जीएनयू/लिनक्स वितरण में टेक्स्ट को संभालने के लिए कार्यक्रमों का खजाना शामिल है, जिनमें से अधिकांश जीएनयू कोर यूटिलिटीज द्वारा प्रदान किए जाते हैं। कुछ सीखने की अवस्था है, लेकिन ये उपयोगिताएँ सही तरीके से उपयोग किए जाने पर बहुत उपयोगी और कुशल साबित हो सकती हैं।
यहां तेरह शक्तिशाली टेक्स्ट मैनिपुलेशन टूल दिए गए हैं जिन्हें प्रत्येक कमांड-लाइन उपयोगकर्ता को पता होना चाहिए।
1. बिल्ली
Cat कोबिल्ली . को पकड़ने के लिए डिज़ाइन किया गया था enate फ़ाइलें लेकिन अक्सर एक फ़ाइल को प्रदर्शित करने के लिए उपयोग किया जाता है। बिना किसी तर्क के, cat Ctrl . तक मानक इनपुट पढ़ता है + डी दबाया जाता है (टर्मिनल से या पाइप का उपयोग करते हुए किसी अन्य प्रोग्राम आउटपुट से)। मानक इनपुट को - . के साथ भी स्पष्ट रूप से निर्दिष्ट किया जा सकता है ।
Cat के पास कई उपयोगी विकल्प हैं, विशेष रूप से:
-Aप्रत्येक पंक्ति के अंत में "$" प्रिंट करता है और कैरेट नोटेशन का उपयोग करके गैर-मुद्रण वर्ण प्रदर्शित करता है।-nसभी पंक्तियों की संख्या।-bसंख्या रेखाएँ जो रिक्त नहीं हैं।-sरिक्त पंक्तियों की एक श्रृंखला को एक रिक्त पंक्ति में कम कर देता है।
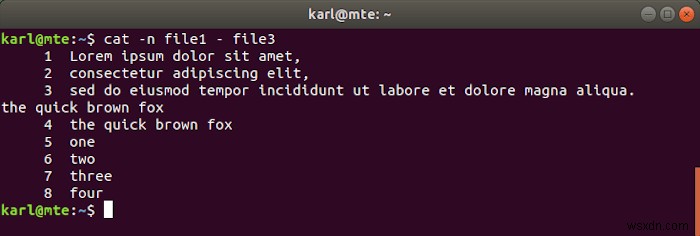
निम्नलिखित उदाहरण में, हम फ़ाइल1, मानक इनपुट, और फ़ाइल3 की सामग्री को संयोजित और क्रमांकित कर रहे हैं।
cat -n file1 - file3
2. क्रमबद्ध करें
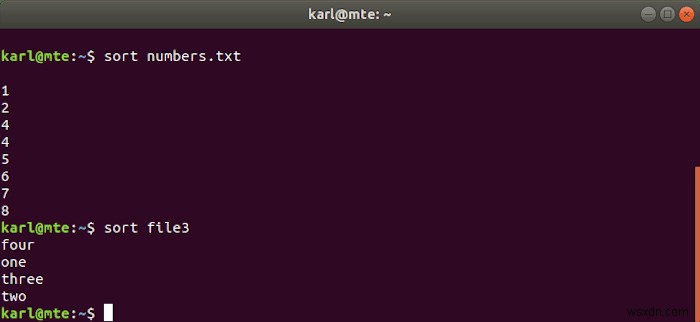
