संचार की एक कहानी
क्या आपने कभी सोचा है कि इंटरनेट वास्तव में कैसे बोलता है? एक कंप्यूटर इंटरनेट के माध्यम से दूसरे कंप्यूटर से "बात" कैसे करता है?
जब लोग एक दूसरे के साथ संवाद करते हैं, तो हम अर्थपूर्ण वाक्यों में फंसे शब्दों का उपयोग करते हैं। वाक्य केवल इसलिए समझ में आते हैं क्योंकि हम इन वाक्यों के अर्थ पर सहमत हैं। हमने संचार के एक प्रोटोकॉल को परिभाषित किया है, इसलिए बोलने के लिए।
पता चला, इंटरनेट पर कंप्यूटर एक दूसरे से इसी तरह से बात करते हैं। लेकिन, हम खुद से आगे निकल रहे हैं। लोग संवाद करने के लिए अपने मुंह का उपयोग करते हैं, आइए पहले यह पता करें कि कंप्यूटर का मुंह क्या है।
सॉकेट दर्ज करें
सॉकेट कंप्यूटर विज्ञान में सबसे मौलिक अवधारणाओं में से एक है। आप सॉकेट का उपयोग करके आपस में जुड़े उपकरणों के पूरे नेटवर्क का निर्माण कर सकते हैं।
कंप्यूटर विज्ञान में अन्य सभी चीजों की तरह, सॉकेट एक बहुत ही अमूर्त अवधारणा है। इसलिए, यह परिभाषित करने के बजाय कि सॉकेट क्या है, यह परिभाषित करना कहीं अधिक आसान है कि सॉकेट क्या करता है।
तो, सॉकेट क्या करता है? यह दो कंप्यूटरों को एक दूसरे के साथ संवाद करने में मदद करता है। यह ऐसे कैसे करता है? इसकी दो विधियाँ परिभाषित हैं, जिन्हें send() . कहा जाता है और recv() क्रमशः भेजने और प्राप्त करने के लिए।
ठीक है, यह सब बहुत अच्छा है, लेकिन send() का क्या करें और recv() वास्तव में भेजें और प्राप्त करें? जब लोग अपना मुंह घुमाते हैं, तो वे शब्दों का आदान-प्रदान करते हैं। जब सॉकेट अपनी विधियों का उपयोग करते हैं, तो वे बिट्स और बाइट्स का आदान-प्रदान करते हैं।
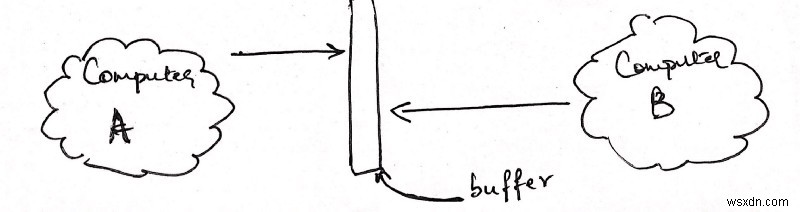
आइए एक उदाहरण के साथ विधियों का वर्णन करें। मान लीजिए कि हमारे पास दो कंप्यूटर हैं, ए और बी। कंप्यूटर ए कंप्यूटर बी को कुछ कहने की कोशिश कर रहा है। इसलिए, कंप्यूटर बी यह सुनने की कोशिश कर रहा है कि कंप्यूटर ए क्या कह रहा है। यह ऐसा दिखाई देगा।
बफ़र पढ़ना
थोड़ा अजीब लग रहा है, है ना? एक के लिए, दोनों कंप्यूटर बीच में एक बार की ओर इशारा कर रहे हैं, जिसका शीर्षक 'बफर' है।
