे विज्ञापन खर्च बढ़ता है, बिक्री राजस्व भी बढ़ता है, लेकिन पूरी तरह से नहीं (कुछ यादृच्छिकता है, जो यथार्थवादी है)।
<पी> प्रत्येक पंक्ति एक महीने का व्यावसायिक डेटा है। जैसे-जैसे विज्ञापन खर्च बढ़ता है, बिक्री राजस्व भी बढ़ता है, लेकिन पूरी तरह से नहीं (कुछ यादृच्छिकता है, जो यथार्थवादी है)। चरण 2:पूर्वानुमान सूत्र बनाएं
<पी> गणितीय "घुंडी" सेट करें जिसे हमारा मॉडल सर्वोत्तम लाइन खोजने के लिए समायोजित करेगा। रैखिक प्रतिगमन में, हमें दो मापदंडों की आवश्यकता होती है:- अवरोधन (b0) :जहां रेखा Y-अक्ष को पार करती है ($0 विज्ञापन के साथ आधारभूत बिक्री)।
- ढलान (बी1) :विज्ञापन में प्रत्येक $1000 की वृद्धि पर बिक्री में कितनी वृद्धि होती है।
Predicted Y = b0 + b1 * X
- अवरोधन (b0)
- प्रारंभिक मान 0
- ढलान (बी1)
- प्रारंभिक मान 1
- यदि b0 =0.5 और b1 =2, तो विज्ञापन पर $3k खर्च करने का अनुमान है:बिक्री में 0.5 + 2*3 =$6.5k।
- मॉडल डेटा से b0 और b1 के लिए सर्वोत्तम मान सीखता है।
- एक सेल का चयन करें और निम्नलिखित सूत्र डालें।
- इस सूत्र को नीचे F11 तक खींचें।
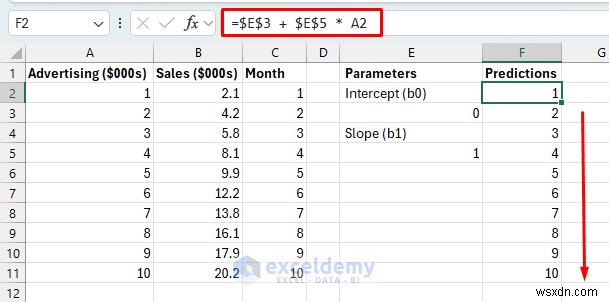
चरण 4:अवशेषों और त्रुटियों की गणना करें
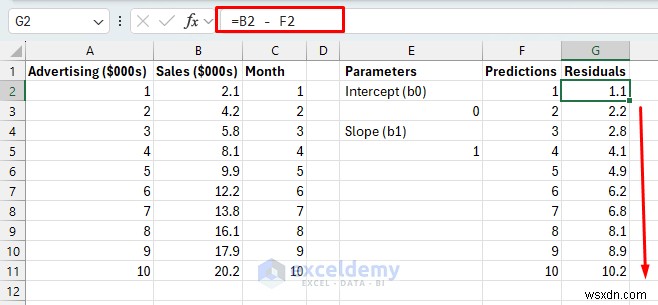
<पी> मापें कि हमारी भविष्यवाणियाँ कितनी गलत हैं। यह महत्वपूर्ण है क्योंकि मॉडल इन त्रुटियों को कम करने का प्रयास करके सीखता है।- अवशेष: प्रत्येक माह के लिए वास्तविक बिक्री और अनुमानित बिक्री के बीच का अंतर।
- वर्गीकृत त्रुटियाँ: अवशिष्टों का वर्ग किया गया (सभी त्रुटियों को सकारात्मक बनाने और बड़ी त्रुटियों को अधिक दंडित करने के लिए)।
- सूत्र को G11 तक नीचे खींचें।
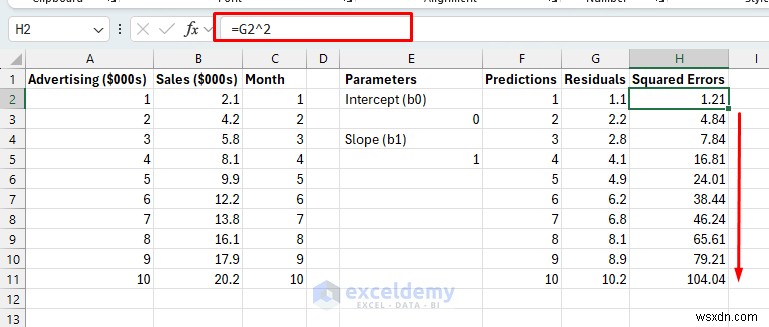
 <पी> वर्ग त्रुटियाँ:
<पी> वर्ग त्रुटियाँ: - सूत्र को H11 तक नीचे खींचें।
