<पी>  <पी> 30 अप्रैल, 2026, 10:30 पूर्वाह्न EDT पर प्रकाशित <पी> यासिर एक मैकेनिकल इंजीनियर है जो एमयूओ में तकनीक के बारे में लिखता है, जिसमें विंडोज़, उत्पादकता, सुरक्षा और इंटरनेट शामिल हैं। स्वायत्त प्रणालियों में उनकी रुचि उन्हें हार्डवेयर और सॉफ्टवेयर दोनों के साथ लगातार छेड़छाड़ करने के लिए प्रेरित करती है। <पी> उनकी तकनीकी लेखन यात्रा इंजीनियरिंग के जूनियर वर्ष के दौरान शुरू हुई, जिससे वे एमयूओ में शामिल होने से पहले एंड्रॉइड पुलिस में चले गए। वह प्रौद्योगिकी को सुलभ बनाने पर ध्यान केंद्रित करता है, चाहे वह विंडोज़ समस्याओं का निवारण करना हो, उत्पादकता टूल की खोज करना हो, या सरल अंग्रेजी में सुरक्षा जोखिमों की व्याख्या करना हो। यासिर के लिए, ऐसा करने का सबसे अच्छा तरीका वास्तव में टूल का उपयोग करना और उन्हीं समस्याओं का सामना करना है जिनका सामना पाठक करते हैं। <पी> जब वह लिख नहीं रहा होता या इंजीनियरिंग नहीं कर रहा होता, तो आप पाएंगे कि यासिर इम्प्रैक्टिकल जोकर देख रहा है और उन शरारतों पर सचमुच हंस रहा है जो उसने पहले एक दर्जन बार देखी हैं। <पी> मैं जानता हूं कि अधिकांश एक्सेल उपयोगकर्ताओं ने सूत्रों को उसी तरह सीखा जैसे मैंने सीखा - एक समय में एक फ़ंक्शन, जो कुछ भी वे पहले से जानते थे उसके शीर्ष पर रखा गया था। गतिशील सरणी फ़ंक्शन उन कौशलों को प्रतिस्थापित नहीं करते हैं; वे बहुत सारे कामकाज को अनावश्यक बना देते हैं। मैं कुछ समय से TAKE और DROP के साथ अपनी सेल्फ-अपडेटिंग टॉप-पांच सूचियां चला रहा हूं, और नीचे दिए गए चार कार्यों के साथ भी यही बदलाव हुआ है। प्रत्येक ने एक बहु-चरणीय दिनचर्या को कम कर दिया जिसका उपयोग मैं एक ही सूत्र में प्रतिवर्ती रूप से करने के लिए करता था। <पी>
<पी> 30 अप्रैल, 2026, 10:30 पूर्वाह्न EDT पर प्रकाशित <पी> यासिर एक मैकेनिकल इंजीनियर है जो एमयूओ में तकनीक के बारे में लिखता है, जिसमें विंडोज़, उत्पादकता, सुरक्षा और इंटरनेट शामिल हैं। स्वायत्त प्रणालियों में उनकी रुचि उन्हें हार्डवेयर और सॉफ्टवेयर दोनों के साथ लगातार छेड़छाड़ करने के लिए प्रेरित करती है। <पी> उनकी तकनीकी लेखन यात्रा इंजीनियरिंग के