बफर क्या है? बफर एक मेमोरी स्टैक है। यह वह जगह है जहां प्रत्येक कंप्यूटर का डेटा संग्रहीत किया जाता है, और कर्नेल द्वारा आवंटित किया जाता है।
अगला, वे दोनों एक ही बफर की ओर इशारा क्यों कर रहे हैं? खैर, यह वास्तव में बिल्कुल सटीक नहीं है। प्रत्येक कंप्यूटर का अपना बफर होता है जो अपने कर्नेल द्वारा आवंटित किया जाता है और नेटवर्क दो अलग-अलग बफ़र्स के बीच डेटा को स्थानांतरित करता है। लेकिन, मैं यहां नेटवर्क विवरण में नहीं जाना चाहता, इसलिए हम मान लेंगे कि दोनों कंप्यूटरों के पास एक ही बफर तक पहुंच है जिसे "कहीं बीच में शून्य में" रखा गया है।
ठीक है, अब जब हम जानते हैं कि यह दिखने में कैसा दिखता है, तो आइए इसे कोड में सारगर्भित करते हैं।
#Computer A sends data computerA.send(data) #Computer B receives data computerB.recv(1024)
यह कोड स्निपेट ठीक वही काम करता है जो ऊपर दी गई छवि का प्रतिनिधित्व करता है। एक जिज्ञासा के अलावा, हम computerB.recv(data) . नहीं कहते हैं . इसके बजाय, हम डेटा के स्थान पर प्रतीत होने वाली यादृच्छिक संख्या निर्दिष्ट करते हैं।
वजह साफ है। नेटवर्क पर डेटा बिट्स में प्रेषित होता है। इसलिए, जब हम कंप्यूटरबी में आरईवी करते हैं, तो हम बिट्स . की संख्या निर्दिष्ट करते हैं हम किसी एक निश्चित समय पर प्राप्त करने को तैयार हैं।
मैंने एक बार में प्राप्त करने के लिए 1024 बाइट क्यों चुने? कोई खास वजह नहीं। आमतौर पर 2 की शक्ति में आपको प्राप्त होने वाले बाइट्स की संख्या निर्दिष्ट करना सबसे अच्छा होता है। मैंने 1024 को चुना जो कि 2¹⁰ है।
तो, बफर इसे कैसे समझता है? खैर, कंप्यूटर ए बफर में जो भी डेटा संग्रहीत करता है उसे लिखता या भेजता है। कंप्यूटर बी उस बफ़र में संग्रहीत पहले 1024 बाइट्स को पढ़ने या प्राप्त करने का निर्णय लेता है।
ठीक है, कमाल! लेकिन, ये दोनों कंप्यूटर एक दूसरे से बात करना कैसे जानते हैं? उदाहरण के लिए, जब कंप्यूटर ए इस बफर को लिखता है, तो यह कैसे पता चलता है कि कंप्यूटर बी इसे लेने जा रहा है? इसे फिर से लिखने के लिए, यह कैसे सुनिश्चित कर सकता है कि दो कंप्यूटरों के बीच कनेक्शन में एक अद्वितीय बफर है?