जैसा कि इसके नाम से पता चलता है, sort फ़ाइल सामग्री को वर्णानुक्रम और संख्यात्मक रूप से क्रमबद्ध करता है।
3. यूनीक
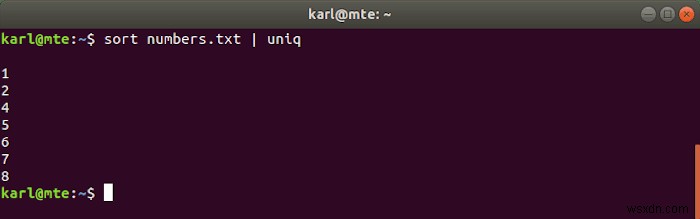
Uniq एक सॉर्ट की गई फ़ाइल लेता है और डुप्लिकेट लाइनों को हटा देता है। इसे अक्सर sort . के साथ जंजीर से बांधा जाता है एक ही कमांड में।
4. कॉम
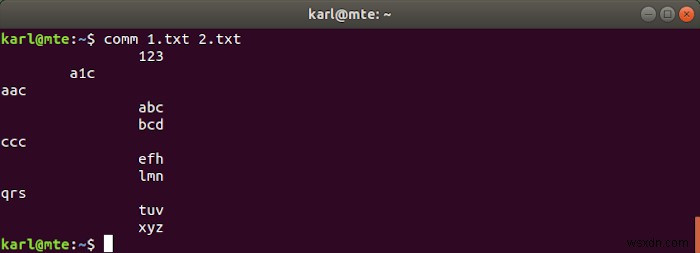
कॉम का उपयोग दो क्रमबद्ध फाइलों की तुलना करने के लिए किया जाता है, लाइन से लाइन। यह तीन कॉलम आउटपुट करता है:पहले दो कॉलम में क्रमशः पहली और दूसरी फाइल के लिए अद्वितीय लाइनें होती हैं, और तीसरा दोनों फाइलों में पाए जाने वाले को प्रदर्शित करता है।
5. कट
कट का उपयोग वर्णों, फ़ील्ड या बाइट्स के आधार पर लाइनों के विशिष्ट अनुभागों को पुनः प्राप्त करने के लिए किया जाता है। यदि कोई फ़ाइल निर्दिष्ट नहीं है तो यह फ़ाइल से या मानक इनपुट से पढ़ सकता है।
चरित्र की स्थिति से काटना
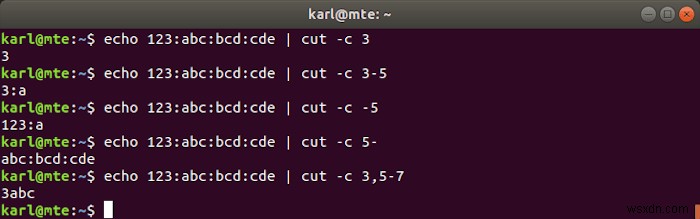
-c विकल्प एकल वर्ण स्थिति या वर्णों की एक या अधिक श्रेणी निर्दिष्ट करता है।
उदाहरण के लिए:
-c 3:तीसरा चरित्र।-c 3-5:3 से 5वें वर्ण तक।-c -5या-c 1-5:1 से 5वें वर्ण तक।-c 5-:5वें वर्ण से पंक्ति के अंत तक।-c 3,5-7:तीसरा और 5वें से 7वें वर्ण तक।
फ़ील्ड के अनुसार काटना
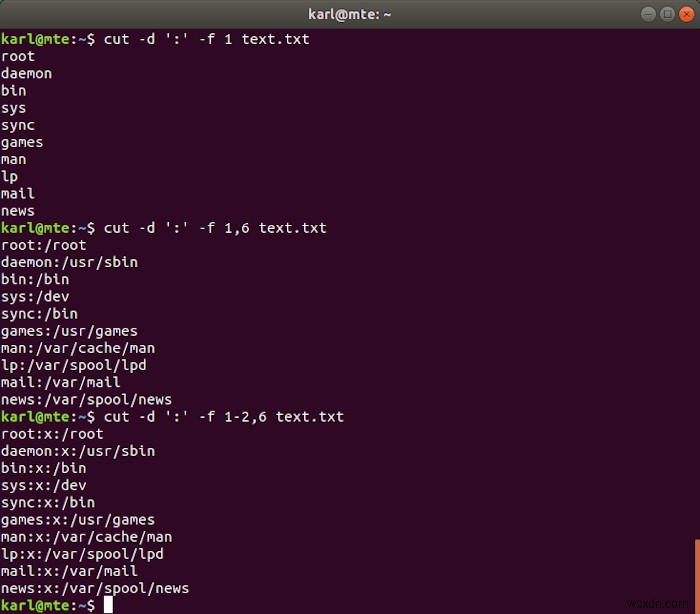
फ़ील्ड को एक एकल वर्ण वाले एक सीमांकक द्वारा अलग किया जाता है, जिसे -d के साथ निर्दिष्ट किया जाता है विकल्प। -f विकल्प एक फ़ील्ड स्थिति या ऊपर के समान प्रारूप का उपयोग करके फ़ील्ड की एक या अधिक श्रेणियों का चयन करता है।
