भाषा और भाषाई अध्ययनों को अक्सर डेटा की आवश्यकता होगी कि शब्दों का उपयोग कैसे किया जाता है, खासकर समय के साथ। जबकि शोध एक आवश्यकता है, आपको आवश्यक डेटा देने के लिए उपकरण होने का स्वागत है। Google Ngram व्यूअर संपूर्ण Google पुस्तकें लाइब्रेरी में शब्द प्रवृत्तियों को शीघ्रता से खोजने का एक शानदार तरीका है।
इस पोस्ट में, हम आपको दिखाते हैं कि Google Ngram का अधिक प्रभावी ढंग से उपयोग कैसे करें। सबसे पहले, आइए आपको टूल से परिचित कराते हैं।
पेश है Google Ngram
Google प्रकाशित भाषा का बहुभाषी डेटाबेस रखता है। पुस्तकों को सामूहिक रूप से स्कैन करके, खोज विशाल पाठ को संसाधित करने और शब्दों की आवृत्ति के आधार पर आंकड़े प्रदान करने में सक्षम है।
गूगल एनग्राम व्यूअर सर्च टूल से आप इस डेटा के जरिए सर्च कर सकते हैं। शब्दों की सापेक्षिक लोकप्रियता की तुलना करके, आप यह पता लगा सकते हैं कि समय के साथ भाषा और संस्कृति कैसे बदली है।
हालांकि, Google Ngram टूल केवल शब्द आवृत्ति की रिपोर्ट करने के अलावा और भी बहुत कुछ कर सकता है, जैसा कि हम आगे करेंगे।
बुनियादी खोज कैसे करें
इससे पहले कि हम उन्नत "रणनीतियों" में उतरें, आइए एक बुनियादी खोज को पूरा करने के तरीके के बारे में जानें। Google Ngram पेज से, खोज बॉक्स में एक कीवर्ड टाइप करें।

यदि आप किसी शब्द के सभी बड़े अक्षरों को शामिल करना चाहते हैं, तो केस-असंवेदनशील बटन पर टिक करें। इस खोज में "तकनीक" और "तकनीक" शामिल होंगे।
खोज बॉक्स के नीचे, आप दिनांक सीमा और "चिकनाई" जैसे पैरामीटर भी सेट कर सकते हैं। बाद वाला मान आपके डेटा से असामान्य स्पाइक्स और डिप्स को हटा देता है। कम स्मूदिंग मान अधिक सटीक होते हैं, जबकि उच्च मान केवल गहरे रुझानों को प्रकट करते हैं।
“कॉर्पस” कैसे चुनें
कॉर्पस टेक्स्ट संग्रह है जिसे एनग्राम व्यूअर जांच करेगा। आकस्मिक ब्राउज़िंग के लिए "अंग्रेज़ी" का डिफ़ॉल्ट स्वीकार्य है लेकिन अत्यधिक अकादमिक हो सकता है।
"इंग्लिश फिक्शन" आम भाषा को अधिक बारीकी से प्रतिबिंबित करेगा। बहुत सारे तकनीकी शब्दों के साथ मानक "अंग्रेजी" कॉर्पस गैर-फिक्शन भारी हो सकता है।