आईपी में पोर्ट करना
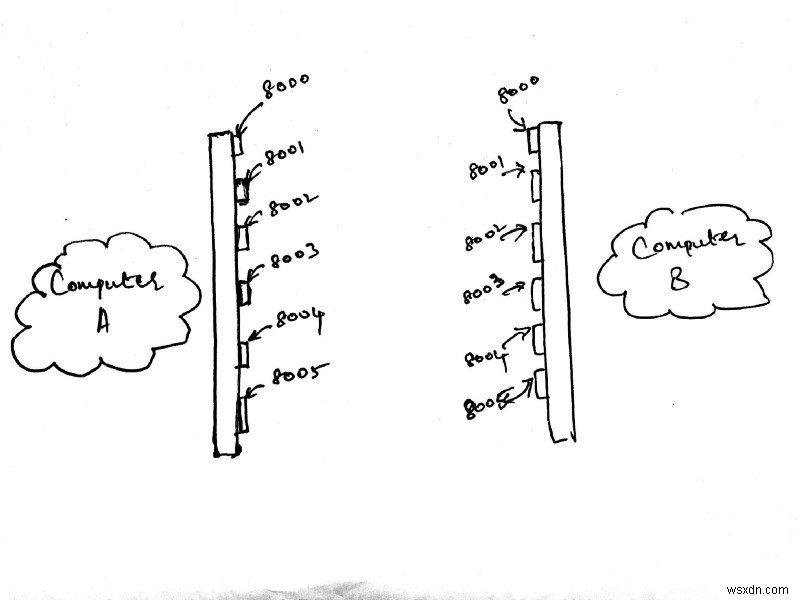
ऊपर दी गई छवि उन्हीं दो कंप्यूटरों को दिखाती है जिन पर हम काम कर रहे हैं, साथ ही एक और विवरण जोड़ा गया है। प्रत्येक कंप्यूटर के सामने एक बार की लंबाई के साथ संख्याओं का एक समूह सूचीबद्ध है।
प्रत्येक कंप्यूटर के सामने लंबे बार को राउटर मानें जो एक विशिष्ट कंप्यूटर को इंटरनेट से जोड़ता है। प्रत्येक बार पर सूचीबद्ध उन नंबरों को पोर्ट . कहा जाता है . आपके कंप्यूटर पर इस समय हजारों पोर्ट उपलब्ध हैं। प्रत्येक पोर्ट सॉकेट कनेक्शन की अनुमति देता है। मैंने ऊपर की छवि में केवल 6 पोर्ट दिखाए हैं, लेकिन आपको इसका अंदाजा हो गया है।
255 से नीचे के पोर्ट आमतौर पर सिस्टम कॉल और निम्न-स्तरीय कनेक्शन के लिए आरक्षित होते हैं। आमतौर पर 8000 की तरह उच्च 4-अंकों में एक बंदरगाह पर एक कनेक्शन खोलने की सलाह दी जाती है। मैंने ऊपर की छवि में बफर नहीं खींचा है, लेकिन आप मान सकते हैं कि प्रत्येक बंदरगाह का अपना बफर है।
बार के साथ ही एक नंबर भी जुड़ा होता है। इस नंबर को आईपी एड्रेस कहा जाता है। आईपी पते के साथ जुड़े बंदरगाहों का एक समूह है। इसके बारे में निम्नलिखित तरीके से सोचें:
127.0.0.1 / | \ / | \ / | \ 8000 8001 8002बढ़िया, चलिए कंप्यूटर A और कंप्यूटर B के बीच एक विशिष्ट पोर्ट पर एक कनेक्शन स्थापित करते हैं।
# computerA.pyimport socket computerA = socket.socket() # Connecting to localhost:8000 computerA.connect(('127.0.0.1', 8000)) string = 'abcd' encoded_string = string.encode('utf-8') computerA.send(encoded_string)
यहां computerB.py . के लिए कोड दिया गया है
# computerB.py import socket computerB = socket.socket() # Listening on localhost:8000 computerB.bind(('127.0.0.1', 8000)) computerB.listen(1) client_socket, address = computerB.accept() data = client_socket.recv(2048) print(data.decode('utf-8'))ऐसा लगता है कि हम कोड के मामले में थोड़ा आगे बढ़ गए हैं, लेकिन मैं इसके माध्यम से कदम बढ़ाऊंगा। हम जानते हैं कि हमारे पास दो कंप्यूटर हैं, ए और बी। इसलिए, हमें डेटा भेजने के लिए एक और डेटा प्राप्त करने के लिए एक की आवश्यकता है।
मैंने मनमाने ढंग से A को डेटा भेजने के लिए और B को डेटा प्राप्त करने के लिए चुना है। इस लाइन में computerA.connect((‘127.0.0.1’, 8000) , मैं 127.0.0.1 के आईपी पते पर 8000 पोर्ट से कंप्यूटरए कनेक्ट कर रहा हूं।
