इस ट्यूटोरियल में, आप सीखेंगे कि अपने आईओएस और मैकओएस ऐप में उपयोग करने के लिए कस्टम डॉग-नस्ल वर्गीकरण कोर एमएल मॉडल को कैसे प्रशिक्षित किया जाए। आपका कोर एमएल मॉडल इस ट्यूटोरियल के अंत तक पांच अलग-अलग नस्लों के बीच अंतर करने में सक्षम होगा!
आपको याद होगा कि Apple ने कुछ साल पहले मशीन लर्निंग और आर्टिफिशियल इंटेलिजेंस स्टार्टअप तुरी का अधिग्रहण $200M से ऊपर किया था; यह कम समय में उन्नत मशीन लर्निंग मॉडल बनाने के लिए शक्तिशाली टूल प्रदान करता है।
इस ट्यूटोरियल में, आप अपने मैक पर ट्यूरी क्रिएट को इंस्टॉल करना, एक पायथन स्क्रिप्ट बनाना और उस स्क्रिप्ट का उपयोग कोर एमएल मॉडल को प्रशिक्षित करने के लिए करना सीखेंगे, जिसे आप सीधे अपने एक्सकोड प्रोजेक्ट्स में खींच सकते हैं और अपने ऐप में जल्दी से लागू कर सकते हैं।
आरंभ करना
इससे पहले कि हम इसके वास्तविक मशीन लर्निंग हिस्से के साथ शुरुआत करें, आइए पहले टुरी और पायथन की स्थापना को पूरी तरह से हटा दें - और, निश्चित रूप से, आपको यह सुनिश्चित करना होगा कि आपका हार्डवेयर और सॉफ़्टवेयर टुरी की आवश्यकताओं को पूरा करता है।
आवश्यकताएं
आपके द्वारा इंस्टॉल किए गए किसी भी सॉफ़्टवेयर की तरह, तुरी क्रिएट की कुछ विशिष्ट आवश्यकताएं हैं, जो उनके आधिकारिक GitHub पृष्ठ पर पाई जा सकती हैं।
तुरी क्रिएट सपोर्ट:
- मैकोज़ 10.12+
- लिनक्स (ग्लिब 2.12+ के साथ)
- Windows 10 (WSL के माध्यम से)
तुरी क्रिएट की आवश्यकता है:
- पायथन 2.7, 3.5, 3.6
- x86_64 आर्किटेक्चर
- कम से कम 4 जीबी रैम
लब्बोलुआब यह है, जब तक आपका मैक यथोचित है नया, आपको तुरी क्रिएट चलाने में सक्षम होना चाहिए। यदि आप चाहें, तो आप किसी अन्य ऑपरेटिंग सिस्टम के साथ अनुसरण कर सकते हैं; हालांकि, आपको उनके काम करने के लिए कुछ चरणों को बदलने की आवश्यकता हो सकती है।
इंस्टॉलेशन
तुरी क्रिएट को स्थापित करना काफी सरल है, खासकर यदि आप कमांड लाइन से परिचित हैं। जब आप पायथन के नए संस्करण का उपयोग करना चुन सकते हैं, तो मैं इस ट्यूटोरियल में पायथन 2.7 का उपयोग करूँगा।
MacOS Mojave में, Python 2.7 डिफ़ॉल्ट रूप से स्थापित होता है, इसलिए आपको केवल संस्करण की जाँच करने की आवश्यकता है। अपने Mac पर, एप्लिकेशन> यूटिलिटीज> Te . खोलें rminal या बस उनके कीबोर्ड से इसे खोजेंrtcut Command -स्पेस।
