Apple कुछ महीनों से छोटी गाड़ी चला रहा है। अब हमें iPhones में टेक्स्ट-रेंडरिंग कार्यक्षमता में एक नया, गंभीर बग मिला है। बग को एक एकल तेलुगु वर्ण द्वारा ट्रिगर किया जाता है जो एक iPhone को केवल चरित्र युक्त एक सूचना प्राप्त करके एक अटूट बूट लूप में प्रवेश करने का कारण बन सकता है। आइए देखें कि एक ही चरित्र आईओएस के साथ इतनी बड़ी समस्या क्यों पैदा कर सकता है।
नोट: तेलुगू बग का समाधान iOS के नवीनतम संस्करण (11.2.6) में उपलब्ध है। यदि तेलुगु चरित्र ने आपके ऐप या डिवाइस को लॉक कर दिया है, तो अपने iPhone को iTunes के माध्यम से पुनर्स्थापित करें और iOS के नवीनतम संस्करण में अपडेट करें। यदि आपका iPhone बूट लूप में फंस गया है, तो आपको इसे पहचानने के लिए iTunes प्राप्त करने के लिए इसे डिवाइस फ़र्मवेयर अपडेट (DFU) स्थिति में रखना पड़ सकता है। समाप्त होने पर, अपने डिवाइस को अपने नवीनतम बैकअप से पुनर्स्थापित करें, जिसे आपने उम्मीद के मुताबिक बनाया था।
तेलुगु क्या है?
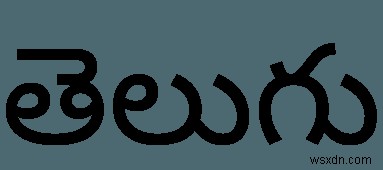
तेलुगु भारत के कुछ हिस्सों, विशेष रूप से आंध्र प्रदेश, तेलंगाना और यनम शहर में बोली और लिखी जाने वाली भाषा है। कई स्क्रिप्ट-आधारित भाषाओं की तरह, जैसे कि अरबी और अन्य ब्राह्मी लिपियों, तेलुगु अपने वर्णों को कंप्यूटर स्क्रीन पर प्रदर्शित करने के लिए यूनिकोड वर्ण सेट की कुछ विशेष विशेषताओं का उपयोग करता है।
जबकि अधिकांश लैटिन अक्षरों को ASCII संगतता के लिए एकल 8-बिट यूनिकोड कोड बिंदु द्वारा दर्शाया जाता है (उदाहरण के लिए, अक्षर A यूनिकोड कोड बिंदु पर मौजूद है U+0041 , जिसे बाइनरी में 01000001 . द्वारा दर्शाया जाता है ), लिपि या गैर-लैटिन अक्षरों से लिखी जाने वाली भाषाएं आमतौर पर अपने वर्णों का प्रतिनिधित्व करने के लिए एक से अधिक यूनिकोड कोड बिंदुओं को जोड़ती हैं।
यह तेलुगु जैसी भाषाओं के लिए विशेष रूप से सच है, जो भाषाओं के अक्षरों के संस्करणों को समूहों में जोड़ती है। अंग्रेजी के शैलीगत संयुक्ताक्षरों के विपरीत, प्रत्येक तेलुगु अक्षर के बीच का संबंध भाषाई रूप से महत्वपूर्ण है। इसे समायोजित करने के लिए, यूनिकोड में वर्णों को जोड़ने की एक जटिल प्रणाली शामिल है, प्रत्येक को अपने स्वयं के कोड बिंदु द्वारा एक दूसरे से दर्शाया जाता है।
यूनिकोड कोड बिंदुओं की विशाल संख्या को ध्यान में रखते हुए, यह लगभग अनंत विविधता बना सकता है। ये बिंदु एक साथ मिलकर एक सुपाठ्य चरित्र प्रस्तुत करते हैं। इस तरह यूनिकोड को हर संभव तेलुगु शब्द के लिए यूनिकोड कोड बिंदु की आवश्यकता नहीं है। इसके बजाय, यूनिकोड तेलुगु व्यंजन, स्वर और विशेषक ("विरामा") को मिलाकर ऐसे शब्द बनाता है जो एकल वर्ण की तरह प्रदर्शित होते हैं। यही बात अन्य भाषाओं पर भी लागू होती है, जिनमें अरबी जैसे संयुक्ताक्षरों के लिए वर्तनी संबंधी नियम होते हैं।
दुर्घटना का कारण क्या है?

