हाल ही में, वास्तव में अच्छा, नया, अनूठा लिनक्स सॉफ्टवेयर खोजना एक मुश्किल काम बन गया है। एक काम। और हाल ही में, मेरा मतलब वास्तव में इन पिछले चार या पाँच वर्षों से था, भले ही डेस्कटॉप स्पेस में उत्साह और नवीनता की धीमी गिरावट शुरू हो गई थी। आखिरकार, बुद्धि की एक सीमित मात्रा में कितनी अच्छी चीजें मौजूद हो सकती हैं, इसकी एक सीमा होती है, लेकिन हमें मोबाइल पर ध्यान केंद्रित करने के गलत बदलाव और साल-दर-साल के लिनक्स सपने के बिखरने को नहीं भूलना चाहिए।
मुझे लगता है कि यह ओसीआरफीडर नाम के चार साल पुराने सॉफ्टवेयर के मेरे परीक्षण को वैध बनाता है। दो कारणों से। अगर यह अच्छा है, तो अच्छा है। दूसरा, मुझे हमेशा ऑप्टिकल कैरेक्टर रिकग्निशन की प्रगति में दिलचस्पी रही है, और क्या हमारे उपकरण (एआई पढ़ें) यहां एक उचित काम कर सकते हैं। मैंने कुछ समय पहले इसके बारे में विस्तार से लिखा था, और फिर 2015 में YAGF की समीक्षा की। अब, OCRFeeder पर एक नजर डालते हैं और यह क्या कर सकता है। मेरे बाद, बहादुर लिनक्स योद्धा।
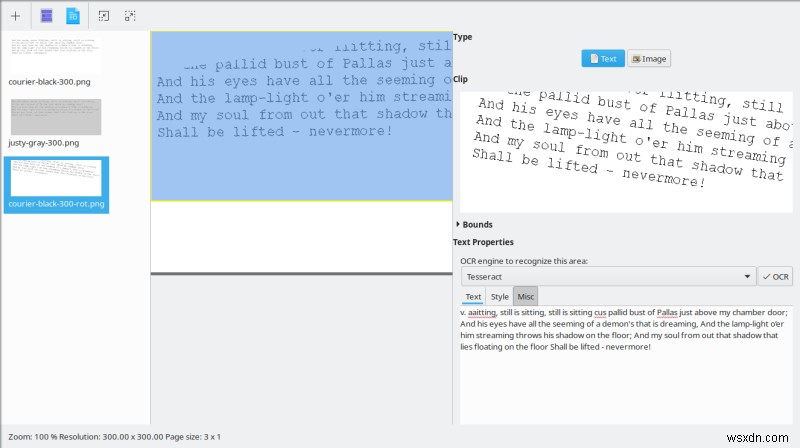
जेपीजी के लिए शब्द आसान नहीं होते
मैंने प्रोग्राम इंस्टॉल किया। ऐसी बहुत सी लाइब्रेरी हैं जिन्हें आपको हथियाने की आवश्यकता है। उबंटू 18.04 में, सूची काफी कुछ पंक्तियों में चली गई। आपको इस प्रोग्राम के लिए डिफ़ॉल्ट किट के रूप में Tesseract OCR इंजन मिलता है।
निम्नलिखित अतिरिक्त पैकेज इंस्टॉल किए जाएंगे:
blt gir1.2-goocanvas-2.0 gir1.2-gtkspell3-3.0 libgoocanvas-2.0-9 libgoocanvas-2.0-common libgtkspell3-3-0 liblept5 libtesseract4 libyelp0 python-bs4 python- chardet अजगर-करामाती अजगर-html5lib अजगर-एलएक्सएमएल अजगर-संख्या अजगर-ओलेफाइल अजगर-पाइल अजगर-रेंडरपीएम अजगर-रिपोर्टलैब -osd tk8.6-blt2.5 अनपेपर येल्प येल्प-एक्सएसएल
सुझाए गए पैकेज:
blt-demo python-gobject python-wxgtk3.0 python-genshi python-lxml-dbg python- lxml-doc gfortran अजगर-देव अजगर-नाक अजगर-numpy-dbg अजगर-numpy-doc अजगर-बच्चे-डॉक टिक्स पायथन-टीके-डीबीजी
इसे लॉन्च किया। इंटरफ़ेस थोड़ा उपयोगी है। आपको सबसे पहले एक या एक से अधिक छवियों को लोड करने की आवश्यकता है, जिसका उपयोग आप अपने ओसीआर इंजन को फीड करने के लिए करेंगे, और उम्मीद है कि इसने दूसरे छोर पर उचित-सटीकता पाठ का उत्पादन किया होगा। एक बार जब आप इसे पूरा कर लेते हैं, तो आप टेक्स्ट को लिब्रे ऑफिस में निर्यात कर सकते हैं।
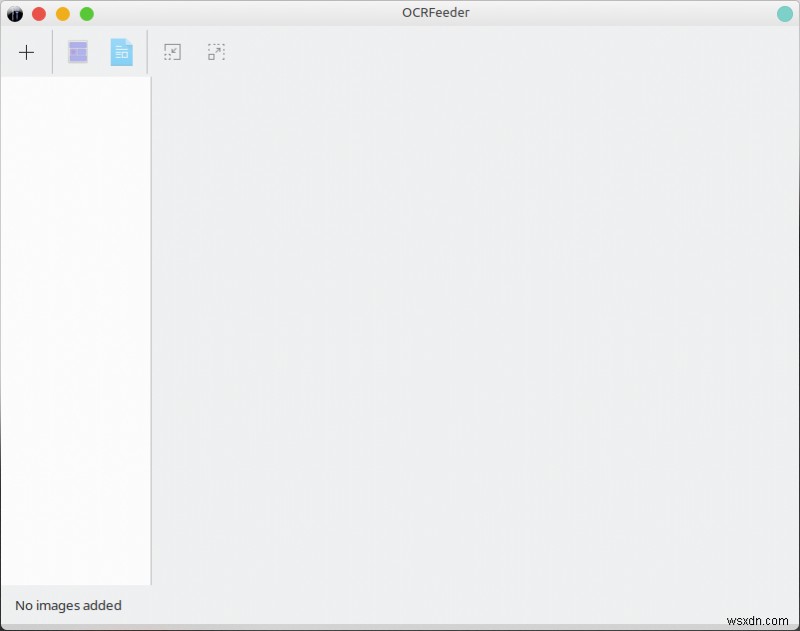
ओसीआर इंजन
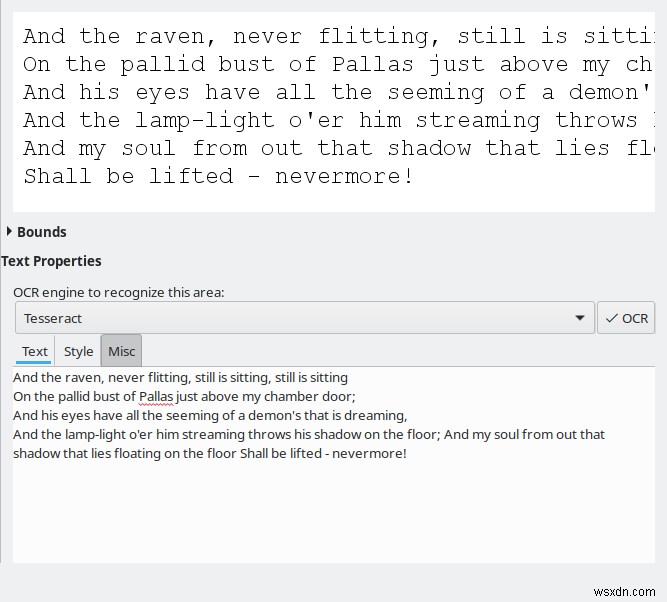
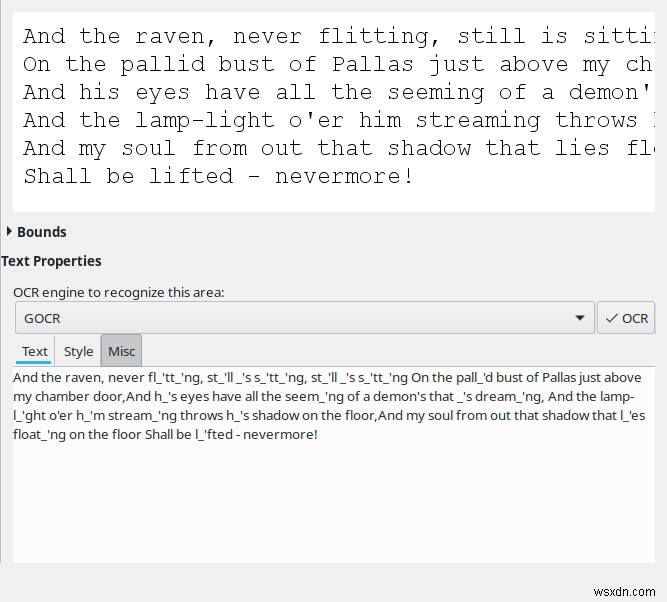
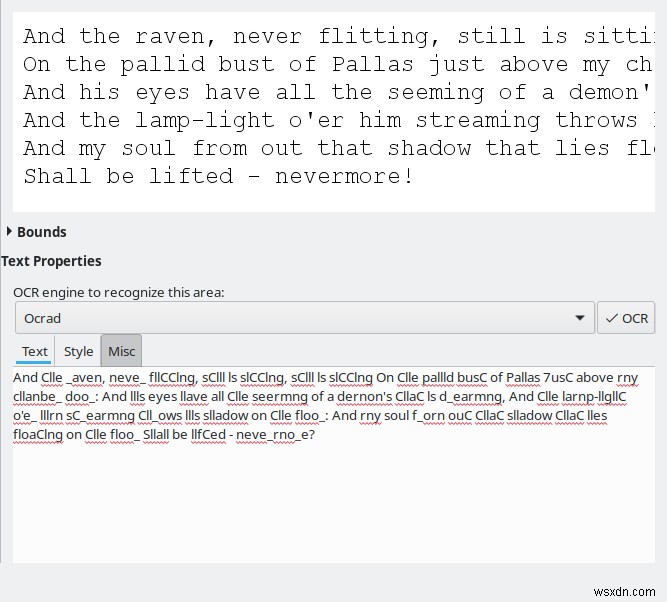
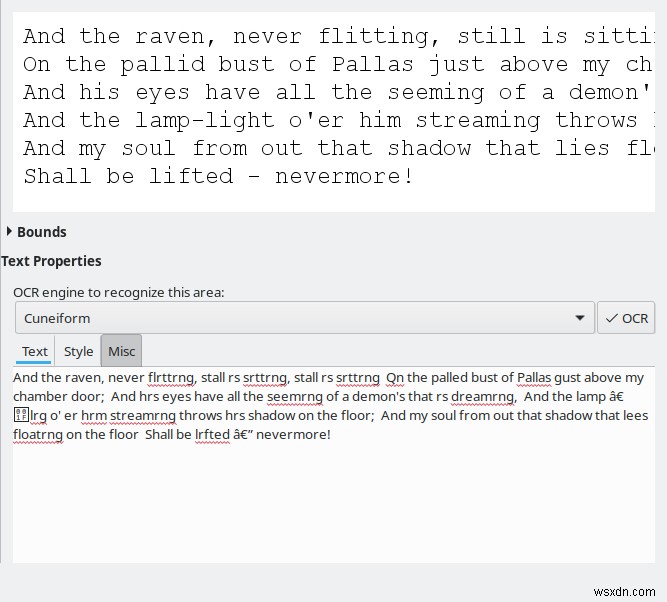
जैसा कि मैंने उल्लेख किया है, डिफ़ॉल्ट रूप से, OCRFeeder Tesseract का उपयोग करेगा, लेकिन आप अपनी पसंद का कोई अन्य इंजन जोड़ सकते हैं। दरअसल, मैंने CuneiForm, GOCR और Ocrad को आजमाया, और प्रोग्राम ने उन सभी का सही पता लगाया और लोड किया। बहुत साफ़। यह आपको अपने दस्तावेज़ों को कई तरीकों से आज़माने की क्षमता देता है, क्योंकि इनमें से कुछ इंजनों के साथ आपका भाग्य अच्छा हो सकता है।