अपने Mac पर Python के संस्करण की जाँच करने के लिए, दर्ज करें:
$ python - versionयह आपको पायथन का संस्करण बताएगा, और आपका कंसोल कुछ इस तरह दिखना चाहिए:
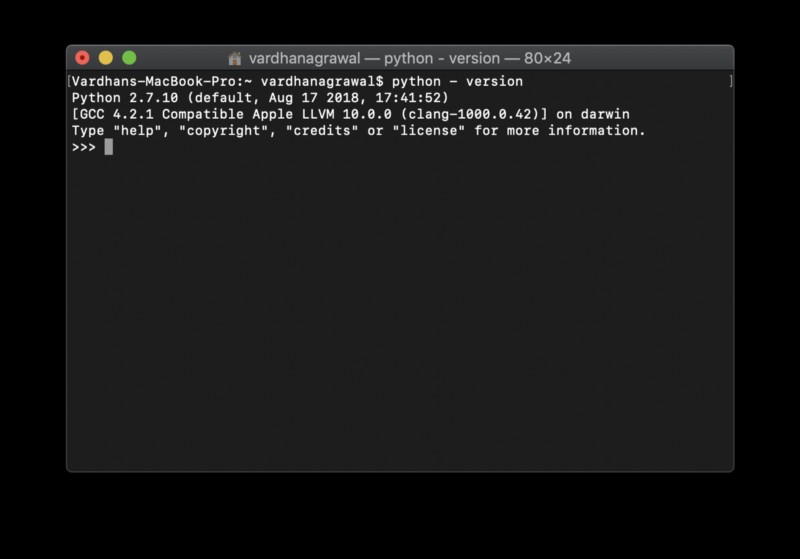
यदि आपका संस्करण पायथन 2.7 नहीं है, या यदि यह किसी कारण से आपके कंप्यूटर पर स्थापित नहीं है, तो आपको इसे इस लिंक पर स्थापित करना चाहिए। अगर आपका आउटपुट मेरे जैसा दिखता है, तो आप आगे बढ़ने के लिए तैयार हैं।
नोट: कुछ लोग ट्यूरी क्रिएट को स्थापित करने के लिए वर्चुअल मशीन का उपयोग करना पसंद करते हैं क्योंकि ऐप्पल यही अनुशंसा करता है। लेकिन चीजों को सरल रखने के लिए, हम इसे सीधे इंस्टॉल करेंगे।
टुरी क्रिएट को इंस्टाल करने के लिए, बस अपनी टर्मिनल विंडो में निम्नलिखित दर्ज करें:
$ pip install turicreateबस इतना ही! Turi Create आपके Mac पर सफलतापूर्वक इंस्टॉल हो गया है, और यह उपयोग के लिए तैयार है। अब आप वर्गीकरण, पहचान, प्रतिगमन और अन्य प्रकार के मॉडल बना सकते हैं।
डेटासेट
किसी भी मशीन लर्निंग मॉडल के लिए, आपको एक डेटासेट की आवश्यकता होती है। इस ट्यूटोरियल में, आप सीखेंगे कि एक साधारण कुत्ते-नस्ल वर्गीकरण मॉडल को कैसे प्रशिक्षित किया जाए, जिसके लिए छवि वर्गीकरण की आवश्यकता होती है। मैं जिस डेटा का उपयोग कर रहा हूं वह स्टैनफोर्ड यूनिवर्सिटी के डॉग्स डेटासेट से आता है।
तुरी के लिए पूर्व-वर्गीकृत छवियों को पहचानने में सक्षम होने के लिए, आपको उन्हें उनके प्रतिनिधित्व के आधार पर व्यवस्थित करने की आवश्यकता होगी। उदाहरण के लिए, गोल्डन रिट्रीवर्स की सभी छवियां एक फ़ोल्डर में होंगी, जबकि लैब्राडूडल्स की सभी तस्वीरें दूसरे में होंगी।
सादगी के लिए, हम स्टैनफोर्ड के डेटासेट में सैकड़ों में से केवल पांच नस्लों का उपयोग करेंगे, लेकिन आप जितनी चाहें उतनी का उपयोग कर सकते हैं। मैंने आगे बढ़कर आपके लिए इसे व्यवस्थित किया है और इसके लिए एक भंडार बनाया है। यदि आप अधिक कुत्तों की नस्लों को जोड़ना चुनते हैं, तो बस अधिक फ़ोल्डर जोड़ें और उन्हें अपनी इच्छानुसार नाम दें।
फ़ोल्डर संरचना
