जब आप Google क्रोम के माध्यम से किसी साइट तक पहुंचने का प्रयास करते हैं, जो आपको यह पुष्टि करने के लिए कहता है कि आप इंसान हैं या नहीं, तो पॉप-अप दिखाई देने वाले पॉप-अप के कारण हम में से बहुत से लोग नाराज और परेशान महसूस करते हैं। एक बार के लिए यह पूछना सबसे बेवकूफी भरा लगता है, खासकर अगर यह आपके चेहरे पर बार-बार उभर रहा हो। वह कैप्चा है, एक चुनौती-प्रतिक्रिया परीक्षण जो ब्राउज़र को यह निर्धारित करने की अनुमति देता है कि यह कोई मशीन नहीं है जो आपकी व्यक्तिगत खोजों में आने की कोशिश कर रही है। स्पैम बॉट को इंटरनेट से दूर रखने और दुरुपयोग को रोकने के लिए कैप्चा एक सामान्य सुरक्षात्मक उपाय बन गया है। लेकिन हाल के वर्षों में, कैप्चा का विस्तार किया गया है और यह एक जटिल कार्य भी बन गया है जिसके लिए हमें तथाकथित प्रतिक्रिया चुनौती पर ध्यान केंद्रित करने की आवश्यकता है। आपका ब्राउज़र आपसे "मैं रोबोट नहीं हूँ" की पुष्टि करने के लिए क्यों कह रहा है? और कैसे यह सिर्फ एक कष्टप्रद और समय लेने वाली चुनौती में परिवर्तित हो गया? पढ़ें कि कैसे स्पैमबॉट्स को हटाने के लिए एक उपकरण के रूप में शुरू हुआ कुछ, अब इंसानों और मशीनों के बीच एक भीषण दौड़ बन गया है।
कैप्चा क्या है?
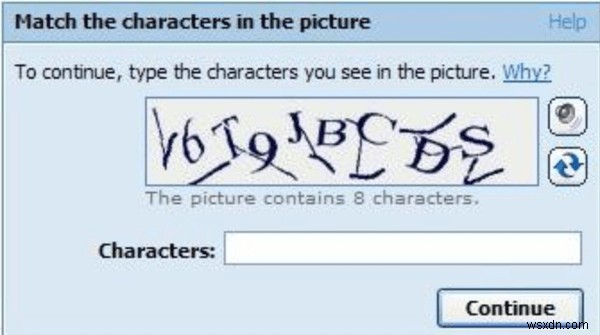
CAPTCHA का मतलब पूरी तरह से स्वचालित सार्वजनिक ट्यूरिंग टेस्ट है। इसे 2000 के दशक की शुरुआत में मनुष्यों के लिए एक परीक्षण के रूप में विकसित किया गया था ताकि यह साबित किया जा सके कि वे मशीन या स्पैम बॉट नहीं हैं जो ब्राउज़र सुरक्षा को भंग करने की कोशिश कर रहे हैं। हालांकि कैप्चा का आविष्कार एक और बहस का विषय है, इसका सबसे पुराना संस्करण 1997 का है। जब इसका पहली बार उपयोग किया गया था, तो कैप्चा सरल पाठ में विकृत अक्षरों का एक क्रम टाइप करके उपयोगकर्ताओं से अपनी "मानवता" साबित करने के लिए कहता था। कुछ अनुक्रमों में, विकृत अक्षरों को समान विकृत प्रारूप में लिखी गई संख्याओं द्वारा संयोजित किया गया था। इन अक्षरों को इस तरह से लिखा गया था कि उनके बीच कोई जगह नहीं लग रही थी और हर लॉगिन प्रयास पर कोड बदल दिया गया था। ऐसा इसलिए किया गया क्योंकि, लगभग अनंत संख्या में विकृत अनुक्रमों को डिकोड करने के लिए, कुछ मानव बुद्धि की हमेशा आवश्यकता होगी; जबकि, एक कंप्यूटर मशीन एल्गोरिथम विकृत अनुक्रमों का पता नहीं लगा सकता है। इस प्रकार, कई वेब और मेल सेवा प्रदाताओं द्वारा कैप्चा को तुरंत अपनाया गया।
लेकिन फिर अगले कुछ वर्षों में, CAPTCHA जटिल हो गया।
Google का reCAPTCHA:मूल परीक्षण के लिए एक जटिल अपग्रेड
2007 में, Google ने सिस्टम के मूल शोधकर्ताओं के एक समूह से reCAPTCHA नामक कार्यक्रम खरीदा और Google विद्वान और Google पुस्तकें में इसका व्यापक रूप से उपयोग करना शुरू कर दिया। लेकिन, जहां से इसकी शुरुआत हुई थी, इस नवीनतम रूप में CAPTCHA Google उपयोगकर्ताओं के लिए सिरदर्द बन गया। जैसे-जैसे मशीन लर्निंग पर शोध बढ़ता गया, वैसे-वैसे जटिल समस्याओं को हल करने के लिए कंप्यूटिंग सिस्टम और उनके एल्गोरिदम की क्षमता भी बढ़ती गई। इस प्रकार, बॉट्स और मशीनों को हल करने के लिए मूल चरित्र अनुक्रम बहुत आसान हो गए। इसलिए, Google ने आगे बढ़कर उन पात्रों को और अधिक मोड़ दिया और तकनीकी रूप से मानवीय आंखों के लिए अधिक भ्रमित कर दिया। इसने वास्तव में मानव और मशीन इंटेलिजेंस के बीच वास्तविक दौड़ शुरू की, जो वास्तविक झुंझलाहट में परिवर्तित हो गई reCAPTCHA Google उपयोगकर्ताओं के लिए बन गई। यह सुनिश्चित करने के लिए कि Google प्लेटफ़ॉर्म और खोजों तक पहुँचने वाला उपयोगकर्ता कोई बॉट नहीं है, Google ने अनुक्रमों को हल करना अधिक कठिन बना दिया है।
छवियों को परीक्षण में जोड़ना:Google का कोई CAPTCHA reCAPTCHA नहीं
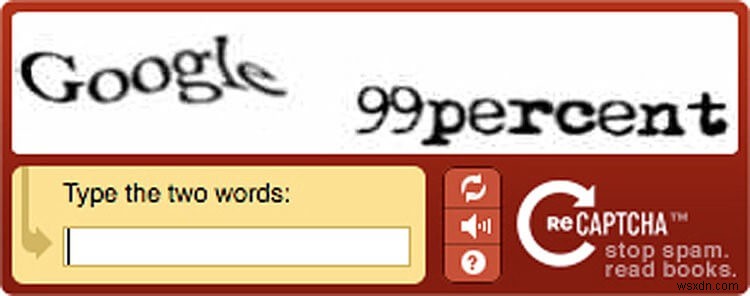
2014 में, Google द्वारा reCaptcha का अधिग्रहण करने के बहुत बाद में, इसने उपयोगकर्ताओं को परेशान करने वाली झुंझलाहट पर कार्रवाई करने का निर्णय लिया। साथ ही, इन सभी वर्षों में, शोधकर्ताओं ने एक बार फिर स्मार्ट मशीन बनाने के लिए प्रतिक्रिया चुनौतियों को समझने की रीकैप्चा की क्षमताओं को पीछे छोड़ दिया है। एक प्रयोगात्मक परीक्षण में, Google शोधकर्ताओं ने निर्धारित किया कि अत्यधिक जटिलताओं और कष्टप्रद पॉपअप के बावजूद, मशीन लर्निंग एल्गोरिदम 99 प्रतिशत से अधिक प्रतिक्रियाओं को सही ढंग से प्राप्त करने में सक्षम थे, जबकि हम इंसानों ने मुश्किल से 33 प्रतिशत का प्रबंधन किया था। तो, यह बदलाव का समय था।