जूनियर वर्ष के दौरान शुरू हुई, जिससे वे एमयूओ में शामिल होने से पहले एंड्रॉइड पुलिस में चले गए। वह प्रौद्योगिकी को सुलभ बनाने पर ध्यान केंद्रित करता है, चाहे वह विंडोज़ समस्याओं का निवारण करना हो, उत्पादकता टूल की खोज करना हो, या सरल अंग्रेजी में सुरक्षा जोखिमों की व्याख्या करना हो। यासिर के लिए, ऐसा करने का सबसे अच्छा तरीका वास्तव में टूल का उपयोग करना और उन्हीं समस्याओं का सामना करना है जिनका सामना पाठक करते हैं। <पी> जब वह लिख नहीं रहा होता या इंजीनियरिंग नहीं कर रहा होता, तो आप पाएंगे कि यासिर इम्प्रैक्टिकल जोकर देख रहा है और उन शरारतों पर सचमुच हंस रहा है जो उसने पहले एक दर्जन बार देखी हैं। <पी> मैं जानता हूं कि अधिकांश एक्सेल उपयोगकर्ताओं ने सूत्रों को उसी तरह सीखा जैसे मैंने सीखा - एक समय में एक फ़ंक्शन, जो कुछ भी वे पहले से जानते थे उसके शीर्ष पर रखा गया था। गतिशील सरणी फ़ंक्शन उन कौशलों को प्रतिस्थापित नहीं करते हैं; वे बहुत सारे कामकाज को अनावश्यक बना देते हैं। मैं कुछ समय से TAKE और DROP के साथ अपनी सेल्फ-अपडेटिंग टॉप-पांच सूचियां चला रहा हूं, और नीचे दिए गए चार कार्यों के साथ भी यही बदलाव हुआ है। प्रत्येक ने एक बहु-चरणीय दिनचर्या को कम कर दिया जिसका उपयोग मैं एक ही सूत्र में प्रतिवर्ती रूप से करने के लिए करता था। <पी>  संबंधित
संबंधित फ़िल्टर ने सहायक स्तंभों और सरणी सूत्रों की पूरी प्रक्रिया को प्रतिस्थापित कर दिया
अब एक सूत्र वह काम करता है जो कई कार्यों को उनके बीच विभाजित करने के लिए किया जाता है
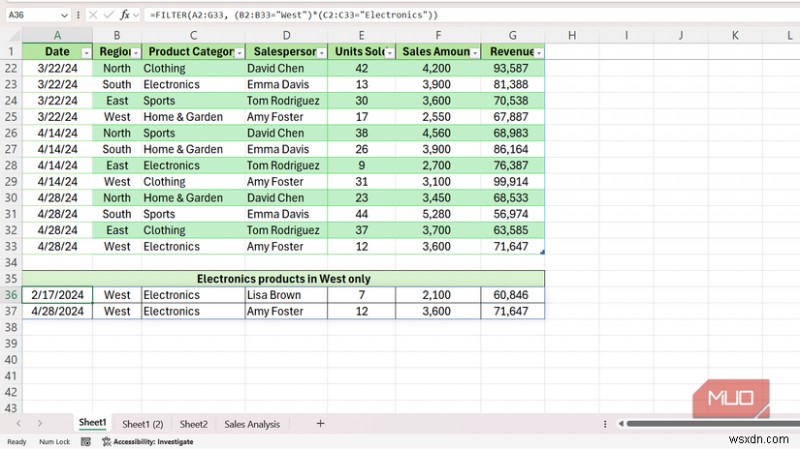 <पी> पुराने Excel में मिलती-जुलती पंक्तियाँ खींचने का मतलब एक नेस्टेड INDEX, MATCH, SMALL और IFERROR फॉर्मूला बनाना और उसे Ctrl + Shift + Enter के साथ दर्ज करना था। इसने काम किया, लेकिन बाद में इसे बनाए रखना एक समस्या थी। दूसरा विकल्प ऑटोफ़िल्टर लागू करना, दृश्यमान पंक्तियों की प्रतिलिपि बनाना और उन्हें स्थिर मानों के रूप में कहीं और पेस्ट करना था। स्रोत डेटा बदलने तक यह भी ठीक था। <पी> FILTER फ़ंक्शन एक पंक्ति में समान कार्य करता है। मेरी बिक्री स्प्रेडशीट में, जिसमें क्षेत्रों, उत्पाद श्रेणियों और विक्रेताओं की 32 पंक्तियाँ हैं, पश्चिम क्षेत्र से प्रत्येक इलेक्ट्रॉनिक्स बिक्री को खींचना इस तरह दिखता है:
<पी> पुराने Excel में मिलती-जुलती पंक्तियाँ खींचने का मतलब एक नेस्टेड INDEX, MATCH, SMALL और IFERROR फॉर्मूला बनाना और उसे Ctrl + Shift + Enter के साथ दर्ज करना था। इसने काम किया, लेकिन बाद में इसे बनाए रखना एक समस्या थी। दूसरा विकल्प ऑटोफ़िल्टर लागू करना, दृश्यमान पंक्तियों की प्रतिलिपि बनाना और उन्हें स्थिर मानों के रूप में कहीं और पेस्ट करना था। स्रोत डेटा बदलने तक यह भी ठीक था। <पी> FILTER फ़ंक्शन एक पंक्ति में समान कार्य करता है। मेरी बिक्री स्प्रेडशीट में, जिसमें क्षेत्रों, उत्पाद श्रेणियों और विक्रेताओं की 32 पंक्तियाँ हैं, पश्चिम क्षेत्र से प्रत्येक इलेक्ट्रॉनिक्स बिक्री को खींचना इस तरह दिखता है: =FILTER(A2:G33, (B2:B33="West")*(C2:C33="Electronics"))
<पी> पहला तर्क वह सीमा है जिसे आप वापस करना चाहते हैं। दूसरी शर्त है, और दो जांचों के बीच गुणन एक AND के रूप में कार्य करता है - दोनों को सत्य होना चाहिए। तारांकन को प्लस चिह्न पर स्विच करने से यह OR बन जाता है, और परिणाम स्वचालित रूप से सामने आ जाता है। स्रोत में एक नई पंक्ति जोड़ने से एंटर दबाते ही स्पिल्ड आउटपुट अपडेट हो जाता है। <पी> खाली परिणामों को संभालने के लिए आप तीसरे तर्क के साथ IFERROR में FILTER लपेट सकते हैं। =FILTER(range, condition, "No matches") आपकी शीट को #CALC दिखाने से रोकता है! त्रुटियाँ जब कोई पंक्तियाँ योग्य नहीं होतीं। UNIQUE ने मेरे तीन-चरणीय डुप्लिकेशन रूटीन को एक एकल कक्ष में बदल दिया
डुप्लिकेट हटाना अच्छा है, लेकिन इसने मेरे लिए कभी भी स्वयं को अपडेट नहीं किया है
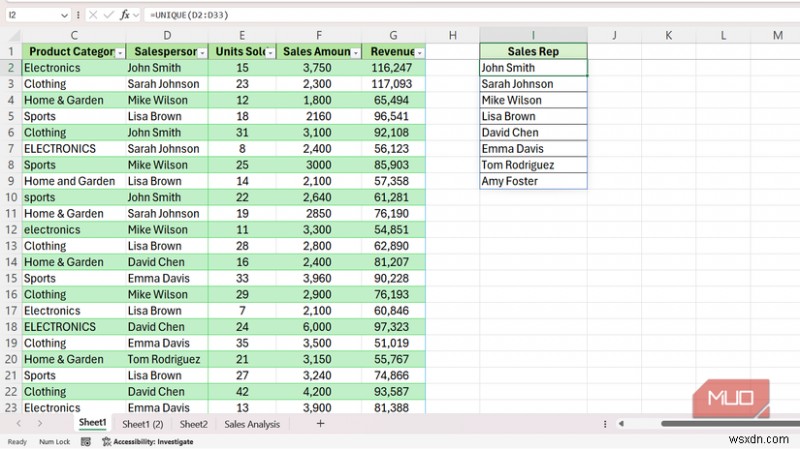 <पी> डेटा टैब के अंतर्गत डुप्लिकेट हटाएँ विकल्प एक बार की सफ़ाई के लिए ठीक है। समस्या यह है कि यह एक स्थिर सूची तैयार करता है। जब आप किसी कॉलम को किसी नए स्थान पर कॉपी करते हैं, संवाद चलाते हैं, या परिणामों को क्रमबद्ध करते हैं, तो अगली बार जब कोई पंक्ति जोड़ता है तो आपको यह सब फिर से करना होगा। मैंने इसे गिनने से कहीं अधिक बार किया है। <पी> UNIQUE उसके हर चरण को छोड़ देता है। मेरी बिक्री स्प्रेडशीट में सेल्सपर्सन कॉलम पर इसे इंगित करने पर यह इस तरह दिखता है:
<पी> डेटा टैब के अंतर्गत डुप्लिकेट हटाएँ विकल्प एक बार की सफ़ाई के लिए ठीक है। समस्या यह है कि यह एक स्थिर सूची तैयार करता है। जब आप किसी कॉलम को किसी नए स्थान पर कॉपी करते हैं, संवाद चलाते हैं, या परिणामों को क्रमबद्ध करते हैं, तो अगली बार जब कोई पंक्ति जोड़ता है तो आपको यह सब फिर से करना होगा। मैंने इसे गिनने से कहीं अधिक बार किया है। <पी> UNIQUE उसके हर चरण को छोड़ देता है। मेरी बिक्री स्प्रेडशीट में सेल्सपर्सन कॉलम पर इसे इंगित करने पर यह इस तरह दिखता है: =UNIQUE(D2:D33)
<पी> परिणाम में जॉन स्मिथ, सारा जॉनसन, माइक विल्सन, लिसा ब्राउन, डेविड चेन, एम्मा डेविस, टॉम रोड्रिग्ज और एमी फोस्टर शामिल हैं। ये आठ नाम हैं जिनमें कोई डायलॉग बॉक्स नहीं है। इसे =SORT(UNIQUE(D2:D33)) के रूप में लपेटें वही सूची वर्णानुक्रम में लौटाता है। आउटपुट स्रोत से जुड़ा रहता है, इसलिए डेटा में एक नया नाम जोड़ने से स्पिल्ड सूची स्वचालित रूप से बढ़ जाती है। <पी> यह सेटअप डेटा सत्यापन ड्रॉपडाउन सूची के लिए एक स्वच्छ स्रोत भी बनाता है। यदि आप स्पिल्ड रेंज को D35# जैसे हैश के साथ संदर्भित करते हैं , जैसे ही स्रोत डेटा में नए नाम दिखाई देते हैं, आपका ड्रॉपडाउन अपने आप बढ़ता है। SORTBY ने मेरे कॉपी-पेस्ट-और-सॉर्ट फेरबदल को हमेशा के लिए समाप्त कर दिया
स्रोत डेटा को छुए बिना किसी दृश्य को क्रमबद्ध करना
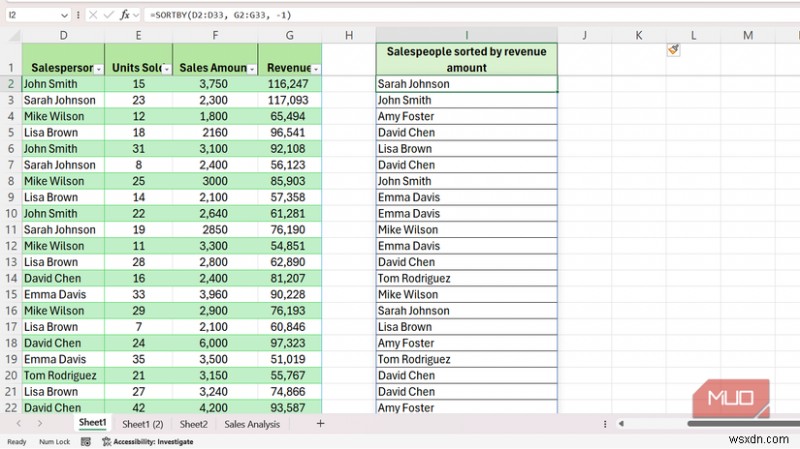 <पी> एक्सेल में सॉर्टिंग में हमेशा एक छोटा सा जोखिम होता है। स्रोत को पुनर्व्यवस्थित करने से निश्चित पंक्तियों को संदर्भित करने वाले सूत्र टूट सकते हैं, इसलिए मेरी वापसी किसी सुरक्षित स्थान पर एक टुकड़े की प्रतिलिपि बनाने और प्रतिलिपि को क्रमबद्ध करने की थी। SORT ने मदद की, लेकिन केवल तभी जब मैं अपने द्वारा क्रमबद्ध किए गए प्रत्येक कॉलम को प्रदर्शित करके खुश था। <पी> SORTBY उस बाधा को दूर करता है। यह दूसरी श्रेणी के मानों का उपयोग करके एक श्रेणी को सॉर्ट करता है, और दूसरी श्रेणी को आउटपुट में प्रदर्शित होने की आवश्यकता नहीं होती है। मैंने अपने डेटासेट में राजस्व के आधार पर सेल्सपर्सन को रैंक करने के लिए निम्नलिखित सूत्र का उपयोग किया:
<पी> एक्सेल में सॉर्टिंग में हमेशा एक छोटा सा जोखिम होता है। स्रोत को पुनर्व्यवस्थित करने से निश्चित पंक्तियों को संदर्भित करने वाले सूत्र टूट सकते हैं, इसलिए मेरी वापसी किसी सुरक्षित स्थान पर एक टुकड़े की प्रतिलिपि बनाने और प्रतिलिपि को क्रमबद्ध करने की थी। SORT ने मदद की, लेकिन केवल तभी जब मैं अपने द्वारा क्रमबद्ध किए गए प्रत्येक कॉलम को प्रदर्शित करके खुश था। <पी> SORTBY उस बाधा को दूर करता है। यह दूसरी श्रेणी के मानों का उपयोग करके एक श्रेणी को सॉर्ट करता है, और दूसरी श्रेणी को आउटपुट में प्रदर्शित होने की आवश्यकता नहीं होती है। मैंने अपने डेटासेट में राजस्व के आधार पर सेल्सपर्सन को रैंक करने के लिए निम्नलिखित सूत्र का उपयोग किया: =SORTBY(D2:D33, G2:G33, -1)
<पी> पहला तर्क यह है कि आप क्या लौटाना चाहते हैं (विक्रेता), दूसरा यह है कि क्या क्रमबद्ध करना है (बिक्री राजस्व), और -1 अवरोही क्रम निर्धारित करता है। नाम उच्चतम बिक्री राशि से निम्नतम तक के क्रम में वापस आते हैं, और बिक्री राशि कॉलम आउटपुट में कभी भी दिखाई नहीं देता है जब तक कि आप इसके लिए नहीं पूछते हैं। <पी> यह फिल्टर के साथ भी सफाई से जुड़ जाता है। रैपिंग FILTER(D2:G33, B2:B33="North") SORTBY के अंदर केवल उत्तरी क्षेत्र के रिकॉर्ड, उच्च से निम्न क्रम में, एक ही बार में लौटाए जाते हैं। स्रोत डेटा अछूता रहता है। <पी> SORTBY एकाधिक सॉर्ट स्तरों को स्वीकार करता है। आप पहले क्षेत्र के आधार पर, फिर प्रत्येक क्षेत्र के भीतर बिक्री राजस्व के आधार पर क्रमबद्ध करने के लिए अधिक रेंज/ऑर्डर जोड़े जोड़ सकते हैं। SEQUENCE ने भरण हैंडल और ROW ट्रिक्स को बदल दिया जिन पर मुझे गर्व था
एक भी सेल को खींचे बिना एक श्रृंखला उत्पन्न करना
 <पी> क्रमांकित श्रृंखला उत्पन्न करने का अर्थ भरण हैंडल को तब तक खींचना होता है जब तक कि मैं धैर्य न खो दूं या
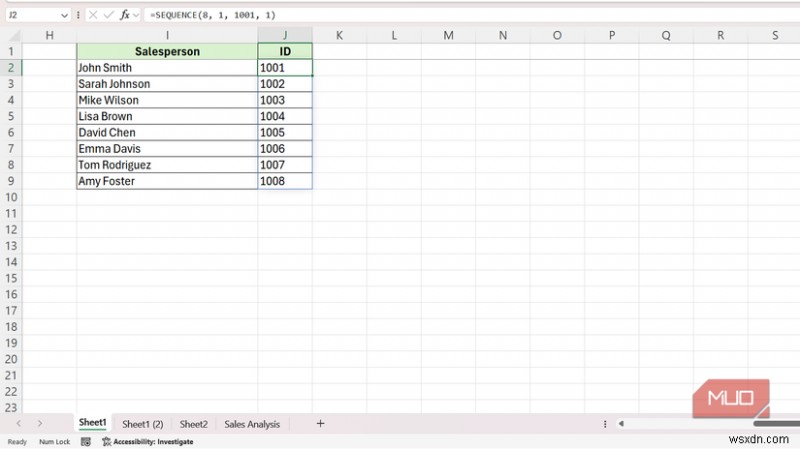