चरण 5:त्रुटि मेट्रिक्स की गणना करें
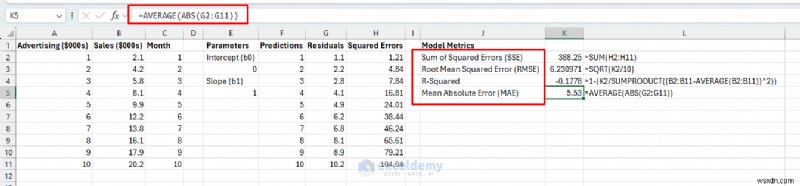
<पी> मॉडल प्रदर्शन का व्यवसाय-सार्थक माप बनाएं। ये मेट्रिक्स यह समझने में मदद करते हैं कि मॉडल वास्तविक दुनिया में उपयोग के लिए पर्याप्त है या नहीं। <पी> निर्दिष्ट क्षेत्र में मुख्य मेट्रिक्स सेट करें: <पी> त्रुटि मेट्रिक्स:- वर्गीकृत त्रुटियों का योग (SSE): सभी पूर्वानुमानों में कुल त्रुटि - कम बेहतर है।
- रूट माध्य वर्ग त्रुटि (RMSE): मूल इकाइयों में औसत त्रुटि ($000s) - व्याख्या करना आसान।
- आर-वर्ग: बिक्री भिन्नता का प्रतिशत विज्ञापन द्वारा समझाया गया (0-100%, उच्चतर बेहतर है)।
=1-(K2/SUMPRODUCT((B2:B11-AVERAGE(B2:B11))^2))
- मीन एब्सोल्यूट एरर (एमएई): औसत पूर्ण त्रुटि - आरएमएसई की तुलना में आउटलेर्स के प्रति कम संवेदनशील।
चरण 6:पैरामीटर्स को अनुकूलित करने के लिए सॉल्वर का उपयोग करें
<पी> एक्सेल को स्वचालित रूप से अवरोधन और ढलान के लिए सर्वोत्तम मान ढूंढने दें जो भविष्यवाणी त्रुटियों को कम करते हैं।- डेटा पर जाएं टैब>> सॉल्वर चुनें .
- उद्देश्य निर्धारित करें:K2 (एसएसई सेल).
- प्रति:मिन .
- वेरिएबल सेल्स को बदलकर:E3,E5 (आपके पैरामीटर).
- समाधान क्लिक करें .
- ठीक क्लिक करें .
- यह b0 और b1 के लाखों विभिन्न संयोजनों को आज़माता है।
- प्रत्येक संयोजन के लिए कुल त्रुटि की गणना करता है।
- जब तक यह सबसे कम त्रुटि वाला संयोजन नहीं ढूंढ लेता तब तक समायोजन करता रहता है।
- यह अनुमान लगाने से कहीं अधिक तेज़ और सटीक है।

चरण 7:विज़ुअलाइज़ेशन बनाएं
<पी> मॉडल का दृश्य सत्यापन समझ में आता है। आइए भविष्यवाणी रेखा को अधिकांश डेटा बिंदुओं के करीब से गुजरते हुए देखें।- विज्ञापन और बिक्री कॉलम चुनें।
- सम्मिलित करें पर जाएं टैब>> चार्ट से>>स्कैटर प्लॉट चुनें .
