एक कनवल्शनल न्यूरल नेटवर्क के निर्माण से लेकर iOS पर एक OCR परिनियोजित करने तक
परियोजना के लिए प्रेरणा ✍️ ??
जब मैं कुछ महीने पहले एमएनआईएसटी डेटासेट के लिए गहन शिक्षण मॉडल बनाना सीख रहा था, तब मैंने एक आईओएस ऐप बनाया जो हस्तलिखित वर्णों को पहचानता था।
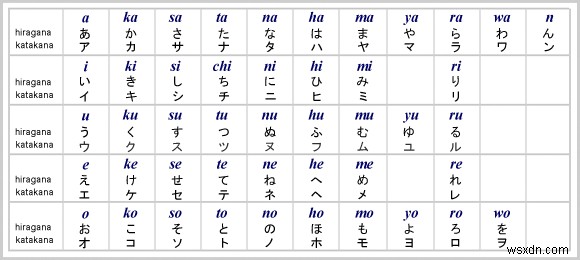
मेरा दोस्त कैची मोमोज एक जापानी भाषा सीखने वाला ऐप नुकॉन विकसित कर रहा था। संयोग से वह इसमें एक समान विशेषता रखना चाहते थे। इसके बाद हमने अंक पहचानकर्ता की तुलना में कुछ अधिक परिष्कृत बनाने के लिए सहयोग किया:जापानी पात्रों (हीरागाना और कटकाना) के लिए एक ओसीआर (ऑप्टिकल कैरेक्टर रिकॉग्निशन/रीडर)।
नुकॉन के विकास के दौरान, जापानी में हस्तलेखन पहचान के लिए कोई एपीआई उपलब्ध नहीं था। हमारे पास अपना ओसीआर बनाने के अलावा कोई विकल्प नहीं था। स्क्रैच से एक के निर्माण से हमें जो सबसे बड़ा लाभ मिला, वह यह था कि हमारा ऑफ़लाइन काम करता है। उपयोगकर्ता इंटरनेट के बिना पहाड़ों में गहरे हो सकते हैं और फिर भी जापानी सीखने की अपनी दैनिक दिनचर्या को बनाए रखने के लिए नुकॉन को खोल सकते हैं। हमने पूरी प्रक्रिया के दौरान बहुत कुछ सीखा, लेकिन इससे भी महत्वपूर्ण बात यह है कि हम अपने उपयोगकर्ताओं के लिए एक बेहतर उत्पाद शिप करने के लिए रोमांचित थे।
यह लेख इस प्रक्रिया को तोड़ देगा कि हमने iOS ऐप्स के लिए जापानी OCR कैसे बनाया। उन लोगों के लिए जो अन्य भाषाओं/प्रतीकों के लिए एक बनाना चाहते हैं, बेझिझक डेटासेट बदलकर इसे कस्टमाइज़ करें।
आगे की हलचल के बिना, आइए एक नजर डालते हैं कि इसमें क्या शामिल होगा:
भाग 1️⃣:डेटासेट और प्रीप्रोसेस इमेज प्राप्त करें
भाग 2️⃣:सीएनएन (कन्वेंशनल न्यूरल नेटवर्क) का निर्माण और प्रशिक्षण करें
भाग 3️⃣:प्रशिक्षित मॉडल को iOS में एकीकृत करें
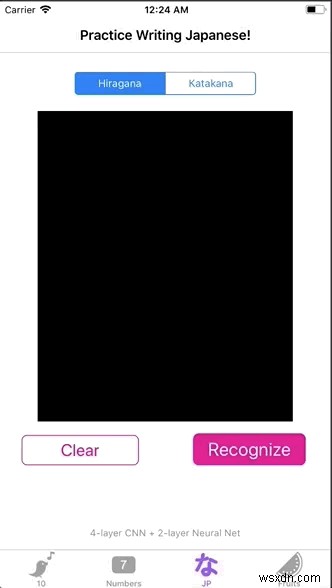
डेटासेट और प्रीप्रोसेस छवियां प्राप्त करें?