ध्यान दें:127.0.0.1 आमतौर पर लोकलहोस्ट का अर्थ है, जो आपकी मशीन का संदर्भ देता है
फिर, कंप्यूटरबी के लिए, मैं इसे 127.0.0.1 के आईपी पते पर 8000 पोर्ट करने के लिए बाध्य कर रहा हूँ। अब, आप शायद सोच रहे हैं कि मेरे पास दो अलग-अलग कंप्यूटरों के लिए एक ही आईपी पता क्यों है।
ऐसा इसलिए है क्योंकि मैं धोखा दे रहा हूं। मैं यह प्रदर्शित करने के लिए एक कंप्यूटर का उपयोग कर रहा हूं कि आप सॉकेट का उपयोग कैसे कर सकते हैं (मैं मूल रूप से सादगी के लिए उसी कंप्यूटर से और उसी कंप्यूटर से कनेक्ट कर रहा हूं)। आम तौर पर दो अलग-अलग कंप्यूटरों में दो अलग-अलग आईपी पते होंगे।
हम पहले से ही जानते हैं कि डेटा पैकेट के हिस्से के रूप में केवल बिट्स भेजे जा सकते हैं, इसलिए हम इसे भेजने से पहले स्ट्रिंग को एन्कोड करते हैं। इसी तरह, हम कंप्यूटर B पर स्ट्रिंग को डीकोड करते हैं। यदि आप उपरोक्त दो फ़ाइलों को स्थानीय रूप से चलाने का निर्णय लेते हैं, तो computerB.py चलाना सुनिश्चित करें। पहले फाइल करें। अगर आप computerA.py चलाते हैं फ़ाइल पहले, आपको एक कनेक्शन अस्वीकृत त्रुटि मिलेगी।
ग्राहकों की सेवा करना
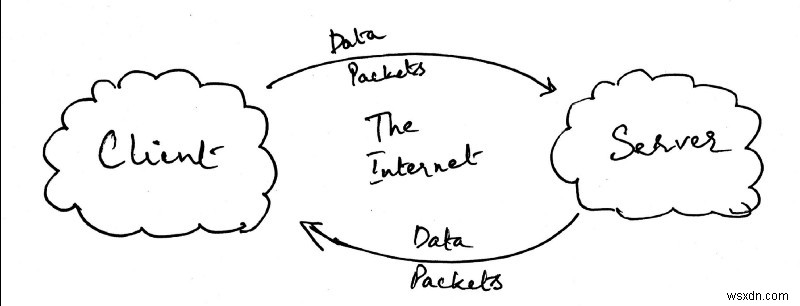
मुझे यकीन है कि आप में से कई लोगों के लिए यह बहुत स्पष्ट है कि मैं अब तक जो वर्णन कर रहा हूं वह एक बहुत ही सरल क्लाइंट-सर्वर मॉडल है। वास्तव में आप देख सकते हैं कि उपरोक्त छवि से, मैंने केवल कंप्यूटर ए को क्लाइंट के रूप में और कंप्यूटर बी को सर्वर के रूप में बदल दिया है।
क्लाइंट और सर्वर के बीच संचार का एक निरंतर प्रवाह होता है। हमारे पिछले कोड उदाहरण में, हमने डेटा ट्रांसफर के एक शॉट का वर्णन किया था। इसके बजाय, हम जो चाहते हैं वह क्लाइंट से सर्वर पर भेजे जा रहे डेटा की एक निरंतर धारा है। हालांकि, हम यह भी जानना चाहते हैं कि वह डेटा स्थानांतरण कब पूरा हो गया है, इसलिए हम जानते हैं कि हम सुनना बंद कर सकते हैं।
आइए इसे और अधिक जांचने के लिए एक सादृश्य का उपयोग करने का प्रयास करें। दो लोगों के बीच निम्नलिखित बातचीत की कल्पना करें।
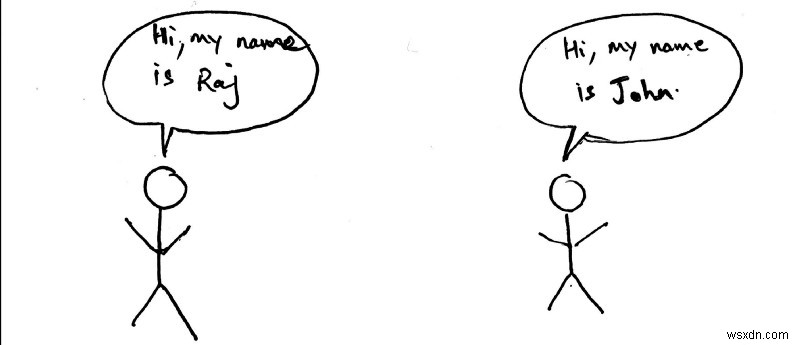