- चार्ट पर राइट-क्लिक करें>> डेटा चुनें>> श्रृंखला जोड़ें चुनें .
- श्रृंखला का नाम: सेल F1 चुनें.
- श्रृंखला X मान: X-मान चुनें (उदाहरण के लिए, B2:B11)
- श्रृंखला Y मान: क्लिक करें और अनुमानित मान F2:F11 चुनें।
- भविष्यवाणी श्रृंखला को एक पंक्ति के रूप में प्रारूपित करें।
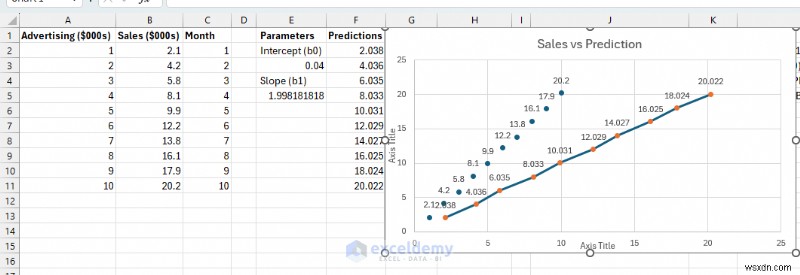
- भविष्यवाणी रेखा डेटा बिंदुओं की सामान्य प्रवृत्ति का अनुसरण करती है।
- बिंदु रेखा के चारों ओर बिखरे हुए हैं (सभी ऊपर या नीचे नहीं)।
- अवशेषों में कोई स्पष्ट पैटर्न नहीं।
भाग 2:लॉजिस्टिक रिग्रेशन मॉडल
<पी> लॉजिस्टिक रिग्रेशन हां/नहीं निर्णयों की संभावनाओं की भविष्यवाणी करता है। लीनियर रिग्रेशन के विपरीत, जो सटीक संख्याओं की भविष्यवाणी करता है, लॉजिस्टिक रिग्रेशन कुछ घटित होने की संभावना (0-100%) की भविष्यवाणी करता है।चरण 1:बाइनरी वर्गीकरण डेटा तैयार करें
<पी> आइए ग्राहक खरीदारी व्यवहार का मॉडल बनाएं। ग्राहक आय स्तर (एक्स) के आधार पर, हम यह अनुमान लगाना चाहते हैं कि वे हमारा प्रीमियम उत्पाद (1) खरीदेंगे या नहीं (0)। यह विपणन लक्ष्यीकरण, चिकित्सा निदान, या किसी द्विआधारी निर्णय के लिए विशिष्ट है। <पी> लॉजिस्टिक रिग्रेशन के लिए डेटा सेट करें: <पी>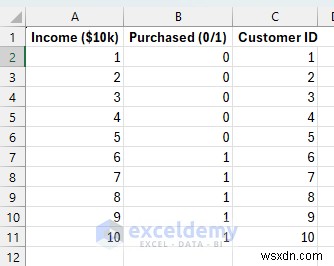 <पी> ग्राहक आय स्तर ($10k इकाइयों में) और खरीद निर्णय। ध्यान दें कि कैसे कम आय वाले ग्राहक (1-5) खरीदारी नहीं करते हैं (0), जबकि उच्च आय वाले ग्राहक (6-10) खरीदते हैं (1)। यह यथार्थवादी खरीदारी पैटर्न को दर्शाता है।
<पी> ग्राहक आय स्तर ($10k इकाइयों में) और खरीद निर्णय। ध्यान दें कि कैसे कम आय वाले ग्राहक (1-5) खरीदारी नहीं करते हैं (0), जबकि उच्च आय वाले ग्राहक (6-10) खरीदते हैं (1)। यह यथार्थवादी खरीदारी पैटर्न को दर्शाता है। चरण 2:लॉजिस्टिक भविष्यवाणी फॉर्मूला बनाएं