जबकि आपकी पसंद के कॉर्पस के पीछे का गहरा अर्थ इस टुकड़े के दायरे से बाहर है, Google आपके लिए सही विकल्प में एक संक्षिप्त अंतर्दृष्टि प्रदान करता है।
उन्नत खोज करना
अतिरिक्त खोज शब्दों का उपयोग करके, आप जटिल तुलनाएँ बना सकते हैं। ऐसा करने के लिए, प्रत्येक पद को अल्पविराम से अलग करें।
Ngram व्यूअर एक ही ग्राफ़ में आपके खोज शब्दों की सापेक्ष आवृत्ति प्रदर्शित करेगा। यहां, आप सटीक डेटा बिंदु देखने के लिए ग्राफ़ की रेखाओं पर होवर कर सकते हैं।
आप वाइल्डकार्ड के रूप में अपने खोज शब्दों में तारक का उपयोग भी कर सकते हैं। उदाहरण के लिए, "बैचलर ऑफ़ *" कई स्नातक डिग्री के परिणाम लौटाएगा।
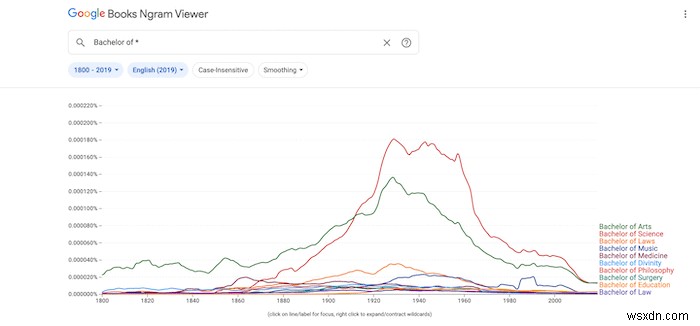
किसी पद के सभी विभक्तियों को खोजने के लिए, "_INF" संशोधक संलग्न करें।
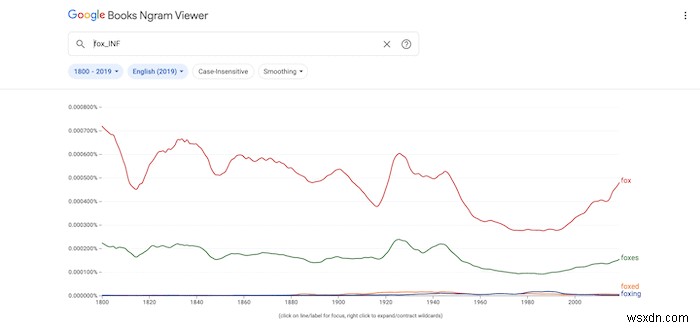
यदि किसी शब्द में भाषण के कई भाग शामिल हैं, तो आप टेक्स्ट ऑपरेटरों का उपयोग करके अधिक विशिष्ट हो सकते हैं। Google के डेटाबेस में वाक् के मान्य भागों में निम्नलिखित सभी शामिल हैं:
- _ADJ_ :विशेषण (तेज़, बड़े, स्मार्ट)
- _ADV_ :क्रिया विशेषण (जल्दी, बाद में, हमेशा)
- _PRON_ :सर्वनाम (उनका, यह, हम)
- _DET_ :निर्धारक या लेख (ए, ए, द)
- _ADP_ :समायोजन (पूर्वसर्ग और पदस्थापन)
- _NUM_ :अंक (पहला, दूसरा, पांचवां)
- _CONJ_ :संयोजन (और, न ही, लेकिन)
- _PRT_ :कण, जो एक कैटचेल है, अन्य शब्द कार्यों के लिए शायद ही कभी इस्तेमाल की जाने वाली श्रेणी है
इनमें से प्रत्येक को वाक्यांशों में जोड़ा जा सकता है। उदाहरण के लिए, "_ADJ_ लड़का" विशेषण और "लड़का" के लिए शब्द जोड़े लौटाएगा।
एक खोज शब्द के लिए भाषण का एक विशिष्ट भाग निर्दिष्ट करने के लिए, इसे अंत में संलग्न करें। उदाहरण के लिए, "water_VERB" बिना पीछे वाले अंडरस्कोर के। किसी दिए गए शब्द के लिए भाषण के प्रत्येक भाग को शामिल करने के लिए, अंडरस्कोर के बाद वाइल्डकार्ड ऑपरेटर का उपयोग करें।
कार्यात्मक चर, संरचना और निर्भरता
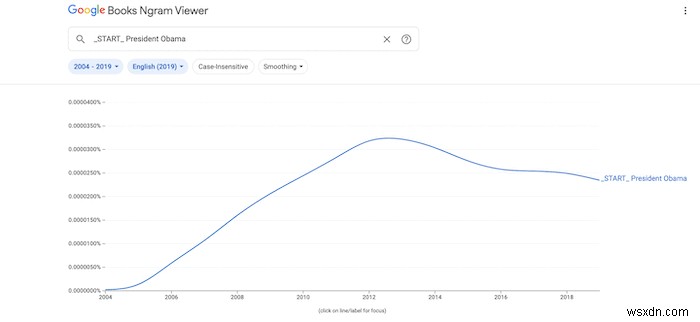
कार्यात्मक चर आपको फ़ंक्शन या शब्दों के स्थान के आधार पर खोजने देते हैं।