डेटासेट ईटीएल कैरेक्टर डेटाबेस से आता है, जिसमें हस्तलिखित पात्रों और प्रतीकों की छवियों के नौ सेट होते हैं। चूँकि हम हीरागाना के लिए एक OCR बनाने जा रहे हैं, ETL8 वह डेटासेट है जिसका हम उपयोग करेंगे।
डेटाबेस से छवियों को प्राप्त करने के लिए, हमें कुछ सहायक कार्यों की आवश्यकता होती है जो छवियों को .npz . में पढ़ते और संग्रहीत करते हैं प्रारूप।
import struct
import numpy as np
from PIL import Image
sz_record = 8199
def read_record_ETL8G(f):
s = f.read(sz_record)
r = struct.unpack('>2H8sI4B4H2B30x8128s11x', s)
iF = Image.frombytes('F', (128, 127), r[14], 'bit', 4)
iL = iF.convert('L')
return r + (iL,)
def read_hiragana():
# Type of characters = 70, person = 160, y = 127, x = 128
ary = np.zeros([71, 160, 127, 128], dtype=np.uint8)
for j in range(1, 33):
filename = '../../ETL8G/ETL8G_{:02d}'.format(j)
with open(filename, 'rb') as f:
for id_dataset in range(5):
moji = 0
for i in range(956):
r = read_record_ETL8G(f)
if b'.HIRA' in r[2] or b'.WO.' in r[2]:
if not b'KAI' in r[2] and not b'HEI' in r[2]:
ary[moji, (j - 1) * 5 + id_dataset] = np.array(r[-1])
moji += 1
np.savez_compressed("hiragana.npz", ary)
एक बार हमारे पास hiragana.npz सहेजा गया है, आइए फ़ाइल लोड करके और छवि आयामों को 32x32 पिक्सेल में पुनः आकार देकर छवियों को संसाधित करना प्रारंभ करें . हम अतिरिक्त छवियों को उत्पन्न करने के लिए डेटा वृद्धि भी जोड़ेंगे जिन्हें घुमाया और ज़ूम किया गया है। जब हमारे मॉडल को विभिन्न कोणों से चरित्र छवियों पर प्रशिक्षित किया जाता है, तो हमारा मॉडल लोगों की लिखावट को बेहतर ढंग से अपना सकता है।
import scipy.misc
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.models import Sequential
from keras.preprocessing.image import ImageDataGenerator
from keras.utils import np_utils
from sklearn.model_selection import train_test_split
# 71 characters
nb_classes = 71
# input image dimensions
img_rows, img_cols = 32, 32
ary = np.load("hiragana.npz")['arr_0'].reshape([-1, 127, 128]).astype(np.float32) / 15
X_train = np.zeros([nb_classes * 160, img_rows, img_cols], dtype=np.float32)
for i in range(nb_classes * 160):
X_train[i] = scipy.misc.imresize(ary[i], (img_rows, img_cols), mode='F')
y_train = np.repeat(np.arange(nb_classes), 160)
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)
# convert class vectors to categorical matrices
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
# data augmentation
datagen = ImageDataGenerator(rotation_range=15, zoom_range=0.20)
datagen.fit(X_train)सीएनएन का निर्माण और प्रशिक्षण ?️
अब मज़ा भाग में आता है! हम अपने मॉडल के लिए सीएनएन (कन्वेंशनल न्यूरल नेटवर्क) के निर्माण के लिए केरस का उपयोग करेंगे। जब मैंने पहली बार मॉडल बनाया, तो मैंने हाइपर-पैरामीटर के साथ प्रयोग किया और उन्हें कई बार ट्यून किया। नीचे दिए गए संयोजन ने मुझे उच्चतम सटीकता दी - 98.77%। बेझिझक अलग-अलग मापदंडों के साथ खुद खेलें।
model = Sequential()
def model_6_layers():
model.add(Conv2D(32, 3, 3, input_shape=input_shape))