दो लोग अपना परिचय देने की कोशिश कर रहे हैं। हालांकि, वे एक ही समय में बात करने की कोशिश नहीं करेंगे। आइए मान लें कि राज पहले जाता है। जॉन तब तक प्रतीक्षा करेगा जब तक कि राज अपना परिचय देना शुरू करने से पहले अपना परिचय देना समाप्त नहीं कर देता। यह कुछ सीखे हुए अनुमानों पर आधारित है लेकिन हम आम तौर पर उपरोक्त को एक प्रोटोकॉल के रूप में वर्णित कर सकते हैं।
हमारे क्लाइंट और सर्वर को एक समान प्रोटोकॉल की आवश्यकता होती है। या फिर, उन्हें कैसे पता चलेगा कि डेटा के पैकेट भेजने की उनकी बारी है?
इसे स्पष्ट करने के लिए हम कुछ आसान काम करेंगे। मान लीजिए कि हम कुछ डेटा भेजना चाहते हैं जो स्ट्रिंग्स की एक सरणी होती है। मान लें कि सरणी इस प्रकार है:
arr = ['random', 'strings', 'that', 'need', 'to', 'be', 'transferred', 'across', 'the', 'network', 'using', 'sockets']
उपरोक्त वह डेटा है जो क्लाइंट से सर्वर पर लिखा जाने वाला है। आइए एक और बाधा बनाएं। सर्वर को उस डेटा को स्वीकार करने की आवश्यकता है जो उस स्ट्रिंग के कब्जे वाले डेटा के बराबर है जो उस पल में भेजा जा रहा है।
इसलिए, उदाहरण के लिए, यदि क्लाइंट स्ट्रिंग को 'यादृच्छिक' भेजने जा रहा है, और मान लें कि प्रत्येक वर्ण 1 बाइट पर कब्जा कर लेता है, तो स्ट्रिंग स्वयं 6 बाइट्स पर कब्जा कर लेती है। 6 बाइट तब 6*8 =48 बिट के बराबर होता है। इसलिए, क्लाइंट से सर्वर तक सॉकेट में 'रैंडम' स्ट्रिंग को स्थानांतरित करने के लिए, सर्वर को यह जानना होगा कि डेटा के उस विशिष्ट पैकेट के लिए उसे 48 बिट्स तक पहुंचना है।
समस्या को दूर करने का यह एक अच्छा अवसर है। हमें पहले कुछ बातों का पता लगाना होगा।
हम कैसे पता लगा सकते हैं कि एक स्ट्रिंग में कितने बाइट्स हैं अजगर?
ठीक है, हम पहले एक स्ट्रिंग की लंबाई का पता लगाकर शुरू कर सकते हैं। यह आसान है, यह len() पर बस एक कॉल है . लेकिन, हमें अभी भी केवल लंबाई ही नहीं, बल्कि एक स्ट्रिंग द्वारा कब्जा किए गए बाइट्स की संख्या जानने की जरूरत है।
हम पहले स्ट्रिंग को बाइनरी में बदल देंगे, और फिर परिणामी बाइनरी प्रतिनिधित्व की लंबाई का पता लगाएंगे। इससे हमें उपयोग किए गए बाइट्स की संख्या मिलनी चाहिए।
len(‘random’.encode(‘utf-8’)) हमें वह देगा जो हम चाहते हैं
हम प्रत्येक द्वारा कब्जा किए गए बाइट्स की संख्या कैसे भेजते हैं सर्वर पर स्ट्रिंग?