अब तक, आपको पता चल गया होगा कि जिस तरह से आप अपने डेटासेट को व्यवस्थित करते हैं, वह मॉडल को सही ढंग से प्रशिक्षित करने में सक्षम होने के लिए महत्वपूर्ण है - ऐसा कोई अन्य तरीका नहीं है जिससे तुरी क्रिएट को पता हो कि क्या जाता है। खुद को व्यवस्थित करने के लिए अभी कुछ समय निकालें।
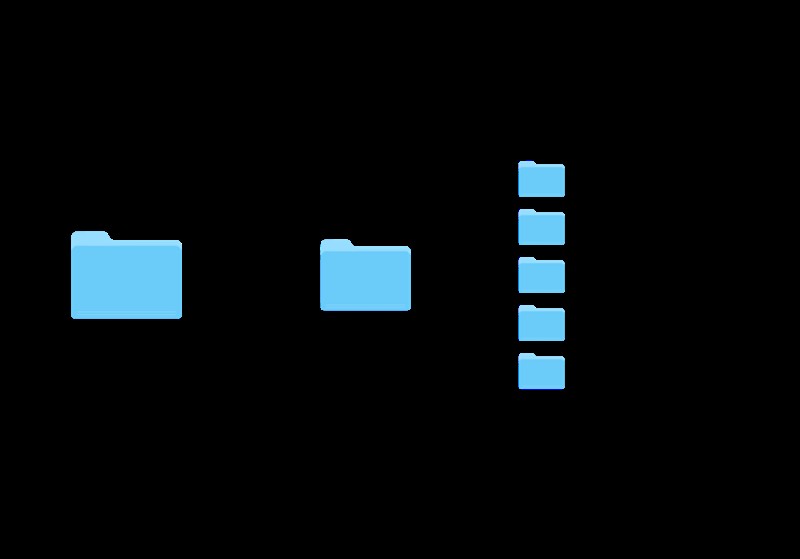
इस पदानुक्रम आरेख को सब कुछ समझाना चाहिए, और इस ट्यूटोरियल को जारी रखने से पहले आपको अपने फ़ोल्डर्स को इस क्रम में प्राप्त करने की आवश्यकता होगी। अगर आप नाम बदलना चाहते हैं या चीजों को अलग तरीके से व्यवस्थित करना चाहते हैं, तो आपको यह सुनिश्चित करना होगा कि आप इसे नोट कर लें।
क्लासिफायर को प्रशिक्षण देना
आपके द्वारा सेट अप करने के बाद, आप इस ट्यूटोरियल के मांस में गोता लगाने के लिए तैयार हैं - वास्तव में अपने क्लासिफायरियर को प्रशिक्षित करना। हम ज्यादातर पायथन में काम करेंगे, लेकिन अगर आपने पहले कभी पायथन का इस्तेमाल नहीं किया है, तो कोई बात नहीं। जैसे-जैसे हम आगे बढ़ेंगे, मैं प्रत्येक चरण की व्याख्या करूँगा, और यदि आपके कोई प्रश्न हैं, तो नीचे टिप्पणी करने में संकोच न करें।
पायथन फ़ाइल
सबसे पहले, हमें अपने विचारों को रखने के लिए एक जगह की आवश्यकता होगी (अर्थात, निश्चित रूप से, पायथन में)। यदि आपके पास पहले से ही एक संपादक है जो पायथन का समर्थन करता है, जैसे कि एटम या एक एकीकृत विकास वातावरण जैसे कि PyCharm, तो आप उनका उपयोग dog_breeds.py नामक एक रिक्त फ़ाइल बनाने के लिए कर सकते हैं। ।
यदि आप अधिक डेवलपर-वाई मार्ग पसंद करते हैं, जैसे मैं करता हूं, तो आप वही काम करने के लिए टर्मिनल का उपयोग कर सकते हैं। आपको यह फ़ाइल अपने ml_classifier . के अंदर बनानी होगी images . के साथ फ़ोल्डर फ़ोल्डर ताकि आपका पदानुक्रम इस तरह दिखे:
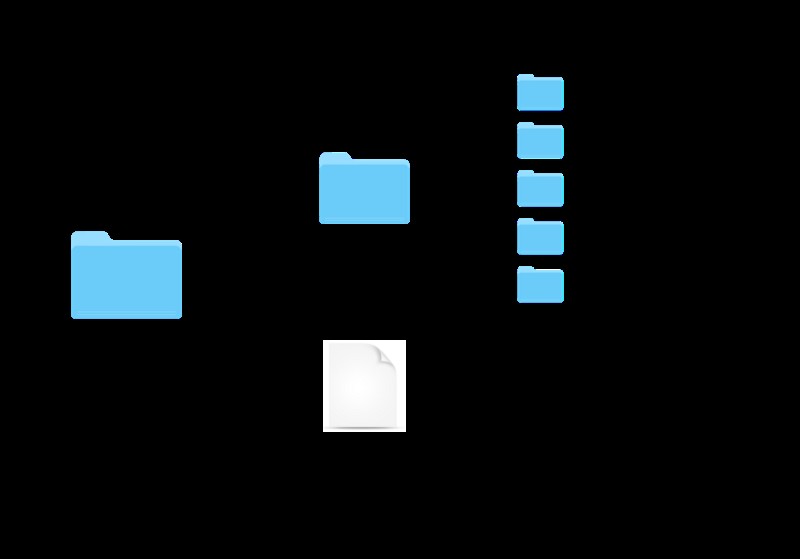
एक नई फ़ाइल बनाने के लिए, पहले लक्ष्य निर्देशिका में प्रवेश करें:
$ cd ml_classifier
फिर, dog_breeds.py . नाम की एक नई फ़ाइल बनाएं ।
$ touch dog_breeds.pyवोइला! आपके फ़ोल्डर, फ़ाइलें और छवियां वे सभी हैं जहां उन्हें होना चाहिए, और आप अगले चरण के साथ जारी रखने के लिए तैयार हैं। हम अपनी फ़ाइल को खोलने के लिए Xcode का उपयोग करेंगे, इसलिए सुनिश्चित करें कि आपने इसे इंस्टॉल और अप-टू-डेट किया है।