Google ने उपयोगकर्ताओं की झुंझलाहट को दूर करने का फैसला किया। नया "नोकैप्चा रीकैप्चा" उपयोगकर्ताओं को केवल टिक बॉक्स पर क्लिक करके परीक्षा पास करने की अनुमति देता है। इस बार Google ने एपीआई तकनीक के साथ बहुत आगे बढ़कर उपयोगकर्ता की प्राथमिकताओं का उपयोग यह निर्धारित करने के लिए किया कि यह मानव है या रोबोट। Google के नए reCAPTCHA ने उपयोगकर्ता खोजों के साथ-साथ माउस कर्सर की गति का विश्लेषण किया। एक बॉट एक बॉट के लिए माउस क्लिक का अनुकरण नहीं कर सकता है, उस विशेष कैप्चा परीक्षण के लिए कोड का विश्लेषण करने से वह वर्चुअल टिक बॉक्स ग्राफिक छवि के रूप में दिखाई देगा, और उस पर प्रतिक्रिया नहीं देगा। लेकिन फिर, अगर कोई बॉट जावास्क्रिप्ट पढ़ सकता है, तो वह आसानी से उसका अनुकरण कर सकता है और माउस मूवमेंट ट्रैकिंग विकल्प विफल हो जाएगा।
तो आप उस मुद्दे को कैसे ठीक करते हैं? और, क्या होगा यदि आपने अपनी प्राथमिकताओं से भिन्न खोज की है?