<पी> क्रमांकित श्रृंखला उत्पन्न करने का अर्थ भरण हैंडल को तब तक खींचना होता है जब तक कि मैं धैर्य न खो दूं या =ROW(A1) न लिख दूं। और इसे कॉपी कर रहा हूँ। दोनों काम करते हैं, लेकिन अंतर्निहित डेटा बदलने पर कोई भी आकार नहीं बदलता। <पी> SEQUENCE एक ही सेल में एक ही कार्य को संभालता है, और यह तर्कों के आधार पर पंक्तियाँ, कॉलम या पूर्ण ग्रिड उत्पन्न करता है। वाक्यविन्यास है: =SEQUENCE(rows, [columns], [start], [step])
<पी> अपने डेटा में आठ अद्वितीय सेल्सपर्सन को 1001 से शुरू करने के लिए, मैंने निम्नलिखित सूत्र का उपयोग किया: =SEQUENCE(8, 1, 1001, 1)
<पी> यह एक कॉलम में 1001 से 1008 तक रिटर्न देता है। कॉलम को 1 और चरण को 1 पर सेट करने से यह लगातार पूर्णांकों के साथ एक लंबवत सूची के रूप में रहता है। जहां SEQUENCE अपना स्थान अर्जित करता है वह अन्य कार्यों के अंदर है। जनवरी 2026 के लिए 31-दिवसीय तिथि सीमा बनाने के लिए एक सूत्र की आवश्यकता होती है: =DATE(2026, 1, SEQUENCE(31))
<पी> स्पिल्ड ऐरे को TEXT, INDEX, या किसी अन्य फ़ंक्शन में फीड करने से एक रेंज की उम्मीद करने से हेल्पर कॉलम की आवश्यकता समाप्त हो जाती है। जब मैंने दिनांक कॉलम भरने के लिए SEQUENCE का उपयोग करने के बारे में लिखा था, तो मैंने इसे और अधिक विस्तार से कवर किया था, और यह अभी भी मेरे द्वारा बनाए गए प्रत्येक कैलेंडर या शेड्यूल पर मेरा समय बचाता है। जिन कार्यों के बारे में मैं आगे जानना चाहता हूं
<पी> कोई भी पुराना तरीका टूटा नहीं है. वे बस अधिक समय लेते हैं और ऐसी फ़ाइलें तैयार करते हैं जिनका रखरखाव करना कठिन होता है, मेरे लिए और बाद में कार्यपुस्तिका खोलने वाले किसी भी अन्य व्यक्ति के लिए। मेरे लिए, बदलाव वह है जिस तक मैं डिफ़ॉल्ट रूप से पहुंचता हूं। नई स्प्रेडशीट गतिशील सरणी सोच के साथ शुरू होती हैं, और पुराना टूलबॉक्स केवल तभी सामने आता है जब मैं किसी और की फ़ाइल को संपादित कर रहा होता हूं। मेरी सूची में अगला है स्ट्रिंग्स को तोड़ने के लिए TEXTSPLIT, श्रेणियों के संयोजन के लिए VSTACK और HSTACK, और पिवट तालिकाओं को पूरी तरह से छोड़ने के लिए PIVOTBY और GROUPBY। प्रत्येक रिलीज़ एक और आदत को रिटायर करती प्रतीत होती है, जो मेरे लिए ठीक है।