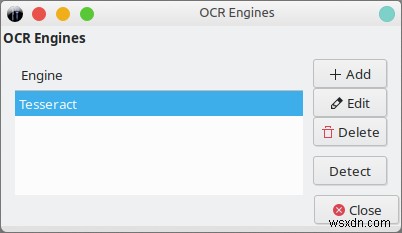
sudo apt-get install कीलाकार gocr ocrad
छवि-से-पाठ रूपांतरण
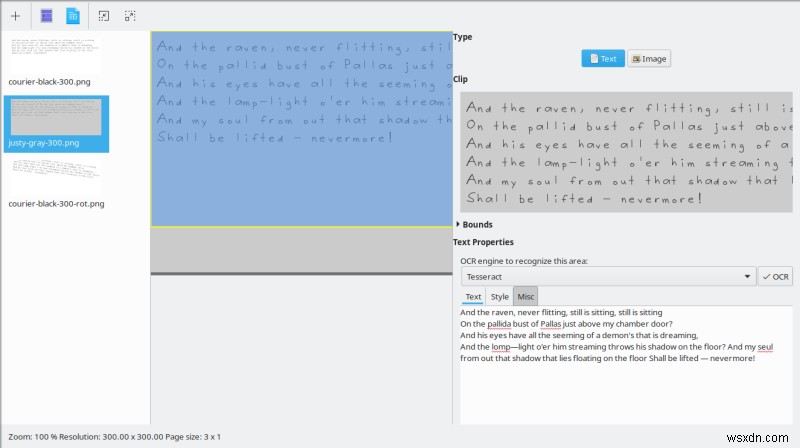
अब, महत्वपूर्ण हिस्सा। मैंने यहां थोड़ा संघर्ष किया। मैंने कार्यक्रम को सभी उपलब्ध छवियों में टेक्स्ट को ऑटो-डिटेक्ट करने दिया (सभी पृष्ठों को पहचानें), और मुझे कुछ अजीब रंग-चिह्नित आउटपुट मिले। तीन लोड की गई PNG फ़ाइलों को पूरा करने में इस चीज़ को पूरा करने में लगभग तीन मिनट का समय लगा, और उस समय के दौरान, OCRFeeder CPU का उपयोग लगभग 17% था, और Tesseract लगभग 4-5% का उपयोग कर रहा था। यदि एप्लिकेशन सभी प्रोसेसर कोर का उपयोग करने का बेहतर काम करता है तो निश्चित रूप से समय कम किया जा सकता है। फिर, अजीब आउटपुट। मुझे पूरा यकीन नहीं था कि मुझे क्या करना है। अजीब। ऐसा लग रहा था कि मैं बिल्कुल भी प्रगति नहीं कर रहा था।

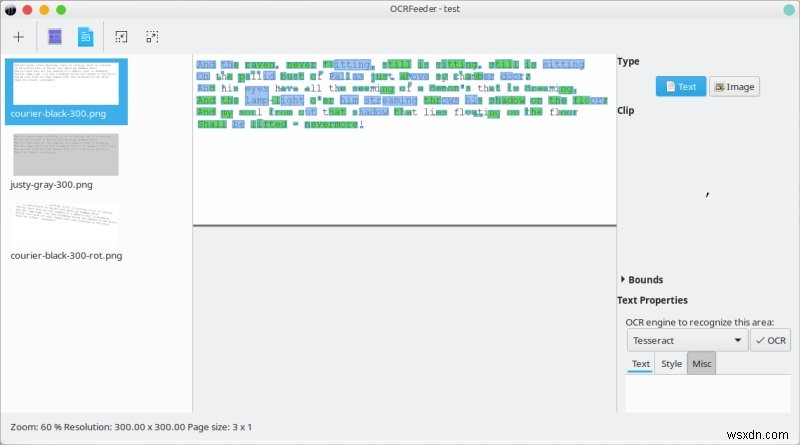
फिर, मुझे एहसास हुआ कि मैं प्रदर्शित छवियों के हिस्सों को खींचने और चुनने के लिए माउस का उपयोग कर सकता हूं, और फिर, एक अलग फलक खुल जाएगा, जहां मैं वांछित ओसीआर इंजन चुन सकता हूं और वास्तविक रूपांतरण चला सकता हूं। विज़ुअल गड़बड़ियों को छोड़ दें, तो इसने यथोचित रूप से अच्छा काम किया, और प्रत्येक छवि को संसाधित करने में केवल कुछ सेकंड लगे।