<पी> लॉजिस्टिक मॉडल पैरामीटर प्रारंभ करें: <पी> लॉजिस्टिक फ़ंक्शन के लिए पैरामीटर सेट करें। रैखिक प्रतिगमन के विपरीत, ये पैरामीटर अधिक जटिल गणितीय परिवर्तन (सिग्मॉइड फ़ंक्शन) के माध्यम से काम करते हैं।- अवरोधन (b0) :सीमा को बाएँ या दाएँ स्थानांतरित करता है (जहाँ 50% संभावना होती है)।
- ढलान (बी1) :यह नियंत्रित करता है कि "संभावना नहीं" से "संभावना" में परिवर्तन कितना तेज है।
- प्रारंभिक मूल्य :हम उचित अनुमानों से शुरुआत करते हैं; सॉल्वर उन्हें अनुकूलित करेगा।
Probability = 1 / (1 + e^(-(b0 + b1×X)))
- अवरोधन (b0)
- -2 (प्रारंभिक मान)
- ढलान (बी1)
- 0.5 (प्रारंभिक मान)
- रैखिक संयोजन :b0 + b1*X (रैखिक प्रतिगमन के समान)।
- सिग्मॉइड ट्रांसफॉर्म :1/(1+e^(-(रैखिक संयोजन))) किसी भी संख्या को 0-1 श्रेणी में परिवर्तित करता है।
- परिणाम :एक चिकना एस-वक्र जो संभाव्यता का प्रतिनिधित्व करता है। यदि संभावना 0.7 है, तो 70% संभावना है कि यह ग्राहक खरीदेगा।
- रैखिक संयोजन:
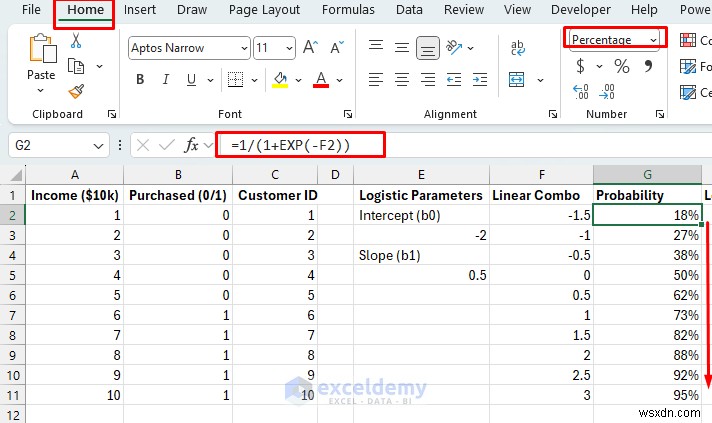
- संभावना पूर्वानुमान:
- कोशिकाओं को प्रतिशत (%) के रूप में प्रारूपित करें .
चरण 4:लॉग-संभावना की गणना करें
<पी> मापें कि हमारी संभाव्यता भविष्यवाणियाँ वास्तविक परिणामों से कितनी अच्छी तरह मेल खाती हैं। यह साधारण त्रुटियों से अधिक जटिल है क्योंकि हम संभावनाओं से निपट रहे हैं, सटीक मानों से नहीं। <पी> लॉग-संभावना घटक:=IF(B2=1,LN(MAX(G2,0.0001)),LN(MAX(1-G2,0.0001)))<पी>

- द्विआधारी परिणामों के लिए, हम सरल घटाव (वास्तविक - अनुमानित) का उपयोग नहीं कर सकते।
- इसके बजाय, हम मापते हैं कि हम अपनी भविष्यवाणी के वास्तविक परिणाम से कितने "आश्चर्यचकित" हैं।
- यदि हम खरीदारी की 90% संभावना का अनुमान लगाते हैं और ग्राहक खरीदारी करता है, तो हमें आश्चर्य नहीं होगा (अच्छा मॉडल)।
- यदि हम खरीदारी की 10% संभावना का अनुमान लगाते हैं और ग्राहक खरीदारी करता है, तो हमें बहुत आश्चर्य होता है (खराब मॉडल)।
चरण 5:लॉजिस्टिक मॉडल मेट्रिक्स सेट करें
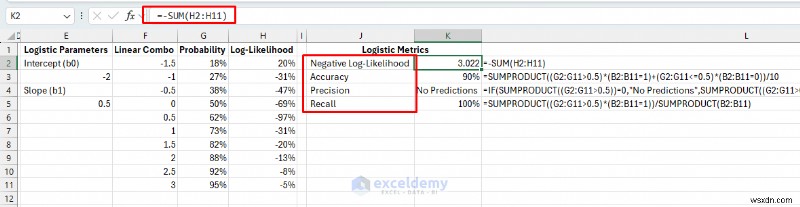