6. डॉस2यूनिक्स
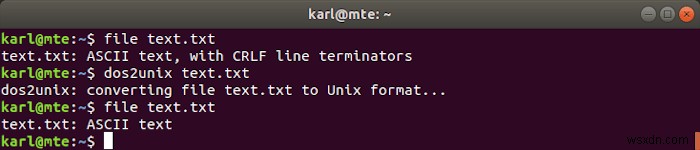
जीएनयू/लिनक्स और यूनिक्स आमतौर पर लाइन फीड (एलएफ) के साथ टेक्स्ट लाइनों को समाप्त करते हैं, जबकि विंडोज कैरिज रिटर्न और लाइन फीड (सीआरएलएफ) का उपयोग करता है। Linux पर CRLF टेक्स्ट को हैंडल करते समय संगतता समस्याएँ उत्पन्न हो सकती हैं, जहाँ dos2unix आता है। यह CRLF टर्मिनेटर को LF में परिवर्तित करता है।
निम्नलिखित उदाहरण में, file dos2unix . का उपयोग करने से पहले और बाद में टेक्स्ट फॉर्मेट की जांच करने के लिए कमांड का उपयोग किया जाता है ।
7. गुना
पाठ की लंबी पंक्तियों को पढ़ने और संभालने में आसान बनाने के लिए, आप fold . का उपयोग कर सकते हैं , जो लाइनों को एक निर्दिष्ट चौड़ाई में लपेटता है।
फोल्ड डिफ़ॉल्ट रूप से निर्दिष्ट चौड़ाई से सख्ती से मेल खाता है, जहां आवश्यक हो शब्दों को तोड़ता है।
fold -w 30 longline.txt
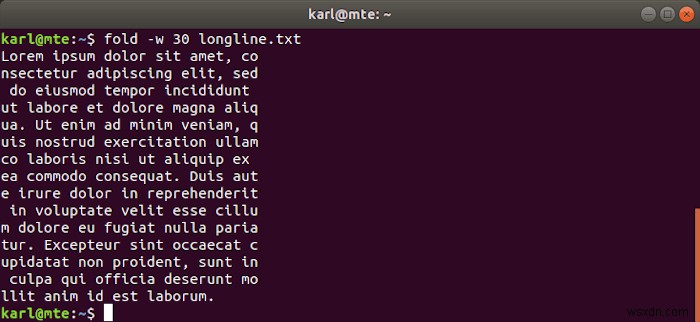
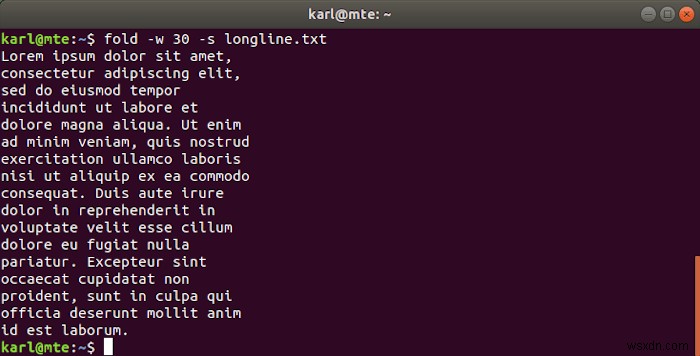
यदि शब्दों को तोड़ना अवांछनीय है, तो आप -s . का उपयोग कर सकते हैं रिक्त स्थान पर तोड़ने का विकल्प।
fold -w 30 -s longline.txt
8. आइकनव
यह टूल टेक्स्ट को एक एन्कोडिंग से दूसरे एन्कोडिंग में कनवर्ट करता है, जो असामान्य एन्कोडिंग के साथ काम करते समय बहुत उपयोगी होता है।
iconv -f input_encoding -t output_encoding -o output_file input_file