समस्या कोड बिंदु U+200C पर शून्य चौड़ाई गैर-जोइनर (ZWNJ) से संबंधित प्रतीत होती है . ZWNJ अनुरोध करता है कि दो आसन्न वर्ण अपने विशिष्ट संयुक्ताक्षर के बिना प्रस्तुत करें। अंग्रेजी में, एक ZWNJ प्रत्येक f को अलग करने के बजाय, ff को उनके मानक कनेक्शन लिगचर के साथ मुद्रित होने से रोकता है। लेकिन जब चार तेलुगु कोड बिंदुओं के एक विशिष्ट सेट (जिनमें से सभी को एक ही क्लस्टर में संयोजित किया जाना चाहिए) के साथ जोड़ा जाता है, तो किसी कारण से iOS ठीक से परिणाम प्रदर्शित नहीं कर सकता है।
कुछ लोगों ने अनुमान लगाया है कि ऐप्पल का सैन फ्रांसिस्को फ़ॉन्ट चरित्र प्रदर्शित नहीं कर सकता है, जबकि अन्य ने कहा है कि ऐप्पल द्वारा उपयोग की जाने वाली विशिष्ट प्रतिपादन प्रक्रिया को दोष देना है। सटीक कारण जो भी हो, चरित्र को प्रस्तुत करने का प्रयास संदेश और व्हाट्सएप से लेकर स्प्रिंगबोर्ड तक, जो कुछ भी इसे प्रस्तुत कर रहा है, एक नाटकीय दुर्घटना का कारण बनता है। यूनिकोड कोड बिंदु जो वर्ण बनाते हैं ("ज्ञा" जिसका अर्थ है "ज्ञान") नीचे हैं:
U+0C1Cजा (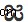 )
)U+0C4Dएक विरामा, या विशेषक चिह्न (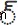 )
)U+0C1Eन्याय (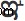 )
)U+200Cशून्य चौड़ाई वाले गैर-जुड़ने वालेU+0C3Eआ (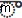 )
)
लेकिन हम अकेले जीरो विड्थ नॉन-जॉइनर (ZWNJ) को भी दोष नहीं दे सकते। यह बिना किसी समस्या के सहज पारिवारिक इमोजी (????) में भी उपयोग किया जाता है। यह कुछ विशिष्ट कोड बिंदुओं और ZWNJ का एक विशिष्ट संयोजन प्रतीत होता है। चोट के अपमान को जोड़ते हुए, ऐसा लगता है कि ZWNJ का या तो इस तेलुगु क्लस्टर पर प्रतिपादन पर कोई विशेष प्रभाव नहीं है या यह पहले स्थान पर भी नहीं होना चाहिए।
अन्य ब्राह्मी स्क्रिप्ट समस्याएं
हालाँकि, इस मुद्दे के साथ तेलुगु एकमात्र भाषा नहीं है। बंगाली और देवनागरी, जो अपनी ब्राह्मी लिपियों के लिए एक समान तरीके से यूनिकोड का उपयोग करते हैं, उनकी भी यही समस्या है। मनीष गोरेगांवकर एक आकर्षक और विस्तृत ब्लॉग पोस्ट लिखते हैं जो सटीक दुर्घटना मामले को और भी नीचे तोड़ता है:
<ब्लॉकक्वॉट>
कोई भी क्रम <consonant1, virama, consonant2, ZWNJ, vowel> देवनागरी, बंगाली और तेलुगु में, जहां:
1. consonant2 प्रत्यय-जुड़ना है (pstf /vatu )
2. consonant1 रेफ बनाने वाला पत्र नहीं है
3. vowel दो ग्लिफ़ घटक नहीं हैं
निष्कर्ष:इसे Apple ने क्यों नहीं पकड़ा?
यह समझने के लिए कि यह बग कैसे हुआ, आपको खुद को Apple के जूते में रखना होगा। निश्चित रूप से, यह चरित्र संयोजन तेलुगु भाषा में कुछ सुपर अस्पष्ट शब्द नहीं है। लेकिन iPhone में दर्जनों भाषाओं का समर्थन शामिल है। यूनिकोड में सचमुच अरबों संभावित संयोजन हैं। इतनी विविधता के साथ, रिलीज़ से पहले यूनिकोड बग के लिए सार्थक परीक्षण नियमित सॉफ़्टवेयर अपडेट को मूल रूप से असंभव बना देगा।
हालाँकि, त्रुटि से इतना नुकसान नहीं होना चाहिए था। पाठ संदेश की सामग्री के आधार पर फ़ोनों को ब्रिक नहीं किया जाना चाहिए। जबकि पिछली दृष्टि निश्चित रूप से 20/20 है, ऐसा लगता है कि चरित्र को एक प्रश्न चिह्न बॉक्स (�) के रूप में प्रस्तुत करना स्प्रिंगबोर्ड को क्रैश करने से बेहतर होगा।