model.add(Activation('relu'))
model.add(Conv2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(Conv2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
model_6_layers()
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
model.fit_generator(datagen.flow(X_train, y_train, batch_size=16),
samples_per_epoch=X_train.shape[0],
nb_epoch=30, validation_data=(X_test, y_test))यदि आपको मॉडल का प्रदर्शन असंतोषजनक मिलता है, तो यहां कुछ युक्तियां दी गई हैं प्रशिक्षण चरण में:
मॉडल ओवरफिटिंग है
इसका मतलब है कि मॉडल अच्छी तरह से सामान्यीकृत नहीं है। सहज व्याख्या के लिए इस लेख को देखें।
ओवरफिटिंग का पता कैसे लगाएं :acc (सटीकता) ऊपर जाना जारी है, लेकिन val_acc (सत्यापन सटीकता) प्रशिक्षण प्रक्रिया में इसके विपरीत करता है।
ओवरफिटिंग के कुछ उपाय :नियमितीकरण (उदा. ड्रॉपआउट), डेटा वृद्धि, डेटासेट की गुणवत्ता में सुधार
कैसे पता करें कि मॉडल "लर्निंग" है या नहीं
मॉडल सीख नहीं रहा है अगर val_loss (सत्यापन हानि) प्रशिक्षण के चलने के साथ बढ़ता या घटता नहीं है।
TensorBoard का उपयोग करें - यह समय के साथ मॉडल के प्रदर्शन के लिए विज़ुअलाइज़ेशन प्रदान करता है। यह हर एक युग को देखने और लगातार मूल्यों की तुलना करने के थकाऊ काम से छुटकारा दिलाता है।
चूंकि हम अपनी सटीकता से संतुष्ट हैं, इसलिए वजन और मॉडल कॉन्फ़िगरेशन को फ़ाइल के रूप में सहेजने से पहले हम ड्रॉपआउट परतों को हटा देते हैं।
for k in model.layers:
if type(k) is keras.layers.Dropout:
model.layers.remove(k)
model.save('hiraganaModel.h5')
IOS भाग पर जाने से पहले केवल एक ही कार्य बचा है hiraganaModel.h5 CoreML मॉडल के लिए।
import coremltools
output_labels = [
'あ', 'い', 'う', 'え', 'お',
'か', 'く', 'こ', 'し', 'せ',
'た', 'つ', 'と', 'に', 'ね',
'は', 'ふ', 'ほ', 'み', 'め',
'や', 'ゆ', 'よ', 'ら', 'り',
'る', 'わ', 'が', 'げ', 'じ',
'ぞ', 'だ', 'ぢ', 'づ', 'で',
'ど', 'ば', 'び',
'ぶ', 'べ', 'ぼ', 'ぱ', 'ぴ',
'ぷ', 'ぺ', 'ぽ',
'き', 'け', 'さ', 'す', 'そ',
'ち', 'て', 'な', 'ぬ', 'の',
'ひ', 'へ', 'ま', 'む', 'も',
'れ', 'を', 'ぎ', 'ご', 'ず',
'ぜ', 'ん', 'ぐ', 'ざ', 'ろ']
scale = 1/255.
coreml_model = coremltools.converters.keras.convert('./hiraganaModel.h5',
input_names='image',
image_input_names='image',
output_names='output',
class_labels= output_labels,
image_scale=scale)
coreml_model.author = 'Your Name'
coreml_model.license = 'MIT'
coreml_model.short_description = 'Detect hiragana character from handwriting'
coreml_model.input_description['image'] = 'Grayscale image containing a handwritten character'
coreml_model.output_description['output'] = 'Output a character in hiragana'
coreml_model.save('hiraganaModel.mlmodel')
output_labels ये सभी संभावित आउटपुट हैं जिन्हें हम बाद में iOS में देखेंगे।
मजेदार तथ्य:यदि आप जापानी समझते हैं, तो आप जान सकते हैं कि आउटपुट वर्णों का क्रम हीरागाना के "वर्णमाला क्रम" से मेल नहीं खाता है। हमें यह महसूस करने में कुछ समय लगा कि ETL8 में छवियां "वर्णमाला क्रम" में नहीं थीं (इसे महसूस करने के लिए काइची को धन्यवाद)। डेटासेट एक जापानी विश्वविद्यालय द्वारा संकलित किया गया था, हालांकि…?
प्रशिक्षित मॉडल को iOS में एकीकृत करें?