आसान है, हम बाइट्स की संख्या (जो एक पूर्णांक है) को उस संख्या के बाइनरी प्रतिनिधित्व में बदल देंगे, और इसे सर्वर पर भेज देंगे। अब, सर्वर स्ट्रिंग प्राप्त करने से पहले स्ट्रिंग की लंबाई प्राप्त करने की अपेक्षा कर सकता है।
सर्वर को कैसे पता चलता है कि क्लाइंट ने सभी को भेजना समाप्त कर दिया है तार?
बातचीत के सादृश्य से याद रखें, यह जानने का एक तरीका होना चाहिए कि डेटा स्थानांतरण पूरा हो गया है या नहीं। कंप्यूटर के पास अपने स्वयं के अनुमान नहीं होते हैं जिन पर वे भरोसा कर सकते हैं। इसलिए, हम एक यादृच्छिक नियम प्रदान करेंगे। हम कहेंगे कि जब हम स्ट्रिंग 'एंड' को भेजते हैं, तो इसका मतलब है कि सर्वर ने सभी स्ट्रिंग्स प्राप्त कर ली हैं और अब कनेक्शन बंद कर सकता है। बेशक, इसका मतलब है कि हम अपने सरणी के किसी अन्य भाग में बहुत अंत को छोड़कर स्ट्रिंग 'एंड' का उपयोग नहीं कर सकते हैं।
अब तक हमने जो प्रोटोकॉल तैयार किया है वह यह है:
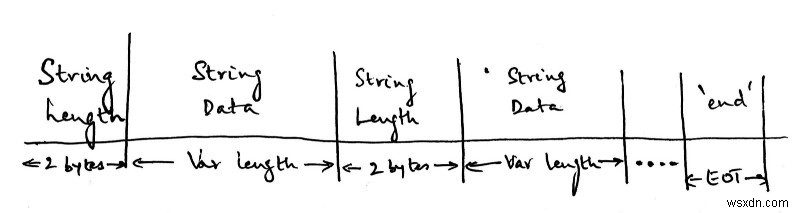
स्ट्रिंग की लंबाई 2 बाइट्स होगी, इसके बाद वास्तविक स्ट्रिंग ही होगी जो कि चर लंबाई होगी। यह पिछले पैकेट में भेजे गए स्ट्रिंग की लंबाई पर निर्भर करेगा, और हम स्ट्रिंग की लंबाई और स्ट्रिंग को भेजने के बीच वैकल्पिक करेंगे। ईओटी का मतलब ट्रांसमिशन का अंत है, और स्ट्रिंग 'एंड' भेजने का मतलब है कि भेजने के लिए और डेटा नहीं है।
नोट:इससे पहले कि हम आगे बढ़ें, मैं कुछ बताना चाहता हूं। यह एक बहुत ही सरल और बेवकूफ प्रोटोकॉल है। यदि आप देखना चाहते हैं कि एक अच्छी तरह से डिज़ाइन किया गया प्रोटोकॉल कैसा दिखता है, तो HTTP प्रोटोकॉल से आगे नहीं देखें।
आइए इसे कोड आउट करें। मैंने नीचे दिए गए कोड में टिप्पणियों को शामिल किया है, इसलिए यह स्वयं व्याख्यात्मक है।
बढ़िया, हमारे पास एक क्लाइंट चल रहा है। इसके बाद, हमें सर्वर की आवश्यकता है।
मैं उपरोक्त सार में कोड की कुछ विशिष्ट पंक्तियों की व्याख्या करना चाहता हूं। पहला, clientSocket.py . से फ़ाइल।
len_in_bytes = (len_of_string).to_bytes(2, byteorder='little')
उपरोक्त क्या करता है एक संख्या को बाइट्स में परिवर्तित करता है। to_bytes फ़ंक्शन को दिया गया पहला पैरामीटर len_of_string कनवर्ट करने के परिणाम के लिए आवंटित बाइट्स की संख्या है इसके द्विआधारी प्रतिनिधित्व के लिए।