- “input_encoding” वह एन्कोडिंग है जिससे आप कनवर्ट कर रहे हैं।
- “output_encoding” वह एन्कोडिंग है जिसमें आप कनवर्ट कर रहे हैं।
- “output_file” वह फ़ाइल नाम है जिसे iconv में सहेजा जाएगा।
- “input_file” वह फ़ाइल नाम है जिसे iconv से पढ़ा जाएगा।
नोट: आप उपलब्ध एन्कोडिंग को iconv -l . के साथ सूचीबद्ध कर सकते हैं
9. सेड
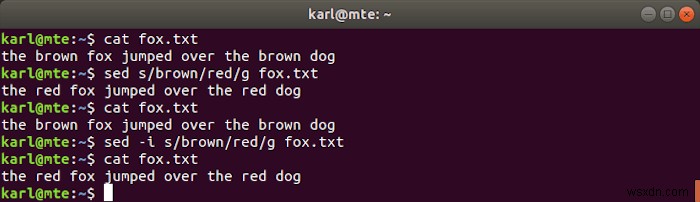
sed एक शक्तिशाली और लचीला s . है ट्रीम एड itor, आमतौर पर निम्नलिखित सिंटैक्स के साथ स्ट्रिंग्स को खोजने और बदलने के लिए उपयोग किया जाता है।
निम्न आदेश निर्दिष्ट फ़ाइल (या मानक इनपुट) से पढ़ेगा, पाठ के उन हिस्सों को प्रतिस्थापित करेगा जो प्रतिस्थापन स्ट्रिंग के साथ नियमित अभिव्यक्ति पैटर्न से मेल खाते हैं और परिणाम को टर्मिनल पर आउटपुट करते हैं।
sed s/pattern/replacement/g filename
इसके बजाय मूल फ़ाइल को संशोधित करने के लिए, आप -i . का उपयोग कर सकते हैं झंडा।
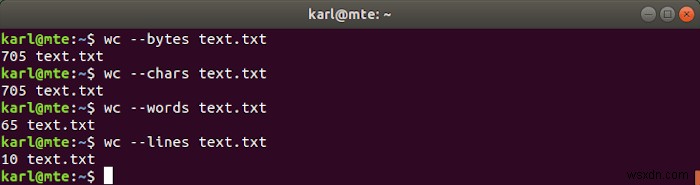
 <एच2>10. डब्ल्यूसी
<एच2>10. डब्ल्यूसी
wc उपयोगिता फ़ाइल में बाइट्स, वर्णों, शब्दों या पंक्तियों की संख्या को प्रिंट करती है।
11. विभाजित करें
आप split . का उपयोग कर सकते हैं फ़ाइल को छोटी फ़ाइलों में विभाजित करने के लिए, पंक्तियों की संख्या के अनुसार, आकार के अनुसार, या फ़ाइलों की एक विशिष्ट संख्या के अनुसार।
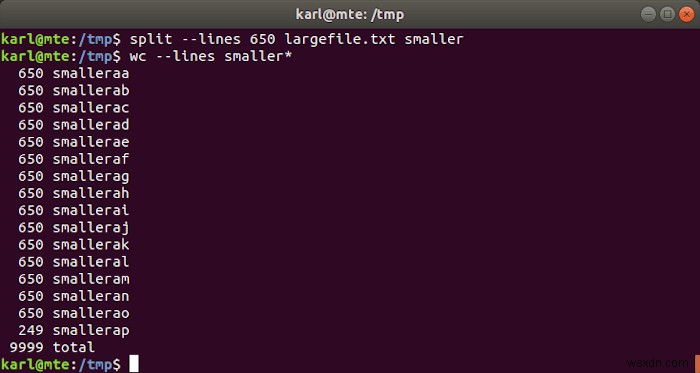
पंक्तियों की संख्या से विभाजित करना