खैर, उस मामले में, एक और परीक्षण में आपका स्वागत है। Google का नया रीकैप्चा आपको "आंखों के परीक्षणों" की एक श्रृंखला में ले जाता है, यह देखने के लिए कि आप इंसान हैं या रोबोट। इसलिए, यदि आप कोई गैर-संदर्भित या संदिग्ध खोज करते हैं, तो Google आपको उनके पूरे समूह से कुछ विशिष्ट छवियों को चुनने के लिए कहेगा। हम सभी ने देखा है कि Google हमसे ट्रैफिक लाइट, कार, पार्क या सड़क के संकेतों के साथ चित्रों की पहचान करने के लिए कह रहा है, है ना? यही NoCAPTCHA reCAPTCHA है।
यह कैप्चा का सबसे अद्यतन और सबसे व्यापक रूप से उपयोग किया जाने वाला संस्करण है, जिसका उपयोग न केवल Google बल्कि ट्विटर, फेसबुक और क्रेगलिस्ट जैसे प्लेटफॉर्म द्वारा उपयोगकर्ताओं के सोशल मीडिया प्रोफाइल के स्पैम और दुरुपयोग को रोकने के लिए मानव-एआई भेद के माध्यम के रूप में किया जाता है। लेकिन एक बार फिर, इस संस्करण में चित्र मानव आंखों के लिए धुंधले हो गए हैं, पहेली की जटिलता को बढ़ाते हुए, और फिर से उसी रास्ते पर आ गए हैं जिस पर reCAPTCHA पहले जाता था।
लेकिन क्यों?
कैप्चा पहेलियाँ इतनी जटिल क्यों हैं?

कैप्चा को एक माध्यम के रूप में शुरू किया गया था ताकि बॉट्स और मशीनों को मानव उपयोगकर्ता के रूप में नकल करने और गलत तरीके से किसी भी तरह के डेटा तक पहुंचने से रोका जा सके। लेकिन जैसे-जैसे मशीन लर्निंग और आर्टिफिशियल इंटेलिजेंस पर अनुसंधान और प्रयोग बहुत आगे बढ़े और सफल भी रहे, हमने बहुत जटिल गणनाओं को हल करने की क्षमता वाली मशीनें बनाईं और कैप्चा केक का एक टुकड़ा बन गया। विज्ञान ने मशीन को इतनी व्यापक क्षमताएं दी हैं, कि अब अगर हम सॉफ्टवेयर या बॉट के लिए कुछ कठिन बनाने की कोशिश करते हैं, तो इंसान के लिए इसे डीकोड करना कठिन हो जाएगा।
क्या यह बहुत आश्चर्य की बात है कि CAPTCHA किसी तरह विफल हो रहा है?

निश्चित रूप से नहीं। हमने कार्यात्मक क्वांटम कंप्यूटर बनाए हैं। हमने वित्तीय विश्लेषण, व्यावसायिक निर्णयों और चिकित्सा विज्ञान से संबंधित सैकड़ों पहेलियों और गणना समस्याओं को हल किया है। हमने अपने जीवन को आसान बनाने और अधिक जटिल अनुसंधान क्षेत्रों में हमारी मदद करने के लिए मशीन-आधारित अनुप्रयोगों और उपकरणों के टन का उपयोग किया है। और इस बीच, हमने कार्य की गति और दक्षता बढ़ाने के लिए मशीनों को उनकी अपनी बुद्धि दी है। चूँकि हमारा जीवन एआई और मशीन लर्निंग पर बहुत अधिक निर्भर है, यह कुछ ही समय की बात है कि यह हमसे आगे निकल गया।
कैप्चा कितनी लंबाई तक आगे बढ़ सकता है?