दूसरे पैरामीटर का उपयोग यह तय करने के लिए किया जाता है कि लिटिल एंडियन प्रारूप या बिग एंडियन प्रारूप का पालन करना है या नहीं। आप इसके बारे में यहां और अधिक पढ़ सकते हैं। अभी के लिए, बस इतना जान लें कि हम उस पैरामीटर के लिए हमेशा कम ही रहेंगे।
कोड की अगली पंक्ति जिसे मैं देखना चाहता हूं वह है:
client_socket.send(string.encode(‘utf-8’))
हम ‘utf-8’ . का उपयोग करके स्ट्रिंग को बाइनरी प्रारूप में परिवर्तित कर रहे हैं एन्कोडिंग।
इसके बाद, serverSocket.py . में फ़ाइल:
data = client_socket.recv(2) str_length = int.from_bytes(data, byteorder='little')
उपरोक्त कोड की पहली पंक्ति क्लाइंट से 2 बाइट्स डेटा प्राप्त करती है। याद रखें कि जब हमने स्ट्रिंग की लंबाई को clientSocket.py . में बाइनरी प्रारूप में परिवर्तित किया था , हमने परिणाम को 2 बाइट्स में संग्रहीत करने का निर्णय लिया। यही कारण है कि हम उसी डेटा के लिए यहां 2 बाइट्स पढ़ रहे हैं।
अगली पंक्ति में बाइनरी प्रारूप को पूर्णांक में परिवर्तित करना शामिल है। byteorder byteorder . से मिलान करने के लिए यहां "छोटा" है हमने क्लाइंट पर इस्तेमाल किया।
यदि आप आगे बढ़ते हैं और दो सॉकेट चलाते हैं, तो आपको यह देखना चाहिए कि सर्वर क्लाइंट द्वारा भेजे गए स्ट्रिंग्स को प्रिंट करेगा। हमने संचार स्थापित किया!
निष्कर्ष
ठीक है, हमने अब तक काफी कुछ कवर किया है। अर्थात्, सॉकेट क्या हैं, हम उनका उपयोग कैसे करते हैं और एक बहुत ही सरल और बेवकूफ प्रोटोकॉल कैसे डिजाइन करते हैं। यदि आप सॉकेट के काम करने के तरीके के बारे में अधिक जानना चाहते हैं, तो मैं बीज की गाइड टू नेटवर्क प्रोग्रामिंग को पढ़ने की अत्यधिक अनुशंसा करता हूं। उस ई-किताब में बहुत सारी बेहतरीन चीज़ें हैं।
आप निश्चित रूप से इस लेख में अब तक जो पढ़ा है उसे ले सकते हैं, और इसे अधिक जटिल समस्याओं पर लागू कर सकते हैं जैसे रास्पबेरीपी कैमरे से छवियों को अपने कंप्यूटर पर स्ट्रीमिंग करना। इसके साथ मज़े करो!
अगर आप चाहें, तो आप मुझे ट्विटर या गिटहब पर फॉलो कर सकते हैं। आप मेरा ब्लॉग यहाँ भी देख सकते हैं। अगर आप मुझसे संपर्क करना चाहते हैं तो मैं हमेशा उपलब्ध हूं!
मूल रूप से 14 फरवरी, 2019 को https://redixhumayun.github.io/networking/2019/02/14/how-the-internet-speaks.html पर प्रकाशित हुआ।