बिना किसी प्रशिक्षण या चूक में बदलाव के, चार उपलब्ध इंजनों के बीच परिणामों की भिन्नता बहुत बड़ी थी। Tesseract ने सबसे अच्छा - और केवल स्वीकार्य रूपांतरण प्रदर्शित किया। बाकी बिल्कुल उपयोग करने पर विचार करने के लिए पर्याप्त नहीं थे। मुझे यकीन नहीं है क्यों, यह ऐसा ही है।
मैंने ग्रे-बैकग्राउंड इमेज के साथ बेहतर परिणाम भी देखे। अतीत में, Tesseract ने संघर्ष किया, इसलिए इस इंजन में जो भी सुधार हुए हैं, उनका स्वागत है। लेकिन फिर, यह कड़ाई से एक OCRFeeder चीज नहीं है, और यदि आप चाहें तो कमांड लाइन से, आप अपने दम पर Tesseract चला सकते हैं।
डेस्क्युइंग और पेपरिंग
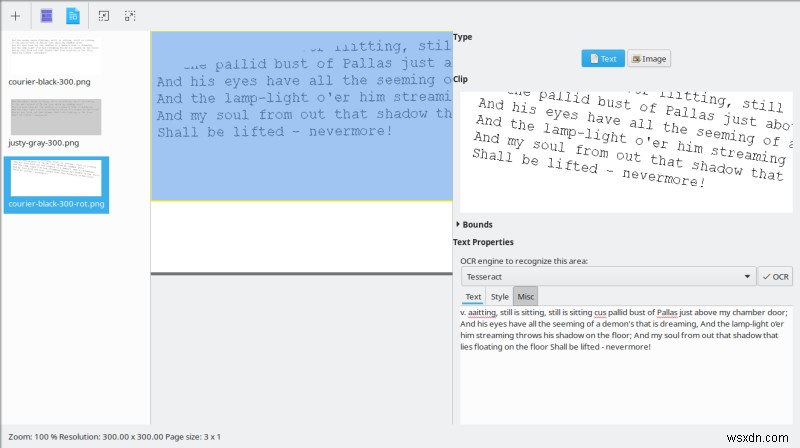
OCRFeeder दो निफ्टी फ़ंक्शंस के साथ आता है - तिरछी छवि स्कैन में टेक्स्ट को ऑटो-रोटेट करने की कोशिश करने की क्षमता, और शोर को कम करने और अधिक सटीक रूपांतरण की अनुमति देने के लिए पेपर बैकग्राउंड को हटाने की क्षमता। मैंने दोनों विकल्पों को आजमाया, और डेस्क्यू ने ठीक काम किया। अनपेपरिंग, सो-सो। लेकिन मेरे द्वारा पाठ को घुमाए जाने के बाद (जो मैंने जीआईएमपी में नियंत्रित छवियों में किया था), रूपांतरण के परिणाम और भी बेहतर थे।
ODT को निर्यात करें
यह थोड़ा पेचीदा था। मैंने इसे कुछ बार आजमाया, और मैंने त्रुटियों का एक गुच्छा मारा। आखिरकार इसने काम किया। आउटपुट सबसे सुंदर नहीं है, लेकिन अच्छी बात यह है कि आप एक ही समय में कई रूपांतरण निर्यात कर सकते हैं, जिसमें विभिन्न छवियों के लिए विभिन्न इंजनों का उपयोग करना भी शामिल है। काफी निफ्टी।
वरीयताएँ