<पी> वर्गीकरण प्रदर्शन के व्यवसाय-प्रासंगिक उपाय बनाएं। ये मेट्रिक्स यह तय करने में मदद करते हैं कि मॉडल वास्तविक व्यावसायिक निर्णय लेने के लिए पर्याप्त है या नहीं। <पी> उच्च परिशुद्धता का अर्थ है कम बर्बाद विपणन डॉलर (कम झूठी सकारात्मकता)। उच्च रिकॉल का मतलब है कि हम संभावित ग्राहकों को नहीं चूकते (कम गलत नकारात्मक)। <पी> लॉजिस्टिक मेट्रिक्स:- मॉडल फ़िट/नकारात्मक लॉग-संभावना: कम मूल्यों का मतलब बेहतर संभाव्यता पूर्वानुमान है।
- सटीकता: ग्राहकों का प्रतिशत सही ढंग से वर्गीकृत किया गया है (यदि हम कटऑफ के रूप में 50% का उपयोग करते हैं)।
=SUMPRODUCT((G2:G11>0.5)*(B2:B11=1)+(G2:G11<=0.5)*(B2:B11=0))/10
- परिशुद्धता: हमने अनुमान लगाया था कि कितने प्रतिशत ग्राहक खरीदारी करेंगे, और कितने प्रतिशत ने खरीदारी की?
=IF(SUMPRODUCT((G2:G11>0.5))=0,"No Predictions",SUMPRODUCT((G2:G11>0.5)*(B2:B11=1))/SUMPRODUCT((G2:G11>0.5)))
- याद करें: कितने प्रतिशत ग्राहकों ने खरीदारी की, हमने कितने प्रतिशत की पहचान की?
=SUMPRODUCT((G2:G11>0.5)*(B2:B11=1))/SUMPRODUCT(B2:B11)<पी>
चरण 6:सॉल्वर के साथ लॉजिस्टिक मॉडल को अनुकूलित करें
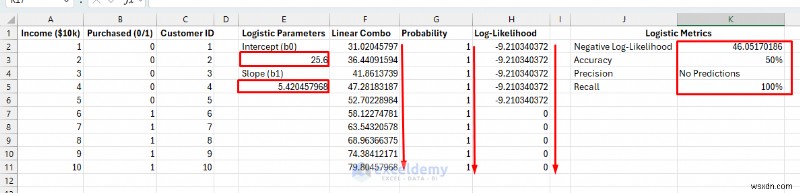
<पी> वे पैरामीटर मान ढूंढें जो डेटा में संभाव्यता पैटर्न के लिए सबसे उपयुक्त हों। सॉल्वर नकारात्मक लॉग-संभावना को कम करता है, जो वास्तविक डेटा को देखने की संभावना को अधिकतम करता है।- डेटा पर जाएं टैब>> सॉल्वर चुनें .
- उद्देश्य निर्धारित करें:K2 (नकारात्मक लॉग-संभावना).
- प्रति:मिन .
- वेरिएबल सेल्स को बदलकर:E3,E5 .
- समाधान क्लिक करें .
सामान्य समस्याओं का निवारण करें
- सॉल्वर जुट नहीं रहा है :भिन्न प्रारंभिक मान आज़माएं या पुनरावृत्तियां बढ़ाएं।
- नकारात्मक आर-वर्ग :डेटा प्रविष्टि त्रुटियों या मॉडल विनिर्देश की जाँच करें।
- लॉजिस्टिक्स में परफेक्ट सेपरेशन :सुविधा मान कम करें या नियमितीकरण जोड़ें।