हम अंत में सब कुछ एक साथ रख रहे हैं! खींचें और छोड़ें hiraganaModel.mlmodel एक एक्सकोड परियोजना में। फिर आपको कुछ इस तरह दिखाई देगा:
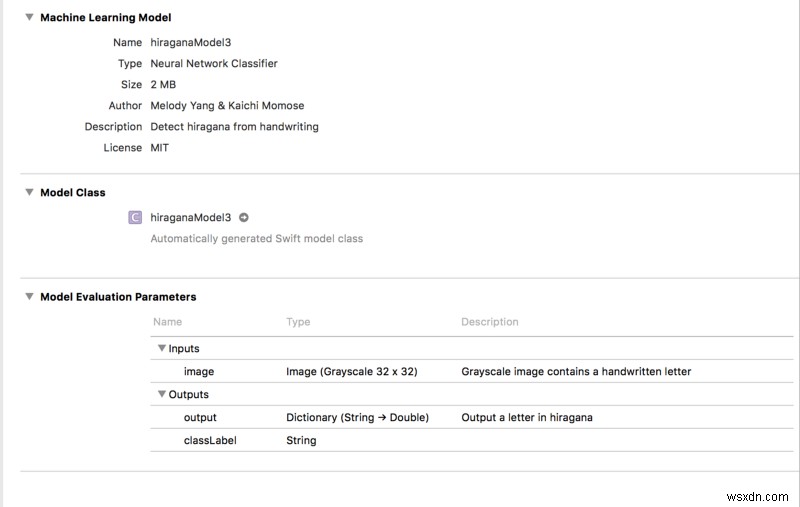
नोट :मॉडल को कॉपी करने पर Xcode एक कार्यक्षेत्र बनाएगा। हमें अपने कोडिंग परिवेश को कार्यस्थान . पर स्विच करने की आवश्यकता है अन्यथा एमएल मॉडल काम नहीं करेगा!
अंतिम लक्ष्य हमारे हीरागाना मॉडल को एक छवि में पारित करके एक चरित्र की भविष्यवाणी करना है। इसे प्राप्त करने के लिए, हम एक साधारण यूआई बनाएंगे ताकि उपयोगकर्ता लिख सके, और हम उपयोगकर्ता के लेखन को एक छवि प्रारूप में संग्रहीत करेंगे। अंत में, हम छवि के पिक्सेल मानों को पुनः प्राप्त करते हैं और उन्हें अपने मॉडल में फीड करते हैं।
आइए इसे चरण दर चरण करते हैं:
UIViewपर वर्ण "ड्रा" करेंUIBezierPath. के साथ
import UIKit
class viewController: UIViewController {
@IBOutlet weak var canvas: UIView!
var path = UIBezierPath()
var startPoint = CGPoint()
var touchPoint = CGPoint()
override func viewDidLoad() {
super.viewDidLoad()
canvas.clipsToBounds = true
canvas.isMultipleTouchEnabled = true
}
override func touchesBegan(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
startPoint = point
}
}
override func touchesMoved(_ touches: Set<UITouch>, with event: UIEvent?) {
let touch = touches.first
if let point = touch?.location(in: canvas) {
touchPoint = point
}
path.move(to: startPoint)
path.addLine(to: touchPoint)
startPoint = touchPoint
draw()
}
func draw() {
let strokeLayer = CAShapeLayer()
strokeLayer.fillColor = nil
strokeLayer.lineWidth = 8
strokeLayer.strokeColor = UIColor.orange.cgColor
strokeLayer.path = path.cgPath
canvas.layer.addSublayer(strokeLayer)
}
// clear the drawing in view
@IBAction func clearPressed(_ sender: UIButton) {
path.removeAllPoints()
canvas.layer.sublayers = nil
canvas.setNeedsDisplay()
}
}
strokeLayer.strokeColor कोई भी रंग हो सकता है। हालांकि, canvas . का बैकग्राउंड कलर काला . होना चाहिए . हालांकि हमारी प्रशिक्षण छवियों में एक सफेद पृष्ठभूमि और काले स्ट्रोक होते हैं, एमएल मॉडल इस शैली के साथ एक इनपुट छवि पर अच्छी तरह से प्रतिक्रिया नहीं करता है।
2. मुड़ें UIView UIImage . में और CVPixelBuffer के साथ पिक्सेल मान प्राप्त करें
विस्तार में, दो सहायक कार्य हैं। साथ में, वे छवियों का एक पिक्सेल बफर में अनुवाद करते हैं, जो पिक्सेल मानों के बराबर है। इनपुट width और height दोनों 32 . होने चाहिए चूंकि हमारे मॉडल के इनपुट आयाम 32 गुणा 32 पिक्सेल हैं।
जैसे ही हमारे पास pixelBuffer . होता है , हम model.prediction() . पर कॉल कर सकते हैं और pixelBuffer . में पास करें . और वहाँ हम जाते हैं! हमारे पास classLabel . का आउटपुट हो सकता है !