अंत में, आपके पास प्रोग्राम के व्यवहार को बदलने का विकल्प होता है। कुछ भी बड़ा नहीं है, लेकिन यह पता लगाने और सटीकता के साथ मदद कर सकता है। अधिकतर यह नीचे आता है कि आप टेक्स्ट कॉलम की चौड़ाई, मार्जिन, भाषा चयन और समान रूप से कैसे पता लगाते हैं। अधिकांश लोगों के लिए, डिफ़ॉल्ट एक उचित प्रारंभिक बिंदु होगा।
निष्कर्ष
OCRFeeder सॉफ्टवेयर का एक उचित, लचीला टुकड़ा है। यह कई इंजनों का उपयोग कर सकता है, और छवि-फिक्सिंग एल्गोरिदम एक अच्छा जोड़ है। यह OCRFeeder को मुक्त बाजार पर इस तरह का संभवतः सबसे आशाजनक सॉफ्टवेयर बनाता है, लेकिन फिर आपकी उम्मीदें तुरंत धराशायी हो जानी चाहिए, क्योंकि जब तक कोई इसे नहीं उठाता, तब तक किसी भी समय जल्द ही अपडेट देखने की संभावना नहीं है। क्योंकि इसमें बाजार होना है, लेकिन लिनक्स की दुनिया थकान और उदासीनता के बीच एक कठिन स्थिति में फंस गई है।
वह एक तरफ, उम्र और अद्यतन बात एक तरफ, अधिकांश भाग के लिए, OCRFeeder दिया। रूपांतरण गुणवत्ता खराब नहीं थी, आप अपना काम करने के लिए यूआई का उपयोग करके कुछ भी नहीं खोते हैं, और निर्यात फ़ंक्शन आपको आगे के संपादन के लिए अच्छे दस्तावेज़ बनाने देता है और इसी तरह। मैं टेसरेक्ट में सुधारों से भी खुश हूं। इसलिए यदि आपके पास पाठ-प्रसन्न छवियों का एक समूह है, और आप प्राचीन रूपों पर हाथ से लिखे गए पाठ को कुछ आधुनिक और प्रयोग करने योग्य में परिवर्तित करने का प्रयास करना चाहते हैं, तो आप यह कर सकते हैं। OCRFeeder पीडीएफ के साथ-साथ स्कैनर से सीधे पढ़ने का समर्थन करता है। प्रयोग के लायक। अब जाने का समय, अलविदा।
चीयर्स।