डेटासेट छवियां लोड हो रही हैं
अंत में, ट्यूरी को यह बताना शुरू करने का समय आ गया है कि हमारे द्वारा अभी बनाई गई पायथन फ़ाइल के माध्यम से उसे क्या करने की आवश्यकता है। यदि आप फ़ाइल को डबल-क्लिक करते हैं, तो इसे डिफ़ॉल्ट रूप से Xcode में खुल जाना चाहिए, यदि आपने इसे इंस्टॉल किया है। यदि नहीं, तो आप किसी अन्य संपादक या पायथन आईडीई का भी उपयोग कर सकते हैं।
1. फ्रेमवर्क आयात करें
import turicreate
फ़ाइल के शीर्ष पर, आपको तुरी क्रिएट फ्रेमवर्क को आयात करना होगा। आप चाहें तो as <your na . जोड़कर संदर्भ के लिए एक नाम बना सकते हैं मैं>. उदाहरण के लिए, यदि आप it . का संदर्भ लेना चाहते हैं अपने कोड में tc के रूप में, आप लिख सकते हैं:
import turicreate as tc
इससे आप इसे tc . कह सकते हैं लिखने के बजाय turicreate . इस ट्यूटोरियल में, मैं पूर्ण संस्करण का उपयोग करूँगा, इसे turicreate . कहेंगे अस्पष्टता को कम करने के लिए।
अपनी छवियों को वर्गीकृत करने के लिए आपको फ़ोल्डर के नाम और ओएस से संबंधित अन्य कार्यों से भी निपटना होगा। इसके लिए os called नामक एक अन्य पायथन लाइब्रेरी की आवश्यकता होगी . इसे आयात करने के लिए, बस निम्नलिखित जोड़ें:
import os2. छवियां लोड हो रही हैं
data = turicreate.image_analysis.load_images("images/")
यहां, हम अपने डेटासेट में सभी छवियों को data . नामक एक चर में संग्रहीत कर रहे हैं . चूंकि हमारा dog_breeds.py फ़ाइल उसी निर्देशिका में है जिसमें images . है फ़ोल्डर, हम बस “images/” . डाल सकते हैं पथ के रूप में।
3. लेबल को परिभाषित करना
अब जब तुरी क्रिएट में आपकी सभी छवियां हैं, तो आपको फ़ोल्डर नामों को एक लेबल नाम से लिंक करना होगा। ये लेबल नाम वे हैं जो आपके कोर एमएल मॉडल में लौटाए जाएंगे जब इसका उपयोग आईओएस या मैकोज़ ऐप में किया जा रहा है।
data["label"] = data["path"].apply(lambda path: os.path.basename(os.path.dirname(path)))यह आपको अपने सभी फ़ोल्डर नामों को "लेबल" नाम से मैप करने की अनुमति देता है, जो तुरी क्रिएट को बताता है कि "कॉकर_स्पैनियल" फ़ोल्डर में मौजूद सभी छवियां वास्तव में कॉकर स्पैनियल हैं, उदाहरण के लिए।