@IBAction func recognizePressed(_ sender: UIButton) {
// Turn view into an image
let resultImage = UIImage.init(view: canvas)
let pixelBuffer = resultImage.pixelBufferGray(width: 32, height: 32)
let model = hiraganaModel3()
// output a Hiragana character
let output = try? model.prediction(image: pixelBuffer!)
print(output?.classLabel)
}
extension UIImage {
// Resizes the image to width x height and converts it to a grayscale CVPixelBuffer
func pixelBufferGray(width: Int, height: Int) -> CVPixelBuffer? {
return _pixelBuffer(width: width, height: height,
pixelFormatType: kCVPixelFormatType_OneComponent8,
colorSpace: CGColorSpaceCreateDeviceGray(),
alphaInfo: .none)
}
func _pixelBuffer(width: Int, height: Int, pixelFormatType: OSType,
colorSpace: CGColorSpace, alphaInfo: CGImageAlphaInfo) -> CVPixelBuffer? {
var maybePixelBuffer: CVPixelBuffer?
let attrs = [kCVPixelBufferCGImageCompatibilityKey: kCFBooleanTrue,
kCVPixelBufferCGBitmapContextCompatibilityKey: kCFBooleanTrue]
let status = CVPixelBufferCreate(kCFAllocatorDefault,
width,
height,
pixelFormatType,
attrs as CFDictionary,
&maybePixelBuffer)
guard status == kCVReturnSuccess, let pixelBuffer = maybePixelBuffer else {
return nil
}
CVPixelBufferLockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
let pixelData = CVPixelBufferGetBaseAddress(pixelBuffer)
guard let context = CGContext(data: pixelData,
width: width,
height: height,
bitsPerComponent: 8,
bytesPerRow: CVPixelBufferGetBytesPerRow(pixelBuffer),
space: colorSpace,
bitmapInfo: alphaInfo.rawValue)
else {
return nil
}
UIGraphicsPushContext(context)
context.translateBy(x: 0, y: CGFloat(height))
context.scaleBy(x: 1, y: -1)
self.draw(in: CGRect(x: 0, y: 0, width: width, height: height))
UIGraphicsPopContext()
CVPixelBufferUnlockBaseAddress(pixelBuffer, CVPixelBufferLockFlags(rawValue: 0))
return pixelBuffer
}
}
3. आउटपुट को UIAlertController . के साथ दिखाएं
यह कदम पूरी तरह से वैकल्पिक है। जैसा कि शुरुआत में GIF में दिखाया गया है, मैंने परिणाम की सूचना देने के लिए एक अलर्ट कंट्रोलर जोड़ा है।
func informResultPopUp(message: String) {
let alertController = UIAlertController(title: message,
message: nil,
preferredStyle: .alert)
let ok = UIAlertAction(title: "Ok", style: .default, handler: { action in
self.dismiss(animated: true, completion: nil)
})
alertController.addAction(ok)
self.present(alertController, animated: true) { () in
}
}वोइला! हमने अभी एक ओसीआर बनाया है जो डेमो-रेडी (और ऐप-स्टोर-रेडी) है! ??
निष्कर्ष ?
OCR बनाना इतना कठिन नहीं है। जैसा कि आपने देखा, इस लेख में चरणों और समस्याओं का समावेश है और मैं इस परियोजना के निर्माण के दौरान भाग गया। मैंने पायथन कोड के एक समूह को आईओएस के साथ जोड़कर प्रदर्शित करने योग्य बनाने की प्रक्रिया का आनंद लिया, और मैं इसे जारी रखने का इरादा रखता हूं।
मुझे उम्मीद है कि यह लेख उन लोगों के लिए कुछ उपयोगी जानकारी प्रदान करता है जो ओसीआर बनाना चाहते हैं लेकिन यह नहीं जानते कि कहां से शुरू करें।
आपको स्रोत कोड . मिल सकता है यहां.
बोनस :यदि आप उथले एल्गोरिदम के साथ प्रयोग करने में रुचि रखते हैं, तो पढ़ते रहें!