- _ROOT_ वाक्य के पार्स ट्री की जड़ के लिए एक प्लेसहोल्डर है। यह आमतौर पर प्राथमिक विषय या क्रिया द्वारा संशोधित शब्द है।
- _START_ एक वाक्य की शुरुआत को इंगित करता है। ("_START_ राष्ट्रपति ओबामा" केवल वही वाक्य लौटाता है जो शुरू "राष्ट्रपति ओबामा" वाक्यांश के साथ)
- _END_ एक वाक्य के अंत को इंगित करता है। ("_ADP_ _END_" ऐसे वाक्य लौटाता है जो समाप्त पूर्वसर्गों में।)
अंकगणितीय ऑपरेटरों के साथ खोज शब्दों को मिलाकर, आप शब्द आवृत्ति के लिए मूल्यों के साथ सरल गणितीय विश्लेषण कर सकते हैं:
- + एक खोज शब्द में अनेक भाव जोड़ता है
- – दो खोज शब्दों के सापेक्ष उपयोग की तुलना करने का एक त्वरित तरीका प्रदान करते हुए, बाईं ओर के व्यंजक से दाईं ओर के व्यंजक को घटाता है।
- / बाईं ओर के व्यंजक को दाईं ओर के व्यंजक से विभाजित करता है
- * व्यापक रूप से भिन्न आवृत्ति के ngrams की तुलना करने के लिए व्यंजक को गुणा करता है। वाइल्डकार्ड वर्ण के रूप में तारांकन को पार्स करने से बचने के लिए पूरे एनग्राम को कोष्ठक में संलग्न करना सुनिश्चित करें।
- : (एक कोलन) दायीं ओर कॉर्पस के भीतर बाईं ओर ngram की खोज करता है।
अंत में, आप भाषाई संबंधों को खोजने के लिए निर्भरता को "=>" के साथ सेट कर सकते हैं।
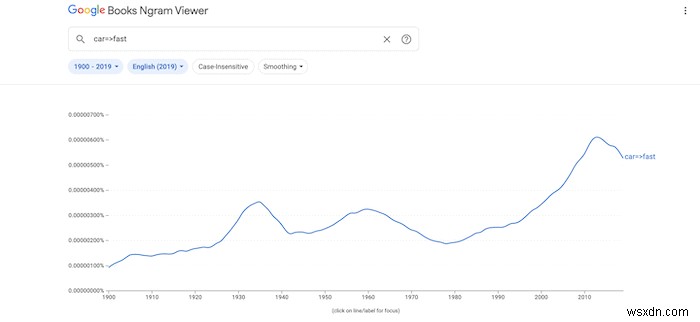
उदाहरण के लिए, "कार => तेज" ऐसे परिणाम देगा जहां "तेज" शब्द "कार" पर व्याकरणिक रूप से निर्भर था, या संशोधित कर रहा था। इसे किसी भी उन्नत खोज अभियान के साथ स्वतंत्र रूप से मिलाया जा सकता है।
निष्कर्ष
शब्द प्रवृत्तियों की खोज में कई शैक्षणिक अनुप्रयोग हैं। आपको आवश्यक जानकारी खोजने का एक त्वरित तरीका Google का Ngram टूल है। अच्छी खबर यह है कि यह न केवल आपको बुनियादी खोज करने देता है। अपनी ज़रूरत की जानकारी में सुधार करने के लिए आप शक्तिशाली संशोधक लागू कर सकते हैं।
हुड के तहत खोज इंजन के उन्नत ग्रंट के बिना Google Ngram की कोई भी कार्यक्षमता संभव नहीं होगी। क्या आप इस बात से प्रभावित हैं कि Google Ngram टूल क्या कर सकता है? हमें नीचे टिप्पणी अनुभाग में बताएं!