4. SFrame के रूप में सेव करें
यदि आप SFrame . से परिचित नहीं हैं तो , सरल शब्दों में, यह आपके सभी डेटा (इस मामले में, एक छवि) और सभी लेबल (इस मामले में, कुत्ते की नस्ल) का एक शब्दकोश है। अपना SFrame सेव करें इस तरह:
data.save("dog_classifier.sframe")यह आपको अगले चरण में उपयोग के लिए अपनी लेबल की गई छवियों को संग्रहीत करने की अनुमति देता है। यह मशीन लर्निंग उद्योग में काफी मानक डेटा प्रकार है।
प्रशिक्षण और परीक्षण
तुरी क्रिएट में आपकी सभी लेबल की गई छवियां होने के बाद, घर के खिंचाव में प्रवेश करने और अंत में अपने मॉडल को प्रशिक्षित करने का समय आ गया है। हमें डेटा को विभाजित करने की भी आवश्यकता है ताकि प्रशिक्षण के लिए 80% का उपयोग किया जा सके, और प्रशिक्षण के बाद मॉडल के परीक्षण के लिए 20% की बचत हो - हमें इसे मैन्युअल रूप से परीक्षण करने की आवश्यकता नहीं होगी।
1. SFrame लोड हो रहा है
अब, हमें पिछले चरण में बनाए गए SFrame को लोड करने की आवश्यकता है। इसका उपयोग हम बाद में परीक्षण और प्रशिक्षण डेटा में विभाजित करने के लिए करेंगे।
data = turicreate.SFrame("dog_classifier.sframe")
यह data . असाइन करता है चर, जो अब SFrame . प्रकार का है उस SFrame में जिसे हमने पिछले चरण में सहेजा था। अब, हमें डेटा को परीक्षण और प्रशिक्षण डेटा में विभाजित करने की आवश्यकता होगी। जैसा कि पहले बताया गया है, हम परीक्षण डेटा के लिए परीक्षण का 80:20 विभाजन करेंगे।
2. डेटा विभाजित करना
डेटा को विभाजित करने का समय आ गया है। अपने SFrame कोड के बाद, निम्नलिखित जोड़ें:
testing, training = data.random_split(0.8)
यह कोड बेतरतीब ढंग से डेटा को 80–20 में विभाजित करता है और इसे दो चरों के लिए असाइन करता है, testing और training , क्रमश। अब, परीक्षण छवियों को मैन्युअल रूप से आपूर्ति करने और एक ऐप बनाने की आवश्यकता के बिना, तुरी स्वचालित रूप से आपके मॉडल का परीक्षण करेगा - यदि आपको समायोजन करने की आवश्यकता है, तो आपको पहले इसे पूरी तरह से लागू करने की आवश्यकता नहीं होगी, और इसके बजाय, आप उन्हें अपने पायथन में सही कर सकते हैं फ़ाइल।
3. प्रशिक्षण, परीक्षण और निर्यात