[Optional] उथले एल्गोरिथम वाली ट्रेन ?
सीएनएन को लागू करने से पहले, कैची और मैंने यह पता लगाने के लिए अन्य मशीन लर्निंग एल्गोरिदम का परीक्षण किया कि क्या वे काम पूरा कर सकते हैं (और हमें कुछ कंप्यूटिंग लागत बचा सकते हैं!) हमने केएनएन और रैंडम फ़ॉरेस्ट को चुना।
उनके प्रदर्शन का मूल्यांकन करने के लिए, हमने अपनी आधारभूत सटीकता को 1/71 =0.014 के रूप में परिभाषित किया है।
हमने यह मान लिया था कि जापानी भाषा के ज्ञान के बिना किसी व्यक्ति के चरित्र का सही अनुमान लगाने की 1.4% संभावना हो सकती है।
इस प्रकार, मॉडल अच्छा प्रदर्शन कर रहा होगा यदि इसकी सटीकता 1.4% से अधिक हो सकती है। आइए देखें कि क्या ऐसा था। ?
केएनएन
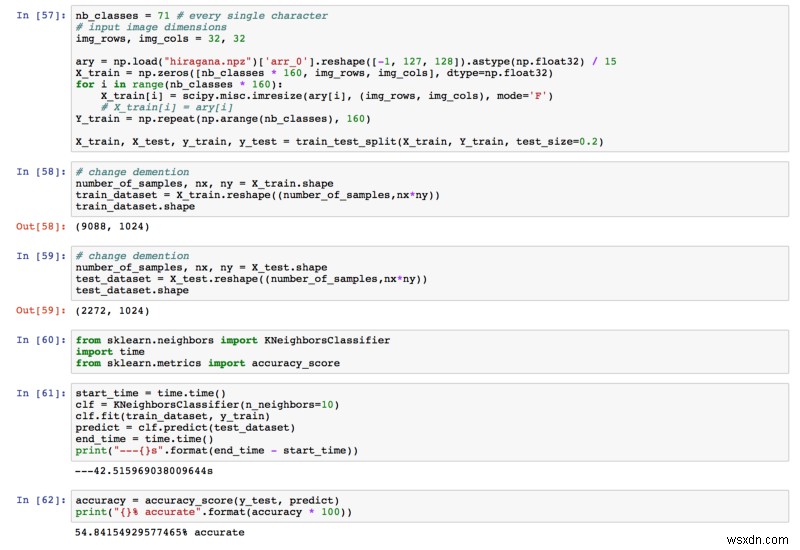
हमें मिली अंतिम सटीकता 54.84% थी। पहले से ही 1.4% से बहुत अधिक!
रैंडम फ़ॉरेस्ट
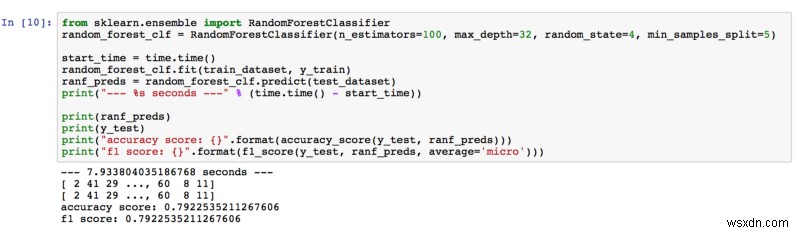
79.23% की सटीकता, इसलिए रैंडम फ़ॉरेस्ट हमारी अपेक्षाओं को पार कर गया। हाइपर-पैरामीटर को ट्यून करते समय, हमें अनुमानकों की संख्या और पेड़ों की गहराई में वृद्धि करके बेहतर परिणाम मिले। हमने सोचा कि जंगल में अधिक पेड़ (अनुमानकर्ता) होने का मतलब है कि छवि में अधिक विशेषताएं सीखी गईं। साथ ही, पेड़ जितना गहरा होता है, उतना ही अधिक विवरण वह विशेषताओं से सीखता है।
यदि आप और अधिक सीखने में रुचि रखते हैं, तो मुझे यह पेपर मिला है जो रैंडम फ़ॉरेस्ट के साथ छवि वर्गीकरण पर चर्चा करता है।
पढ़ने के लिए धन्यवाद। किसी भी विचार और प्रतिक्रिया का स्वागत है!