split -l num_lines input_file output_prefix
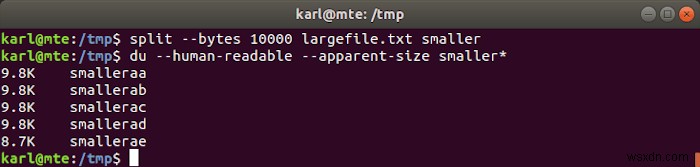
बाइट्स द्वारा विभाजित करना
split -b bytes input_file output_prefix
फ़ाइलों की एक विशिष्ट संख्या में विभाजित करना
split -n num_files input_file output_prefix

12. टीएसी
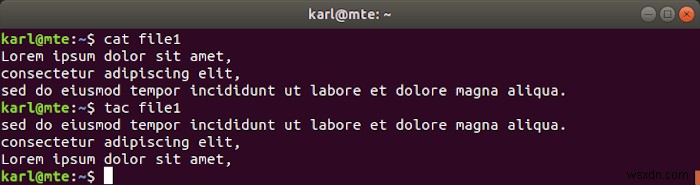
टीएसी, जो कि कैट इन रिवर्स है, ठीक यही करता है:यह फाइलों को रिवर्स ऑर्डर में लाइनों के साथ प्रदर्शित करता है।
13. टीआर
tr टूल का उपयोग वर्णों के सेट का अनुवाद करने या हटाने के लिए किया जाता है।
वर्णों का एक सेट आमतौर पर या तो एक स्ट्रिंग या वर्णों की श्रेणी होता है। उदाहरण के लिए:
- “A-Z”:सभी बड़े अक्षर
- “a-z0-9”:छोटे अक्षर और अंक
- “\n[:punct:]”:न्यूलाइन और विराम चिह्न
अधिक विवरण के लिए tr मैनुअल पेज देखें।
एक सेट का दूसरे सेट में अनुवाद करने के लिए, निम्न सिंटैक्स का उपयोग करें:
tr SET1 SET2
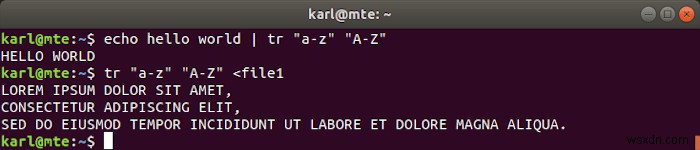
उदाहरण के लिए, लोअरकेस वर्णों को उनके अपरकेस समकक्ष से बदलने के लिए, आप निम्न का उपयोग कर सकते हैं:
tr "a-z" "A-Z"
वर्णों के समूह को हटाने के लिए, -d . का उपयोग करें झंडा।
tr -d SET

वर्णों के समूह के पूरक को हटाने के लिए (अर्थात सेट को छोड़कर सब कुछ), -dc का उपयोग करें ।
tr -dc SET

निष्कर्ष
जब लिनक्स कमांड लाइन की बात आती है तो सीखने के लिए बहुत कुछ है। उम्मीद है, उपरोक्त कमांड आपको कमांड लाइन में टेक्स्ट से बेहतर तरीके से निपटने में मदद कर सकते हैं।