आपकी मेहनत आखिरकार रंग लाई! पायथन कोड की इस पंक्ति में, आप बस अपने मॉडल को प्रशिक्षित करने के लिए तुरी क्रिएट को बताएंगे, जबकि उस आर्किटेक्चर को निर्दिष्ट करेंगे जिसका आप उपयोग करना चाहते हैं।
classifier = turicreate.image_classifier.create(testing, target="label", model="resnet-50")
आप बस तुरी को अपने testing . का उपयोग करने के लिए कह रहे हैं डेटा (पहले निर्दिष्ट), और उनका उपयोग labels . की भविष्यवाणी करने के लिए करें (पहले से फ़ोल्डर संरचना के आधार पर), resnet-50 . का उपयोग करते समय , जो सबसे सटीक मशीन लर्निंग मॉडल आर्किटेक्चर में से एक है।
अपने परीक्षण डेटा का उपयोग करने और यह सुनिश्चित करने के लिए कि आपका मॉडल सटीक है, इसे जोड़ें:
testing = classifier.evaluate(training)print testing["accuracy"]
यह training . का उपयोग करता है आपके द्वारा निर्दिष्ट डेटा और परीक्षण के बाद परिणामों को एक वैरिएबल में संग्रहीत करता है जिसे कहा जाता है (आपने अनुमान लगाया है) testing . आपकी जानकारी के लिए, यह सटीकता को प्रिंट करता है, लेकिन आप अन्य चीजों को भी प्रिंट कर सकते हैं, जिसे तुरी क्रिएट के एपीआई पर पर्याप्त समय दिया गया है।
अंतिम लेकिन कम से कम, आप अपने मॉडल को एक उपयोगी नाम देने के बाद इस वन-लाइनर के साथ सीधे अपने फाइल सिस्टम में सहेज सकते हैं:
classifier.save("dog_classifier.model")classifier.export_coreml("dog_classifier.mlmodel")बेशक, आप अपने मॉडल को अन्य प्रारूपों में भी सहेज सकते हैं, लेकिन इस उदाहरण के लिए, मैंने इसे कोर एमएल मॉडल के रूप में सहेजा है।
रनिंग और आउटपुट
आप सभी आईओएस डेवलपर्स के लिए - नहीं, यह एक एक्सकोड प्रोजेक्ट नहीं है जो स्वचालित रूप से संकलित करता है और त्रुटियों की शिकायत करता है। जिस कोड को आपने अभी निष्पादित करने के लिए लिखा है, उसके लिए हमें इसे टर्मिनल के माध्यम से करना होगा।
पायथन फ़ाइल चलाना
पायथन फ़ाइल चलाना आसान है! सुनिश्चित करें कि आप सही निर्देशिका में हैं, और आपको बस अपनी टर्मिनल विंडो में निम्नलिखित दर्ज करना है:
python dog_breeds.pyआउटपुट
कुछ मिनटों के प्रशिक्षण के बाद, आपका images फ़ोल्डर और dog_breeds.py फ़ाइल के साथ एक SFrame, एक मॉडल फ़ोल्डर और एक .mlmodel . होगा फ़ाइल, जो आपका कोर एमएल मॉडल है!