शोधकर्ता इस प्रतिक्रिया-चुनौती तंत्र के साथ क्या कर रहे हैं, यह अभी शुरुआत है। वर्तमान कैप्चा टूल को अपग्रेड करने और इन प्रतिक्रिया चुनौती-परीक्षणों के तरीके को बदलने के लिए विभिन्न परीक्षण किए गए हैं। 2017 में, पेपाल ने एक नई तरह की कैप्चा तकनीक पर पेटेंट प्राप्त किया। यहां, एक उपयोगकर्ता से उसकी मानवता साबित करने के लिए पूछे गए पहेलियाँ और प्रश्न उनकी जातीयता, स्थान और लिंग के अनुसार भिन्न होंगे। इसी तरह, अमेज़ॅन टेक्नोलॉजीज ने कैप्चा पहेली शैली का पेटेंट कराया, जहां लोगों को ऑप्टिकल भ्रम और विशिष्ट तर्क पहेली को हल करने के लिए कहा जाएगा, जो उनके लिए अपरिचित होंगे। अब, यहाँ अमेज़न ने पहेली को उलटने की कोशिश की। अमेज़ॅन टेक्नोलॉजीज ने दावा किया है कि अधिकांश मनुष्यों को ऐसी प्रतिक्रियाएं गलत मिलेंगी, जबकि आधुनिक एआई, अपनी क्षमताओं को देखते हुए, इसे सही कर देगा, और इसलिए, गलत प्रतिक्रिया के साथ प्रतिक्रिया मानव उपयोगकर्ता होगी। अन्य पेटेंट में कैप्चा के लिए गेम जैसी पहेली शामिल है, जहां उपयोगकर्ताओं को अपनी मानवता साबित करने के लिए बोर्ड पहेली प्रकार की छवियों को हल करने की आवश्यकता होगी। ये कुछ शुरुआती विचार हैं जो कैप्चा को अपडेट करने के लिए अपना रास्ता बना रहे हैं।
लेकिन, क्या वे वास्तव में प्रभावी हैं?

कई मायनों में, वे नहीं हैं। सबसे पहले, इस "अंतरिक्ष-युग" पीढ़ी में जहां मशीन सीखना सचमुच मानव विकास में अगला कदम है, कोई भी कैप्चा अखंड नहीं रहेगा। -दूसरा, ये विचार मनुष्यों के लिए बहुत जटिल हैं। यदि आप किसी लड़के से सांस्कृतिक रूप से विविध प्रश्नों का हर समय सही उत्तर देने की अपेक्षा करते हैं, तो आप गलत हैं। लोग बहुत बड़े पैमाने पर जातीयता, भाषा और व्यक्तित्व में एक दूसरे से भिन्न होते हैं और सांस्कृतिक पृष्ठभूमि के आधार पर प्रतिक्रिया-चुनौतियों के इतने व्यापक सेट को विकसित करना लगभग असंभव है। इसके अलावा, इंटरनेट एक ऐसी चीज है, जो किसी के भी आईक्यू, उम्र और खुफिया स्तर की परवाह किए बिना कहीं से भी पहुंच सकती है। इसलिए, यह विश्वास करना कठिन है कि हर उम्र के प्रत्येक व्यक्ति में एक वेब पेज पास करने के लिए बोर्ड गेम पहेली को हल करने की क्षमता होगी। शायद, मशीन के हस्तक्षेप के खिलाफ प्रतिरोध बनाए रखने के लिए, शोधकर्ता भूल गए हैं कि एक इंसान होना कैसा होता है और उस कारक को अपने हाल के विकास से हटा दिया है।
कैप्चा को अधिक विश्वसनीय बनाने के लिए क्या किया जा सकता है?
खैर, यह एक महान चर्चा और शोध का विषय है, इससे पहले कि हम कुछ ऐसा कर सकें जो मनुष्यों के लिए इसे आसान बना दे। However, there is a need to look for some aspect of human behavior that may be impossible for an AI bot to mimic. More focus can be diverted to developing CAPTCHA tools that would look for webpage “actions”. Google recently activated its Version 3 of reCAPTCHA called reCAPTCHA v3. The new version of the response-challenge test by Google use what’s called “Adaptive Risk Analysis”, which do not push users to any sort of test and don’t ask them for ticking up the virtual box. It’s completely friction-free for users and allows them to access webpages directly. To carry out bot detection for preventing spam abuse, Google’s new reCAPTCHA would allow website owners to determine whether their site users are a bot or not, via scores that Google would give them based on its risk analysis algorithm. The score would detect if the traffic on the site is suspicious or not. Owners can then present suspicious users with a response test to cross-check reCAPTCHA’s detection. While Google won’t tell how their new algorithm would assign these scores to users, it can be considered as a welcoming medium of filtering traffic, where users’ annoyance and difficulty to solve the earlier tests has been considered.
Final Opinion

It’s too early to say that Google’s new reCAPTCHA v3 is the best and most user-friendly way to avoid bot traffic on webpages. Moreover, the pace at which AI and machine learning research are moving ahead, we cannot know of implications that would have on any new CAPTCHA technique.
Since people are putting more stakes at machine learning and not on surveillance on machine activities, all these new patents of CAPTCHA techniques may become non-viable in the near future. For now, CAPTCHA remains the most widely used response-challenge test for bot detection on the web. But to have it that way for more and more years, it is important that methods of the distinction between AI and humans are discovered before we pass on everything we have and whatever defines our legacy to the smart machines we are being dependent on.