आपको अपनी टर्मिनल विंडो में आउटपुट के साथ प्रस्तुत किया जाएगा, जो कुछ इस तरह दिखाई देगा:
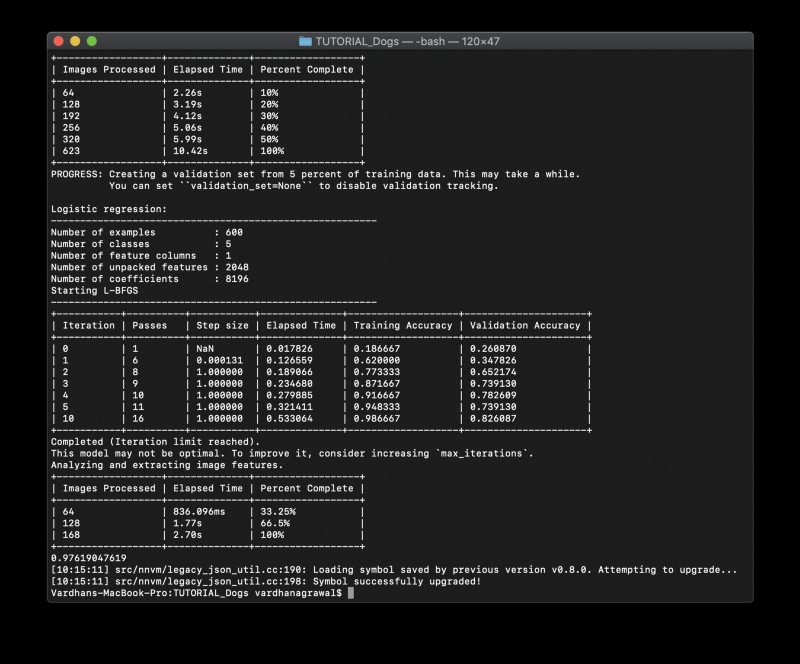
यह आपको प्रशिक्षण और प्रशिक्षण सटीकता, संसाधित छवियों की मात्रा और अन्य उपयोगी जानकारी के बारे में जानकारी देता है, जिसका उपयोग आप अपने मॉडल का विश्लेषण करने के लिए कभी भी इसका उपयोग किए बिना कर सकते हैं।
निष्कर्ष
मुझे आशा है कि आपको इस ट्यूटोरियल को पढ़ने में उतना ही मज़ा आया जितना मुझे इसे बनाने में मज़ा आया! यहां से जाने के लिए यहां कुछ चरण दिए गए हैं। अगर आप आईओएस ऐप में अपने कोर एमएल मॉडल का उपयोग करना सीखना चाहते हैं, तो मेरा एक और ट्यूटोरियल देखें:
कोर एमएल में छवि पहचान के साथ आरंभ करें
तकनीकी विकास के साथ, हम उस बिंदु पर हैं जहां हमारे डिवाइस सटीक रूप से पहचानने के लिए अपने अंतर्निहित कैमरों का उपयोग कर सकते हैं… कोड।
tutsplus.com
यह ट्यूटोरियल आपको दिखाएगा कि अपना परिणामी dog_classifier.mlmodel कैसे लें मॉडल बनाएं और इसे वास्तविक दुनिया के आईओएस ऐप में लागू करें। यह आपको लाइव वीडियो फ़ीड को पार्स करना और छवि वर्गीकरण के लिए अलग-अलग फ़्रेम लेना भी सिखाएगा।
यदि आपके पास इस ट्यूटोरियल के बारे में कोई प्रश्न या टिप्पणी है, तो उन्हें नीचे टिप्पणी अनुभाग में पूछने में संकोच न करें! मैं हमेशा इस ट्यूटोरियल से प्रतिक्रिया, प्रश्न या आपने अपने ज्ञान का उपयोग कैसे किया, यह सुनने के लिए उत्सुक हूं।
मेरे काम का समर्थन करना आसान है!
सुनिश्चित करें कि उस "क्लैप" बटन को तोड़ दें जितनी बार आप कर सकते हैं, इस ट्यूटोरियल को साझा करें सोशल मीडिया पर, और ट्विटर पर मेरा अनुसरण करें।
वर्धन अग्रवाल (@vhanagwal) | ट्विटर
वर्धन अग्रवाल (@vhanagwal) के नवीनतम ट्वीट। पूरी तरह से स्व-सिखाया गया #ios डेवलपर, #प्रशिक्षक, और मानव…